国产大模型形势一片大好美国大模型出了什么问题?美国人都感觉不对劲了
1. 最近学习了大模型技术路线,很有意思。中国和美国技术路线差异很大,针尖对麦芒了。这事影响极大,几乎是全球经济最大看点之一了,大模型到底要怎么发展,AI泡沫怎么回事。
2. 美国大模型很贵,顶级大模型输出百万Token要30-50美元。跑个任务1亿token常见,好几千美元没了,财大气粗的美国公司都纷纷收紧权限。中国头部大模型最贵的也只有美国五分之一,便宜的二十分之一,已经成为现实经济选择,海外业界在考虑常规使用了。如用中国大模型生成海量代码,让美国大模型review。
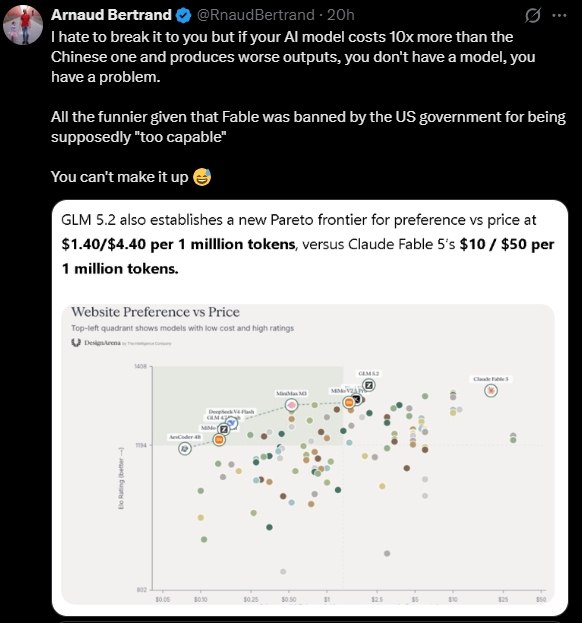
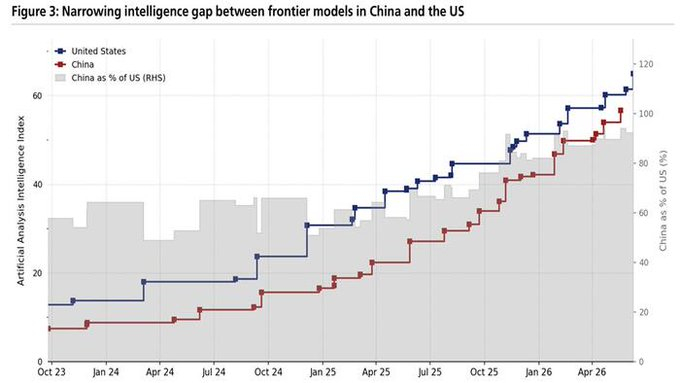
3. 美国东西卖得贵,一般觉得是品牌价值,苹果手机等产品净利润率高。但token卖天价还是赔本卖,确实成本比中国token高得多。有点类似德国坦克性能好但成本贵,苏联T34成本低海量生产,最后消灭了德国。现在美国业界、资本市场觉得不太对劲了,开始认真评估中美大模型路线的成本差异。图一是KOL发现中国大模型性能接近但只有1/7到1/10的价格,要是DeepSeek V4价格不到百分之一。图二瑞银报告,对比中国与美国大模型在训练和推理两个维度的效率差异。图三是中美模型性能差距,中国用更少算力、更低成本、更小参数规模,快速逼近美国前沿模型水平。
4. 这事不是中国人在忽悠,是美国人自己发现不对劲了。中国人只是不断开源、打榜、给出低价,别的宣传并不多。美国人就一堆炒作,性能太强不敢公布、禁止外国人用、人类危险。这回是真出问题,美国人AI故事出现漏洞了,在想为什么。
5. 美国大模型成本高,完全可以从技术上解释。Claude连MoE都不用,Dense架构推理时激活全部参数(MoE只激活几十分之一的参数),成本更高、但输出稳定性更强。但美国别家还是用MoE的,但技术路线和中国最大区别是“稀疏注意力”。中国几家全有DeepSeek Sparse Attention(DSA)这样的注意力机制绝活,每家都有发明,特点是稀疏。原始注意力机制,n个token,要互相建立n*n个注意力,到100万上下文,代价高得惊人,光这一个矩阵就要1万亿个单元,是存储爆炸的关键因素。中国公司全都极致优化,不重要的注意力不要了,最后是O(n)级别的注意力,存储需求下降了几十倍。这会有点性能下降,但可以接受,带来的成本优势很大。还有别的多个优化大招,图二总结了。
6. 现在情况是,美国大模型存储需求爆炸了,而存储公司乐得赚钱不愿意扩产。虽然存储股大涨,但这对AI行业整体发展是不利的。随便一算就知道各家公司肯定受不了,所谓的“KV cache”需求会多到爆炸。唯一的选择就是模仿中国走存储需求低的“稀疏注意力”路线。当然不是抄中国的,各家会有自己选择。
7. 美国大模型之前一直用Dense Attention,是因为财大气粗,说Sparse降性能不用。缺卡买卡、缺内存加价买内存,还抢上了,英伟达和三星、海力士成了最大受益者。但现在七巨头都觉得钱不够了,业界正发现,美国大模型走错路了,要改到稀疏路线。必须接受一些性能下降,不然太贵卖不动,商业模式会崩。但这个方向,美国就没什么优势了,等于和中国比谁生产便宜,搞成这样不能看好了。