DeepSeek连续几次的更新,持续搅动着AI行业的格局,这次DeepSeek-V3.2的发布也是如此!反倒是,OpenAI、Google、Anthropic等美国AI巨头,最近几个月都突然安静了。
为什么如此反常?
这背后,藏着一个关键原因:DeepSeek的技术路线与商业逻辑,真正触动了美国AI生态的核心利益,动了那块“大且贵”的奶酪。我们从几个方面来详说这件事。

AI被称作“算力怪兽”,而美国顶级大模型的发展,始终依附于一条清晰的黄金利益链条:显卡采购→数据中心搭建→云服务租赁→模型订阅收费→API接口变现。这条链条上的每一个环节,都成为了相关企业盈利的抓手,形成了对用户的层层收费。
当用户使用美国的GPT等AI时,看似只支付了20美元的订阅费,实则在为整个硅谷的商业生态买单:给NVIDIA支付芯片采购费,给AWS、微软支付服务器与云服务费用,还要为OpenAI的研发成本埋单。
这种“三重收费模式”,让美国AI模式的本质并非“做AI技术”,而是“做AI的生意”——通过算力堆砌的高成本,构建起盈利的商业闭环。

正是因为看穿了美国AI的算力盈利逻辑,DeepSeek的每一次更新,都让海外各方高度关注。它跳出了“堆算力”的传统路径,凭借DSA稀疏注意力技术,实现了算力的精准利用:只针对关键部分进行计算,将原本需要100元的算力成本,压缩至30元就能完成同等任务。
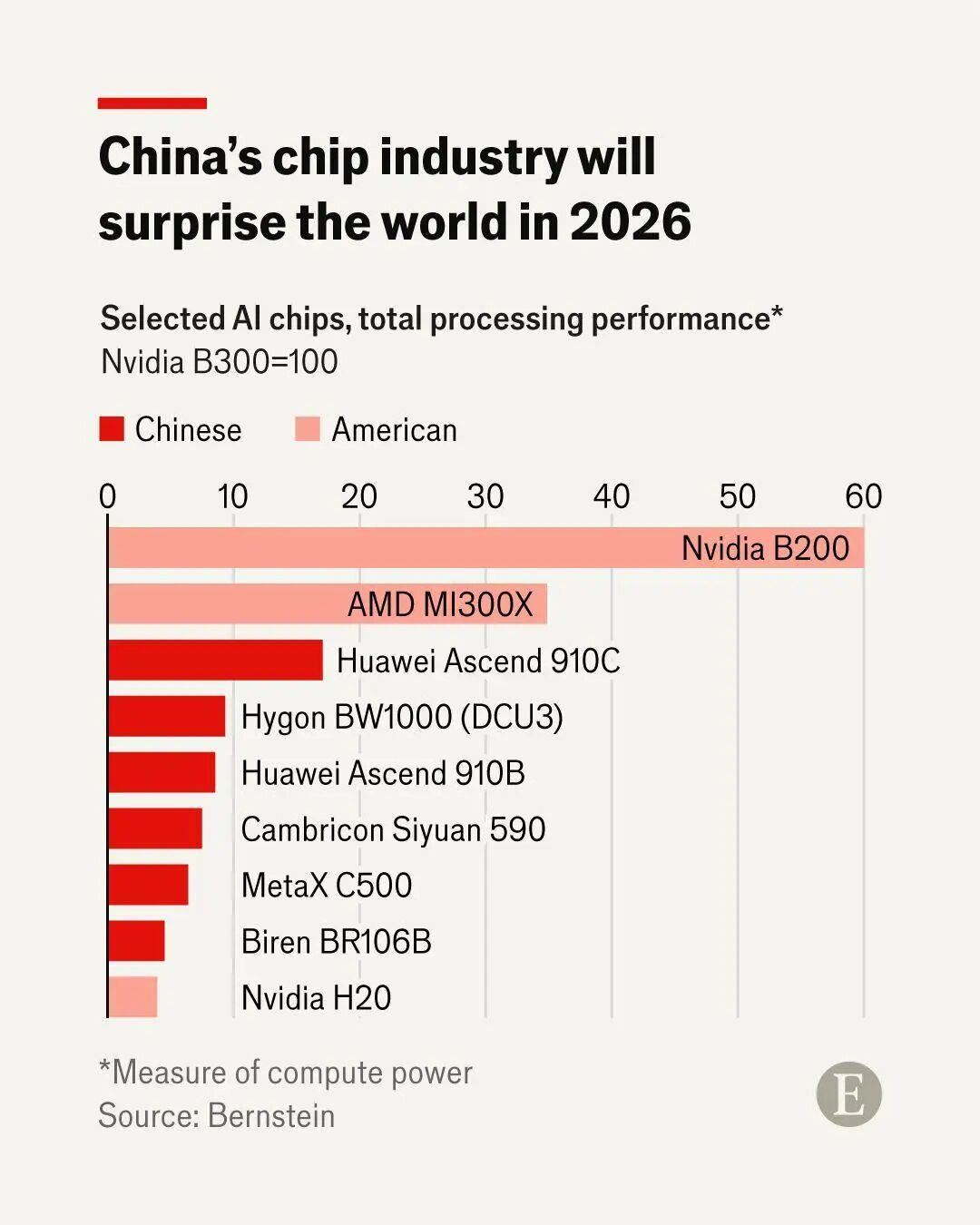
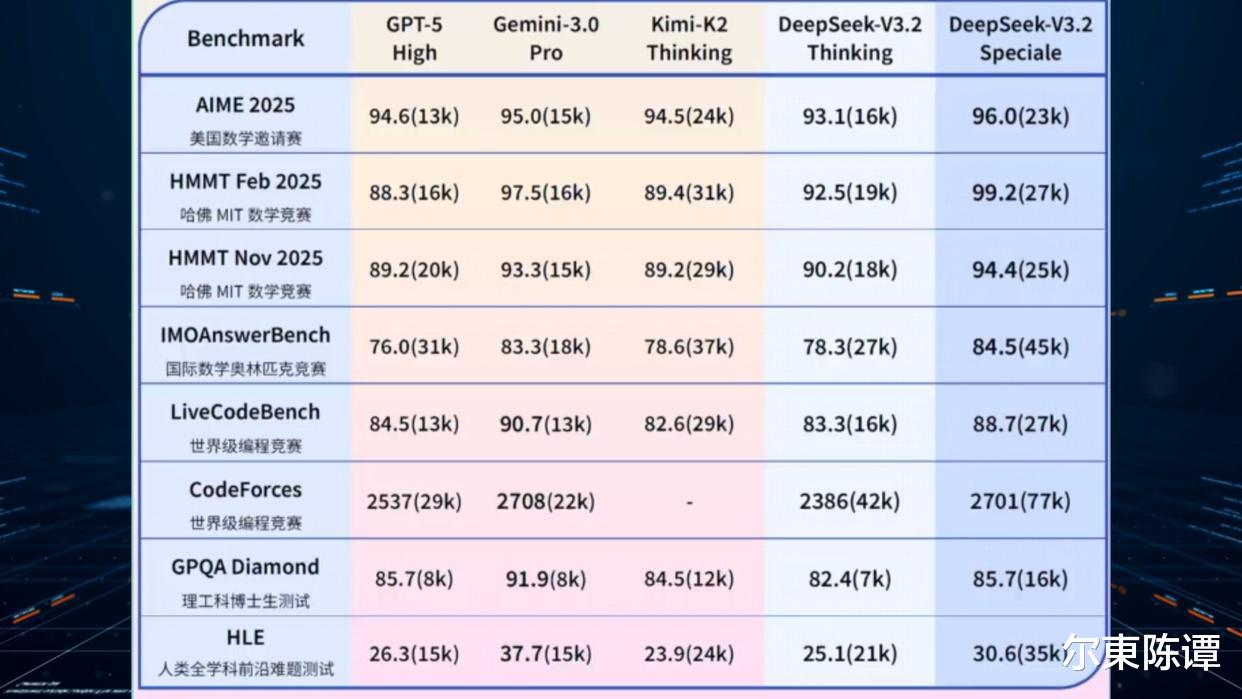
更具颠覆性的是,DeepSeek在降低成本的同时,还实现了性能的跃升。最新的模型V3.2系列,在推理能力、Agent工具调用以及国际数学奥林匹克、国际大学生程序设计竞赛等顶尖赛事的模拟测试中,其表现已不输GPT-5、Gemini3.0-Pro。
这意味着中国AI首次实现了“低成本→高性能→可规模化”的突破,这不仅是技术层面的创新,更是对美国AI商业模式的“降维打击”。
DeepSeek的突破,让硅谷陷入了前所未有的焦虑,首当其冲的便是NVIDIA、OpenAI与行业资本:
- NVIDIA慌了——算力效率的提升意味着市场对高端显卡的需求将被稀释,其作为算力核心供应商的盈利根基受到冲击;
- OpenAI慌了——自身模型因算力堆砌持续涨价,而DeepSeek却不断降低使用成本,传统的订阅制商业模式面临直接挑战;
- 行业资本慌了——原本将AI视作下一轮“印钞机”,期待通过算力垄断实现持续盈利,而DeepSeek掀起的“成本革命”,彻底打乱了这一预期。
DeepSeek的出现,不再是单一企业间的技术竞争,而是触及了美国AI企业的根本利益,动摇了其长期构建的商业护城河。

DeepSeek-V3.2系列能够实现算力效率与成本的双重突破,根源在于其身上有着鲜明的中国化特征:
一是极致的工程效率,研发方向并非为了技术炫技,而是聚焦于实际应用中的效率提升;二是极限的成本优化,降低成本的最终目标不是单纯的价格竞争,而是让AI技术触达十亿级别的普通用户。
美国AI技术走的是“贵族化”路线,将AI打造成少数人能用的奢侈品;而中国AI则坚持“民用化”方向,致力于让AI成为人人可用的日用品。当AI的属性从奢侈品转变为日用品时,那些依靠高成本、高定价盈利的美国巨头,自然成为了最大的受损方。

所以,DeepSeek-V3.2的更新并非一次简单的技术迭代,而是AI行业变革的第一声枪响。而且,DeepSeek-V3.2触碰的不是一家公司的奶酪,而是整个美国 AI 商业体系的护城河。
同时,这也标志着AI战争的核心已从“谁的参数更多、模型更大、显卡更猛”的算力竞赛,转向“谁的效率更高、成本更低、普惠性更强”的效率之争。硅谷过去十年依靠算力垄断构建的盈利模式,正被中国的“效率创新”逐步瓦解。