国产大模型形势一片大好,软硬件全面突破,已经能摸到美国最前沿水平了
1. 为什么最近国产大模型成绩不断?是有积累,不是2022年末ChatGPT火了以后临时上,那不可能追上,就和全球许多“科研大国”一样。我前段时间了解了人工智能学者黄铁军,发现北京“智源研究院”很厉害,现在中国大模型不少都和它有渊源。
2. 群众一般以为OpenAI是2022年末突破的,其实不是。2020年就引发业内关注了,核心突破是GPT3.0。当时智源研究院就搞了对标的“悟道”大模型,2.0版甚至有万亿参数,非常超前了,怎么做大模型都知道了。后面社会上火了,都来投大模型,核心开发人员是有经验的,不是从头摸索。
3. 而且中国搞大模型很不一样,很重视国产软硬件体系。华为昇腾芯片早在2018年就弄出来了,很神奇。2013 年 华为启动 AI 领域前瞻布局,开始规划专用 AI 处理器。2018 年10 月,华为首次发布并实体展示昇腾310,预告昇腾910上市。2019年8月,昇腾 910正式商用发布,FP16 算力256TFLOPS,同期推出MindSpore框架(对标Pytorch),全栈自主可控理论上可以了,那时还没大模型。现在昇腾芯片会成为华为极为可观的营收,2000亿一年都看得到了。后面先进芯片制造产能突破,华为AI芯片业务万亿收入只是基本,更高都能想,这是一个确定的方向。
4. 后面科大讯飞一直用华为体系做训练,非常艰苦。但确实搞通了,推出了GPT3、GPT4水平的国产大模型,全栈自主。2024 年9月,科大讯飞在华为全联接大会上表示:“基于昇腾 AI 基础软硬件打造的'飞星一号'平台,已经常态化高效支撑讯飞星火大模型训练……完全基于昇腾算力原生开发训练的星火 V4.0,在国内外中英文12项主流测试集中有 8 项超过 GPT-4 Turbo。”
5. 星火大模型是目前唯一可以确认的“全栈自主”国产大模型,训练都是,其它都是说推理适配国产芯片。还可以确认的是,DeepSeek V4在“后训练”阶段,一些压力比“预训练”小的训练任务(这种任务有上百种),用了昇腾芯片。图中说GLM5.1用了10万块昇腾910B训练,这应该是爱好者谣传。再如 glm-5.org 这类网站也说训练用华为平台全栈自主,其实是爱好者建的,不是官网。但昇腾芯片用来做训练是可以的,就是需要时间适配,相信各家都在努力,一定会成功。
6. 最近几个大事,DeepSeek V4、Kimi K2.7、GLM 5.2纷纷推出。有的评测说性能只落后Claude Fable,和Claude Opus 4.8持平了,马斯克猜测2027年Q1追平Fable,开发者说2026年就行。情况应该是,GLM 5.2在Agent相关指标上,追上了Opus 4.8,但全面指标还不如。而DeepSeek V4在另一些指标上追平,Kimi K2.7也有些编程指标达到最前沿水平了。
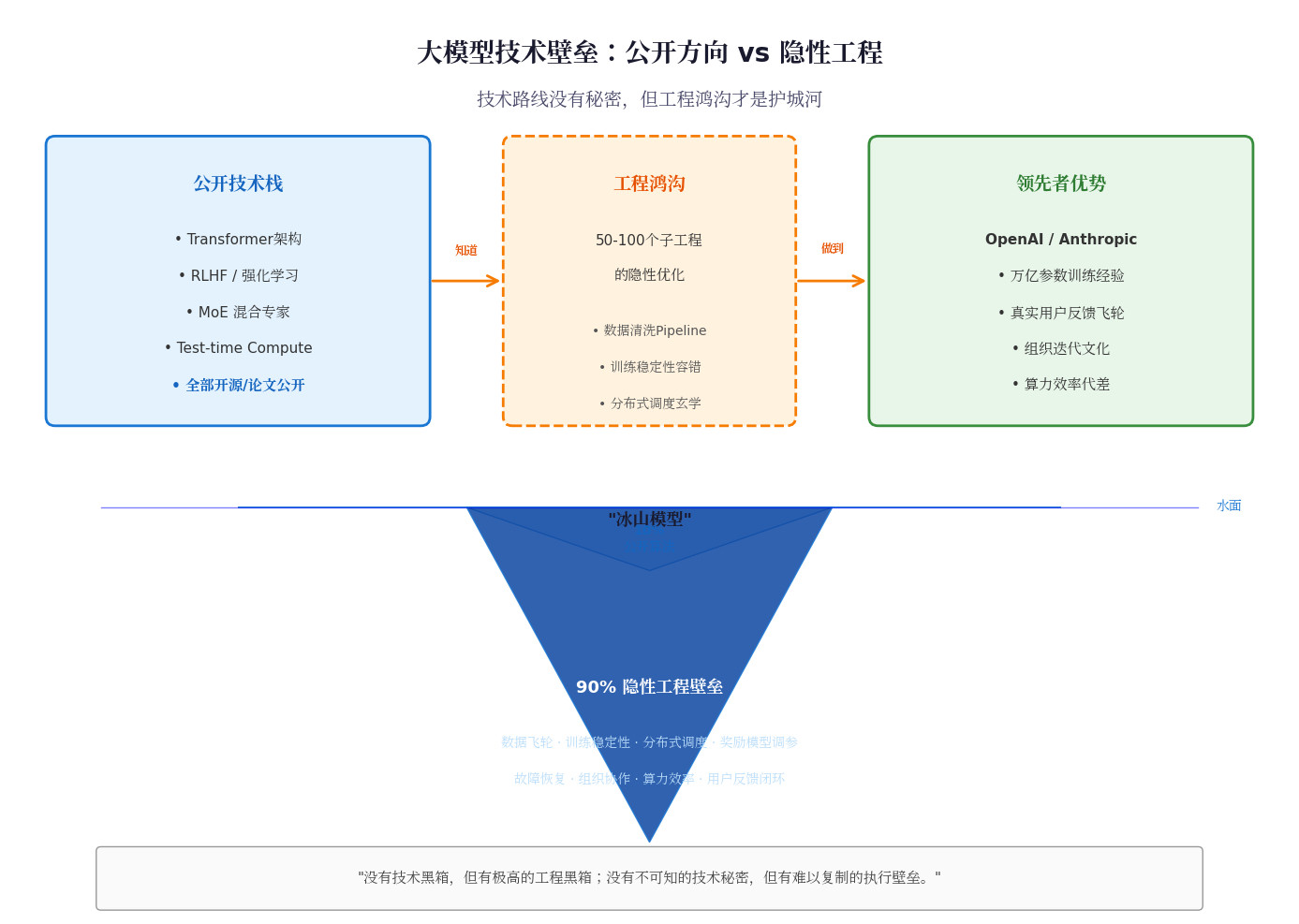
7. 这些国产大模型统一的特征是,定价便宜,计算效率非常高,都用了不少DeepSeek开源的高效率体系,互相也有贡献。我看技术细节的感觉是,用高效数据结构与算法,非常省算力资源,而且并不会卡住。Claude真正牛的并不是算力,而是一套AI编程的Harness开发框架,用于大模型自我迭代了,开发明显提速。所以Anthropic大搞神秘主义,反而导致Fable被禁用。其实没什么,无非就是有了海量的Agent使用实例,以及AI自己能生成Agent相关训练样本,各种复杂的细节都有人做好了技术底座。AI自己写自己的代码没什么神秘的,懂程序开发就明白怎么回事。现在国产大模型也摸通了这条路,AI开始自己写代码、生成样例,加速迭代了。
8. 总体来说,中国大模型追赶的速度非常好,进展比我预期的要强。美国方面已经很有压力了,据说微软都想用DeepSeek V4高低配降低token成本。只要国产开源大模型一直进步,美国想靠大模型赚大钱是不可能的。中国搞AI的人很多很厉害,美国AI没有技术秘密了。