英伟达H200:为AI推理而生的“显存巨兽”
2023年底,英伟达在H100发布一年后,悄然推出了Hopper架构的继任者——H200。它没有改变核心算力,却凭借显存子系统的革命性升级,成为大模型推理时代最具性价比的高端GPU。
一、核心规格:算力未变,显存大增
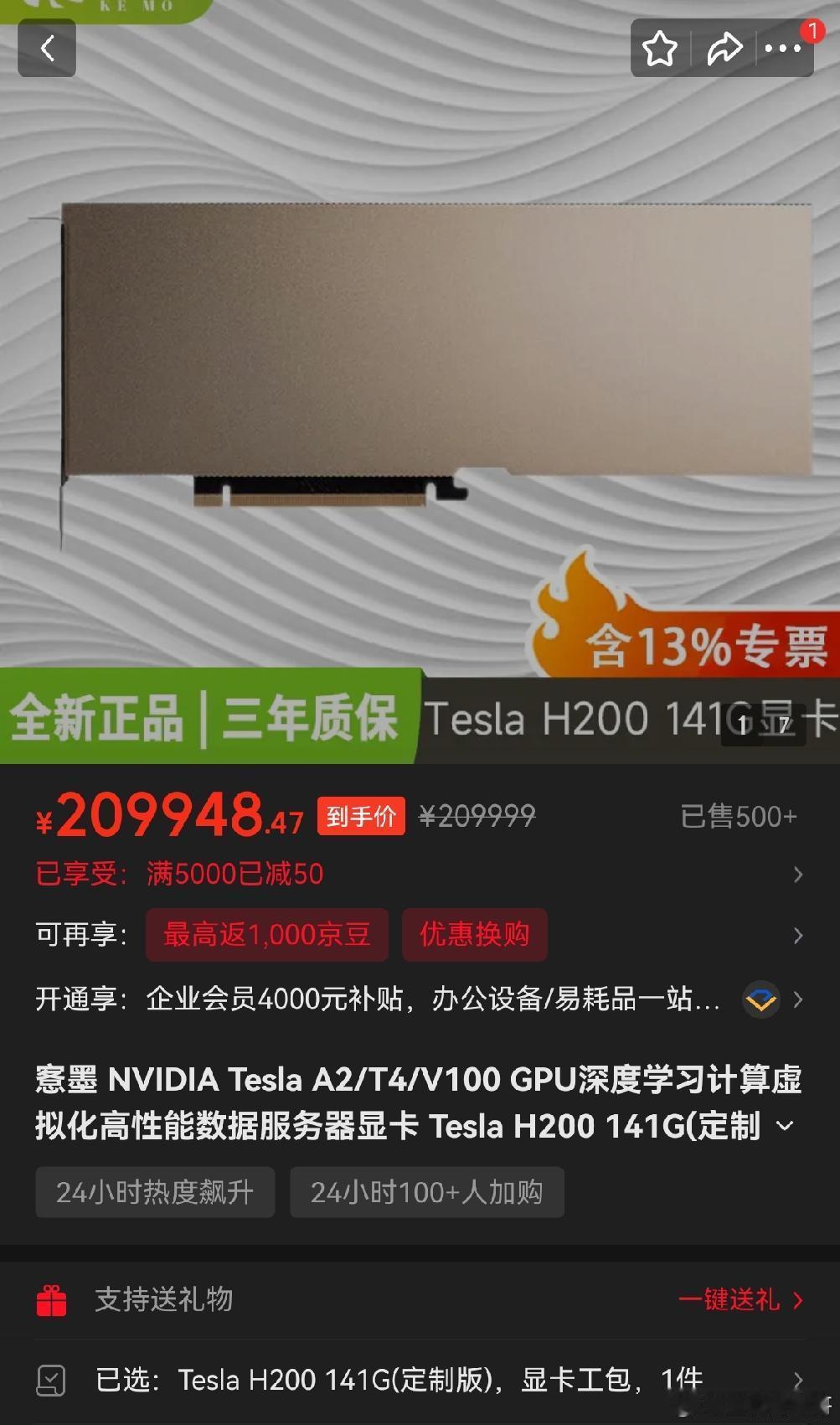
H200与H100共享相同的GH100核心:18432个CUDA核心,FP16/BF16算力均为1979 TFLOPS。真正的变革在于显存——H200首次商用HBM3e技术,提供141GB容量和4.8 TB/s带宽。相比H100的80GB HBM3(3.35 TB/s),容量提升76%,带宽跃升43%。
简单来说,H200让数据在GPU内部的流动速度接近物理极限,这对大模型推理至关重要。
二、技术创新:HBM3e的“杀手锏”
HBM3e是H200的灵魂。对LLM推理而言,内存带宽往往比峰值算力更关键——模型参数和KV Cache需要快速在显存与计算单元之间传输。H200的141GB可容纳更大批量和更长上下文,4.8TB/s则确保计算核心永不“饿死”。实测中,处理Llama 2 70B时,H200的生成速度达到H100的1.9倍;在GPT-3 175B上也能提升1.6倍。
三、适用场景:推理为王,训练为辅
H200最适合三类任务:大模型推理服务(尤其是70B以上模型和MoE模型)、长上下文应用(如RAG、多轮对话)、大模型微调(LoRA等)。在训练侧,由于带宽提升,GPT-3 175B的训练速度也比H100快约16%。MLPerf Inference 4.0的Llama 2评测中,H200系统吞吐量高出H100 45%。
四、市场供应:一芯难求
进入2026年,AI算力需求爆发式增长,H200成为最紧俏的资源。单卡采购价约3-4万美元,云端租赁在3.7-10.6美元/GPU·小时之间。受美国出口管制影响,中国头部企业(阿里、腾讯、字节等)已获限量为75万颗的总采购许可,英伟达也在2026年3月恢复对华供应。即便如此,全球供应链仍面临36-52周的交货延迟。
五、总结
H200不是算力最强的GPU(Blackwell B200才是),却是当下最务实、最易获得的高端AI算力选项。它用成熟架构和颠覆性显存证明了:在推理时代,带宽就是性能,内存就是生产力。






评论列表