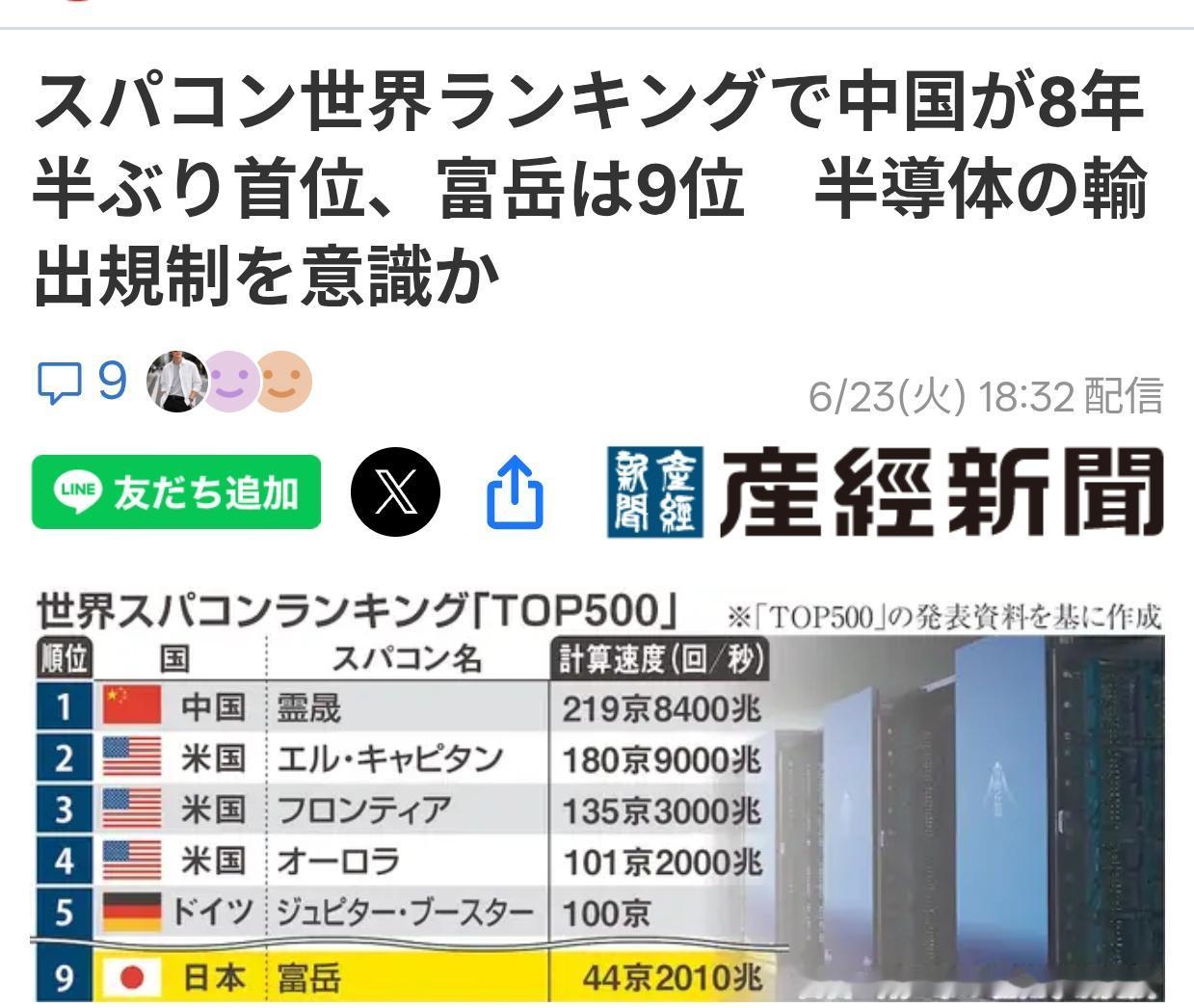
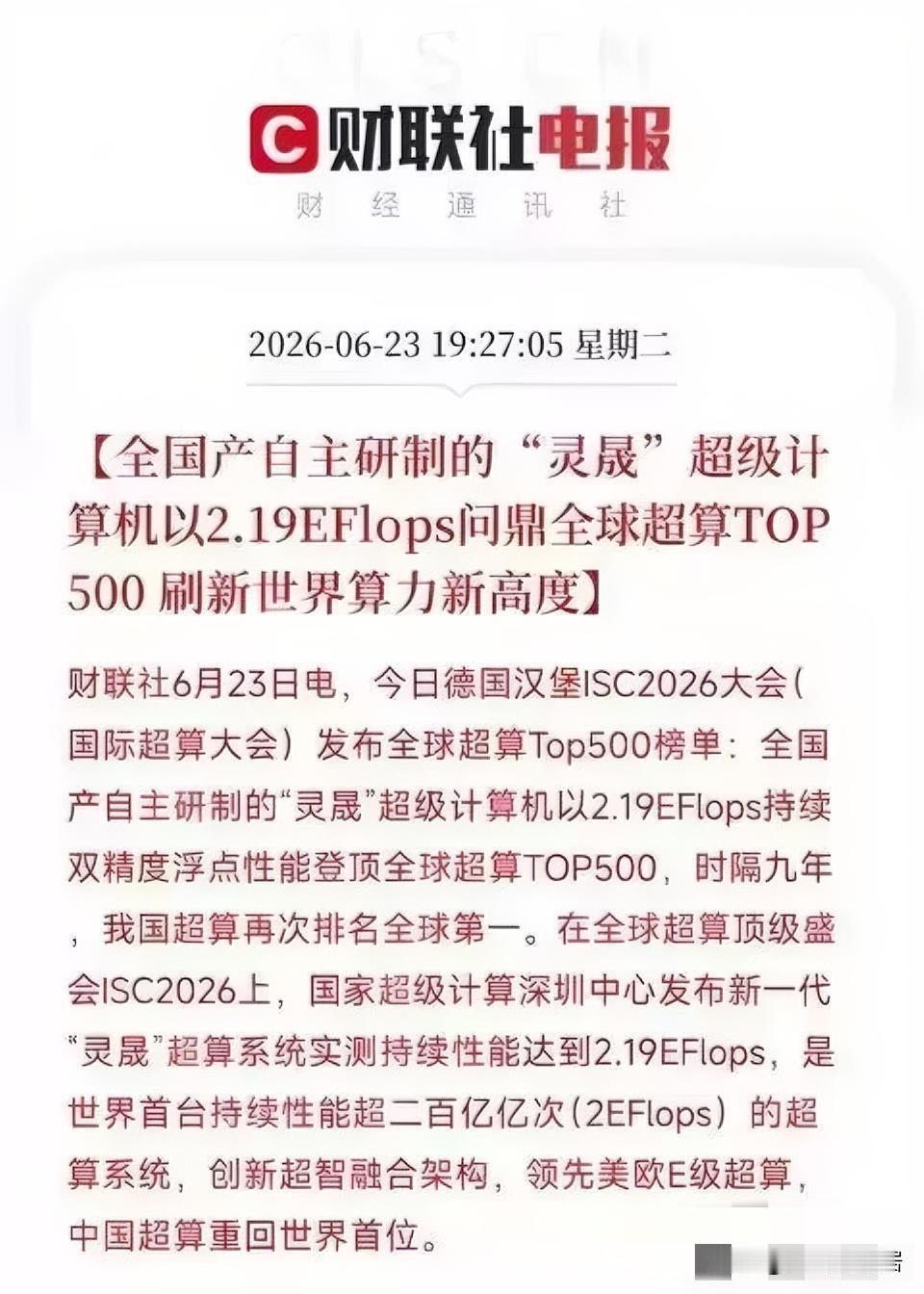
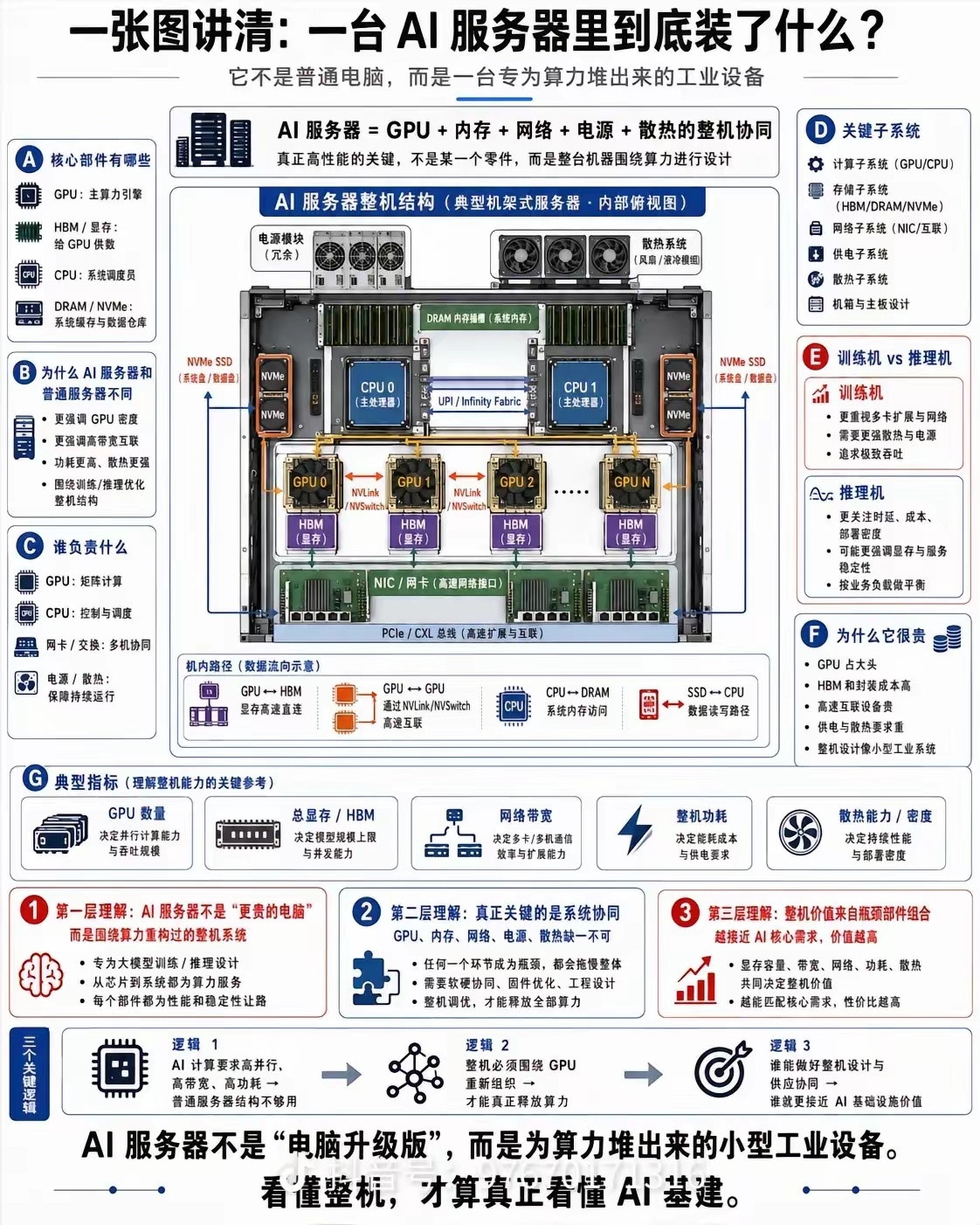
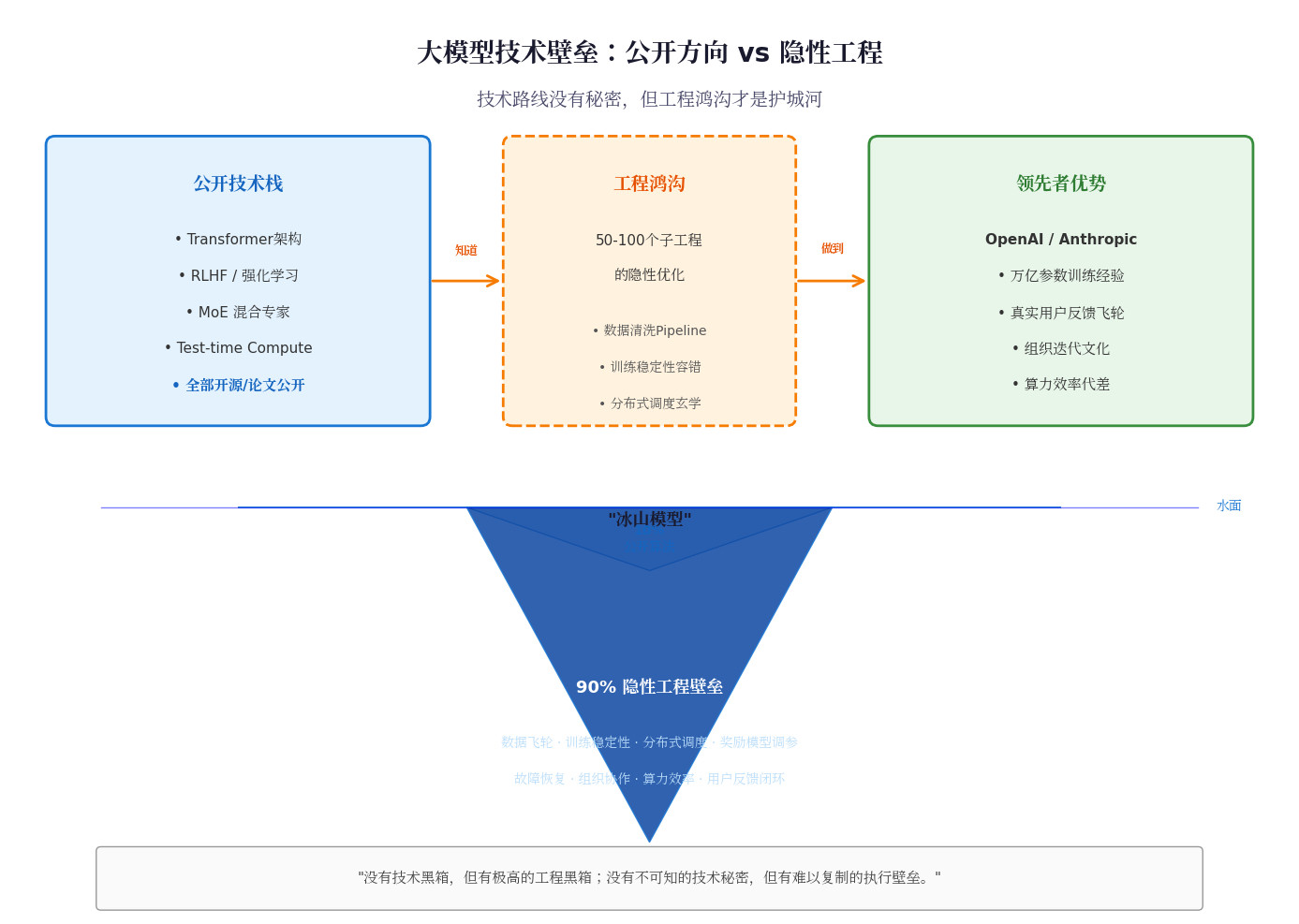
标签: GPU



夜深了,证监会大动作,央行万亿拟回购,下周A股观点来了!一、热点解读①证监会征求
夜深了,证监会大动作,央行万亿拟回购,下周A股观点来了!一、热点解读①证监会征求意见:在拟融资规模不超过净资产20%的前提下沪深交易所上市公司小额快速融资上限从3亿元提升至6亿元。利好A股,特别是科技股和券商。②三部门:调整节能汽车、新能源汽车车船税优惠政策。调整节能汽车、新能源汽车车船税优惠政策。③上游原材料采购成本明显提升充电模块集体涨价15%。④摩根大通:大模型使用与GPU租赁价格齐升AI基建需求仍获支撑。⑤德银:Meta云业务或打开千亿美元级AI投入变现通道。⑥7月6日(下周一)开展1万亿元3个月买断式逆回购,当月到期8000亿,净投放2000亿,终结连续3个月流动性缩量回二、关于A股①今天晚上美股休息,晚间的消息利好比较多,央行的利好消息,释放了流动性,所以A股很难大跌。②利好板块1:AI算力硬件链,Meta/摩根大通验证海外资本开支;充电模块涨价印证半导体产能紧缺;所以继续看好③利好板块2:头部券商流动性宽松利好自营与两融;再融资新规直接增厚投行收入。④利好板块3:充电桩+储能细分:充电模块涨价修复企业利润。⑤对于下周A股,我的观点还是震荡。先反弹后下跌!


















美团投资的AI独角兽公司一、通用大模型独角兽1. 智谱AI(清华系大模型龙头)
美团投资的AI独角兽公司一、通用大模型独角兽1.智谱AI(清华系大模型龙头)美团战略入股,持股约5.54%,投前估值200亿元,国内头部通用大模型2.月之暗面(Kimi母公司)美团A1轮领投,最新估值超200亿美元,长文本大模型标杆,Kimi为国民级AI工具。3.光年之外美团20.65亿元全资收购(王慧文创办),初创即达2亿美元估值,AGI技术团队并入美团自研大模型LongCat。二、具身智能/机器人独角兽1.宇树科技(Unitree)美团第一大外部股东(持股9.65%),四足/人形机器人龙头,2026年科创板IPO过会,IPO估值420亿元。2.银河通用机器人美团天使轮领投、最大外部股东(持股15%),通用人形机器人Galbot落地药店自动分拣,估值210亿。3.普渡科技多轮大额参投,商用送餐机器人龙头,服务机器人赛道独角兽。4.星海图、自变量机器人美团联合/独家领投,专攻具身大模型(机器人大脑),单家估值破百亿,国内端到端通用机器人底座厂商。三、国产GPU/算力芯片AI独角兽1.摩尔线程国产桌面GPU龙头,美团早期投资,上市首日市值破3000亿。2.沐曦股份通用AI训练GPU独角兽,美团布局算力底层,对标英伟达A/H100。3.紫光展锐、爱芯元智AI边缘计算、车载芯片独角兽,美团布局终端AI算力。美团8年累计投资28家AI独角兽、43家硬科技企业,7家已完成上市。


从龙芯到GPU!唐志敏54岁再创业,为何总挑最硬的骨头啃?当全网吹捧“芯片
从龙芯到GPU!唐志敏54岁再创业,为何总挑最硬的骨头啃?当全网吹捧“芯片英雄”时,谁看见唐志敏孤注一掷的狠劲?54岁本可退休,他却砸声誉、赌融资,在GPU赛道硬刚英伟达——这哪是创业?分明是拿命填中国芯片最后的窟窿!第一,他专挑“死局”破。从龙芯一号终结无芯史,到海光借x86弯道超车,再到现在象帝先死磕GPU,唐志敏每次都选最难的路。别人躲着国外技术封锁,他偏要正面刚:“总要有人做!”第二,人才是他唯一的赌本。甘当人梯培养团队,连下属报告都代写,换来百人死忠研发军团。融资崩盘时没人跑路,只因跟着他“把不可能变可能”。第三,54岁敢押上全部。对赌失败?裁员危机?老将偏要绝地重生。网友骂“疯子”,他却说:“国产芯片要好用,不是可用!”





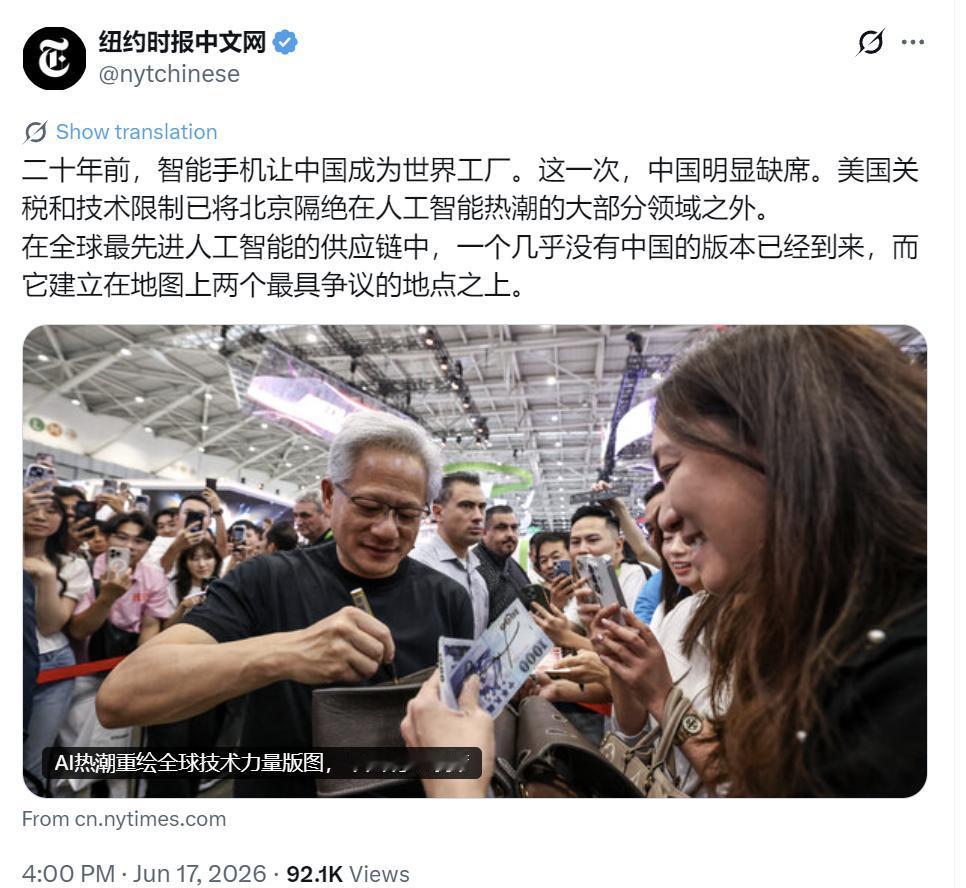
纽约时报中文网6月17日刊文:“二十年前,智能手机让中国成为世界工厂。这一次,中
纽约时报中文网6月17日刊文:“二十年前,智能手机让中国成为世界工厂。这一次,中国明显缺席。美国关税和技术限制已将北京隔绝在人工智能热潮的大部分领域之外。在全球最先进人工智能的供应链中,一个几乎没有中国的版本已经到来,而它建立在地图上两个最具争议的地点之上。”说白了,《纽约时报》6月17日刊发的这篇文章,表面拿智能手机时代的全球分工对比当下AI赛道,宣称中国被隔绝在先进AI浪潮之外、无中国的新型供应链成型,实则是站在美国单边遏制视角刻意歪曲产业现实,美化关税与芯片管制政策,完全无视中国AI全产业链自主突破的客观事实。要知道,二十年前智能手机产业阶段,中国依托完整制造体系承接终端组装、零部件加工,成为全球硬件供给核心;但人工智能是算力芯片、大模型算法、海量产业场景、数据资源结合的复合型产业,不能简单套用单一制造时代的逻辑。美国限制高端GPU对华出口确实带来短期算力阵痛,可国内早已跑出昇腾、昆仑芯等自研AI芯片,DeepSeek、智谱GLM等国产大模型性能跻身全球第一梯队,全国建成大批国产万卡智算中心,搭建起独立于美系CUDA的完整技术生态,根本不存在彻底缺席全球AI赛道的情况。其实文中所说依托两处争议区域搭建“无中国AI供应链”,是美国“小院高墙”战略的地缘算计,两处地点分别指向中国台湾地区先进芯片产能与东南亚组装基地。美方一边捆绑台积电锁定先进制程,一边扶持越南、马来西亚布局硬件代工,试图剥离大陆在高端算力硬件环节的参与。但这套布局有着天然短板,东南亚缺少完整半导体配套、高端研发人才储备不足,仅能承担低端组装;台湾半导体产业又高度依赖大陆设备、材料与庞大终端订单,强行拆分产业链只会推高全球AI硬件生产成本,美欧科技企业早已多次向白宫反馈管制带来的巨额营收损失。至于文章渲染“关税与技术限制隔绝中国AI发展”,完全混淆硬件供给与产业发展两个概念。硬件层面,长鑫存储补齐存储芯片短板,国产算力芯片持续迭代缩小性能差距;软件层面国内企业研发适配国产算力的训练框架,通过模型蒸馏、算力集群堆叠弥补单芯片性能差距;应用层面更是中国核心优势,工业智能、自动驾驶、智慧城市、多模态商用AI落地规模全球第一,海量真实产业数据持续反哺算法迭代,国产AI方案持续开拓中东、东南亚、拉美海外市场,新兴市场份额稳步提升。更关键的是,强行分割全球AI产业链、打造两套平行供应链,违背全球化分工客观规律,最终只会造成双向损失。美西方搭建的脱离中国的供应链,失去全球最大AI应用市场、低成本完整制造配套,产业扩张存在明显天花板;而外部封锁反倒倒逼国内加速全链条自主可控,摆脱对海外高端芯片、EDA工具的依赖,长期形成中美两条并行发展的AI产业体系,所谓“无中国先进AI供应链”仅能覆盖欧美小众市场,无法适配绝大多数新兴经济体的成本与场景需求。要清楚,这篇报道带有极强的舆论导向目的。当下美国内部反对科技脱钩的声音持续高涨,硅谷企业、农业州、制造业纷纷抗议管制损害自身利益,《纽约时报》发布此类片面论调,是刻意渲染对华封锁取得成效,为美国鹰派科技政策制造舆论支撑,刻意回避管制刺激中国科创突破、反噬美国企业全球竞争力的真实现状,多篇美媒实地调研文章早已证实芯片遏制战略难以奏效。说到底,这篇外媒报道是单边霸权思维下的片面解读。美国关税与芯片管制只会带来短期产业阵痛,无法把中国挤出全球人工智能发展浪潮;人为搭建脱离中国的AI供应链受制于配套、成本、市场三重短板,注定难以全面落地。依靠封锁隔绝阻挡他国科技进步行不通,中美AI产业长期并行发展是大势,唯有摒弃零和对抗思维,开放合作才能释放人工智能的全球发展红利。以上是小编个人看法,如果您也认同,麻烦点赞支持!有更好的见解也欢迎在评论区留言,方便大家一同探讨。

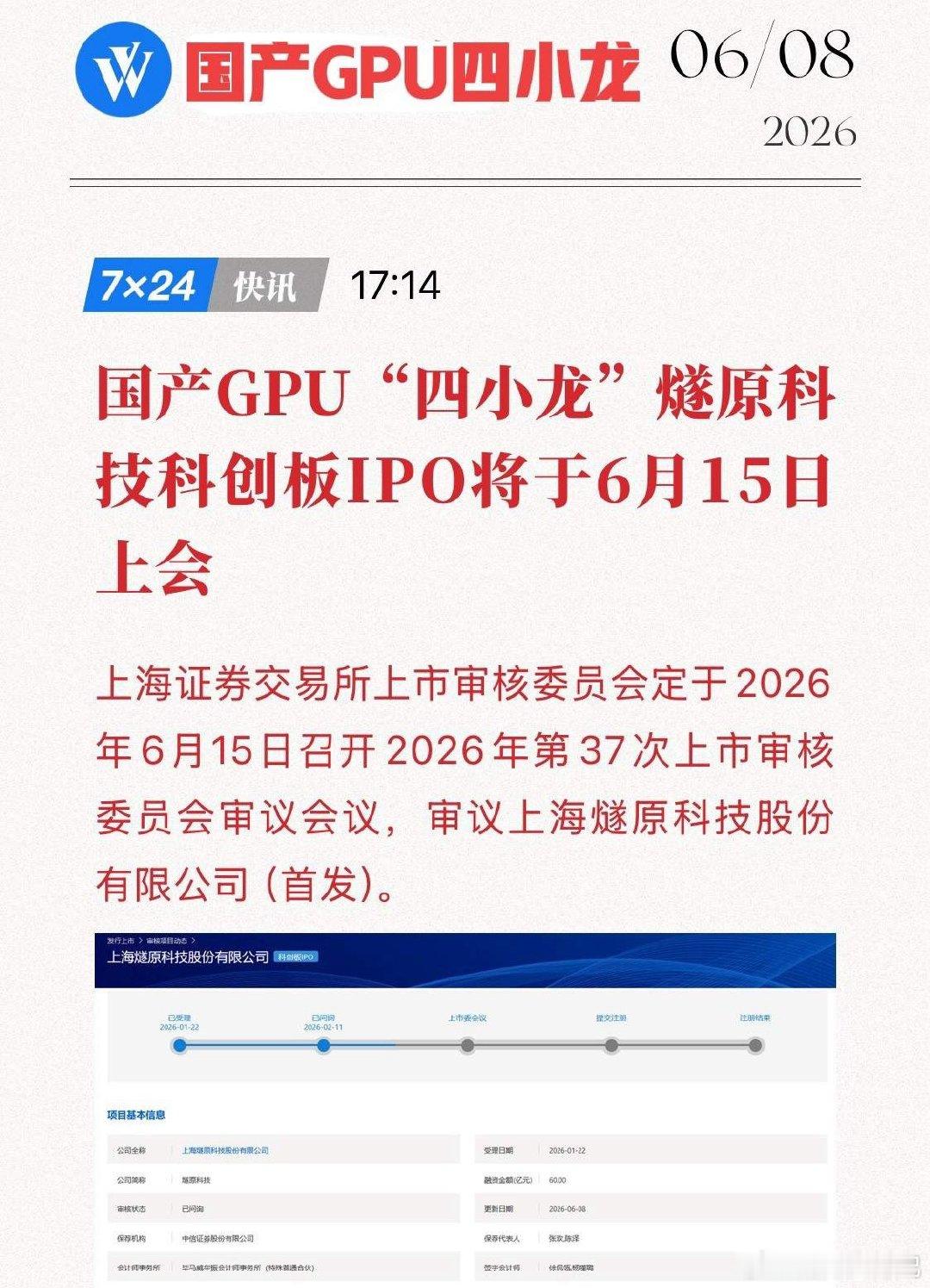
燧原科技冲刺IPO!国产GPU量产落地,整条产业链谁深度绑定吃到红利?
燧原科技冲刺IPO!国产GPU量产落地,整条产业链谁深度绑定吃到红利?

市场成交大的寒武纪:GPU涨价国瓷材料:MLCC涨价光迅科技:CPO涨价工业复联
市场成交大的寒武纪:GPU涨价国瓷材料:MLCC涨价光迅科技:CPO涨价工业复联:算力涨价兴森科技:PCB涨价蓝思科技:玻璃基板涨价中钨高新:钨、钻针涨价铜冠铜箔:PCB涨价总结下来还是PCB和CPO






这两年跟几个做金融AI的朋友聊天,发现一个挺普遍的现象:GPU采购预算批得爽快,
这两年跟几个做金融AI的朋友聊天,发现一个挺普遍的现象:GPU采购预算批得爽快,上架之后实际利用率却惨不忍睹。显卡经常在那儿"等着",数据从存储搬过来要时间,网络传过来要时间,等数据到了,计算早就跑完了——典型的"车等油"。金融智能体对这个问题的敏感度尤其高。实时反欺诈、动态授信、智能投顾,智能体要在毫秒级完成"感知-决策-执行"闭环。数据路径一拥堵,推理时延抖动,体验和风控效果一起打折。中科曙光这次在金融展上推的"元融"方案,说白了就是冲着"不让GPU空等"来的。算力是scaleX40超节点——单节点40张GPU,显存加起来5TB多,万亿参数模型能装下。存储是ParaStorF9000,单节点带宽220GB/s,能同时给40张卡各喂5GB/s以上的数据。网络是scaleFabric,端到端时延压到0.93微秒。三层拉通之后,数据不用再从存储"长途跋涉"去找算力,算力就贴着数据跑。"元融"专攻AI创新和智能体推理,当然也有FlashNexus9000专门守住核心交易。江海证券已经跑通了四大场景。大模型推理从秒级压到百毫秒级,这个提升在真实业务里体感还是挺明显的。中科曙光元融金融展

全网梳理|燧原科技IPO落地!完整国产GPU受益产业链名单✨国产AIGPU自主替
全网梳理|燧原科技IPO落地!完整国产GPU受益产业链名单✨国产AIGPU自主替代进程持续提速,燧原科技顺利过会、即将登陆科创板,作为国内头部自研算力芯片厂商,其上市落地将全面加速国产高端GPU规模化商用,带动股权绑定、服务器代工、芯片上游材料设备整条产业链进入业绩兑现周期。现将燧原科技核心受益标的,按绑定深度、受益逻辑分为三大梯队,全网清晰复盘:一、股权+业务深度绑定(弹性最强、核心受益)该梯队企业兼具股权投资收益与独家深度业务合作,跟随燧原产能扩张、订单放量,业绩与估值双向受益,是产业链核心龙头。•弘信电子:与燧原科技成立合资公司燧弘华创,独家承接燧原算力硬件落地生产,同时通过产业基金深度战略入局,是市场认可度最高的双绑定核心标的,订单确定性与业绩弹性居首。•景嘉微:国产GPU核心厂商,与燧原科技形成产业协同,共同推进国产算力芯片国产化替代,技术适配与行业落地深度绑定。•浪潮信息:深度参与燧原科技整机方案研发、服务器适配落地,是燧原算力芯片商用落地的核心整机合作方。二、智算硬件代工&算力集群建设(场景落地核心)聚焦AI服务器组装制造、万卡智算集群搭建、算力交付场景,承接燧原芯片下游落地需求,是国产算力规模化放量的直接受益环节。•深科技:具备成熟高端服务器代工产能,深度对接燧原整机量产需求,支撑算力硬件规模化交付。•润泽科技:主营大型智算中心建设与运营,参与燧原万卡算力集群落地部署,赋能AI算力商业化应用。•亿田智能:深度参与算力硬件配套及代工环节,贴合燧原下游硬件量产需求。三、芯片上游核心环节(全产业链配套)覆盖燧原AI芯片生产所需的晶圆制造、先进封装、核心设备、高纯硅片、配套芯片全上游链条,是国产GPU自主可控的底层支撑。•中芯国际:国内头部晶圆代工厂,承接燧原芯片晶圆代工业务,为芯片量产提供核心产能支撑。•长电科技:国内先进封装龙头,为燧原高端算力芯片提供封装测试服务,保障芯片性能与良率。•澜起科技:提供内存接口等核心配套芯片,适配高端服务器与算力芯片整机方案。•北方华创:半导体设备龙头,覆盖芯片制造刻蚀、沉积等核心设备环节,夯实国产芯片制造底座。•沪硅产业:高端半导体硅片供应商,为燧原芯片生产提供核心原材料保障。核心题材逻辑当前算力自主可控是市场长期主线,海外高端芯片受限背景下,燧原科技作为国产头部GPU企业,上市后将获得充足资本加持,进一步扩大自研芯片产能与市场渗透率。从上游半导体设备材料、中游芯片封装代工、下游整机服务器与算力集群,整条国产GPU产业链将持续迎来订单增量与估值修复机会,结构性行情值得持续跟踪。⚠️以上仅为公开行业信息产业链梳理,不构成任何个股买卖投资建议A股



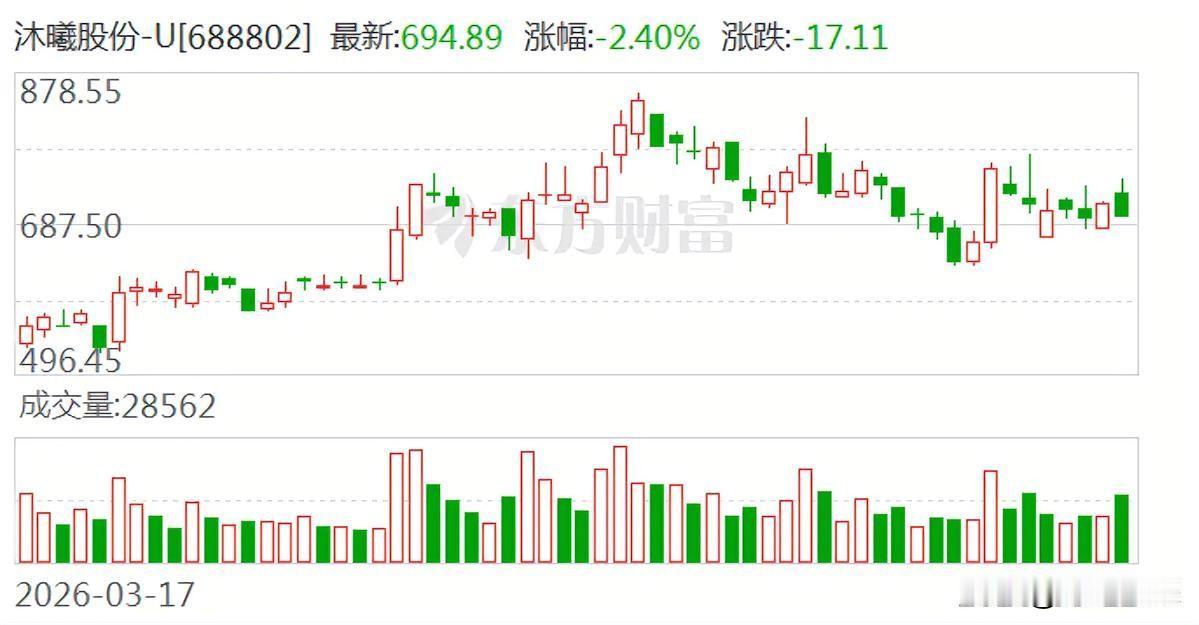
沐曦股份刚在科创板站稳脚跟,转身就直奔港交所。这家国产GPU独角兽的动作,刚
沐曦股份刚在科创板站稳脚跟,转身就直奔港交所。这家国产GPU独角兽的动作,刚好踩在AI算力由海外单一供给转向国产并存的节骨眼上,它的目的很明确,就是去拿国际资本,重注砸向下一代通用GPU和软件生态。对于还在高研发投入期、亏损收窄的沐曦来说,光靠A股显然不够解渴。搞通用GPU这事,烧钱周期长、生态壁垒高,不备足粮草很难跟得上。但还是不少人质疑,毕竟公司刚上市不久,理财还没焐热就又要融资,吃相有点难看。但这或许正是硬科技的残酷现实,不拼命砸钱迭代,技术就会掉队,想保持身位就得持续吸金。这种刚上市就再融资的激进打法,你觉得是长期主义还是急于圈钱?评论区聊聊。






AI会带来失业,也会带来更多就业机会!失业的人会拼命生存,这种生命力很强!正如当
AI会带来失业,也会带来更多就业机会!失业的人会拼命生存,这种生命力很强!正如当年直播干翻了线下零售,但也逼着更多零售商和工厂都招直播主播销售,极大的增加了就业!被迫创业潮大厂降本增效,首当其冲的是总监级中层。这批人有经验、有积蓄、有人脉,却被“逼上梁山”。不是想创业,是没得选。这种“被迫创业”与主动创业完全不同——主动创业是锦上添花,被动创业是背水一战。生存本能驱动的爆发力惊人,就像欧洲大航海:活不下去,才出海。今天的大厂裁员潮,本质上是在向全球输送一批最凶狠的创业者。00后创业者正在涌现00后的产品定义跟老一辈完全不在一个频道,天生就是AI原住民,认为AI工具就像水电一样自然。面对这种变化,VC的出手策略急剧调整——要么投极早期(1000-3000万人民币),要么投极后期,中间成长期几乎不碰。估值涨上来了,数据还没跑出来,竞品突然冒出好几个,根本没法判断谁能胜出。目前市场上形成了两套投资套路:1.完全市场化:产品好、技术领先、卖货赚钱2.国家战略:跟着政策走,投GPU、火箭、大模型、核聚变





























算力价格持续走高,正在悄然重塑所有企业的运营逻辑。💼以前创业,大家比的是谁的
算力价格持续走高,正在悄然重塑所有企业的运营逻辑。💼以前创业,大家比的是谁的PPT更性感、谁的获客成本(CAC)更低;现在AI创业,大家第一步先看你的“算力账本”。不少雄心勃勃的AI初创公司,还没等到产品大规模变现,就已经被每个月高昂的云服务和算力租赁账单压得喘不过气来。这迫使整个行业从“唯模型论”转向“唯效率论”。堆参数的暴力美学玩不起了,企业必须在有限的预算里,精细化压榨每一块GPU的剩余价值。很多公司开始放弃全能大模型,转向垂直领域的“小快灵”微调模型,甚至开始把目光投向“端侧算力”——让用户的手机和电脑去分担一部分计算压力。在这场前所未有的结构性上涨中,算力已经成为企业资产负债表上最不容忽视的变量。算力焦虑,已经从技术总监的电脑屏幕,蔓延到了CEO和CFO的办公桌上。
