AI正迎来范式转变?
过去,大家热衷于调用大型通用语言模型(LLM)API,但现在越来越多企业开始自主训练、优化并运行基于开源的小型、专业化模型。
近期多个信号印证这一趋势:
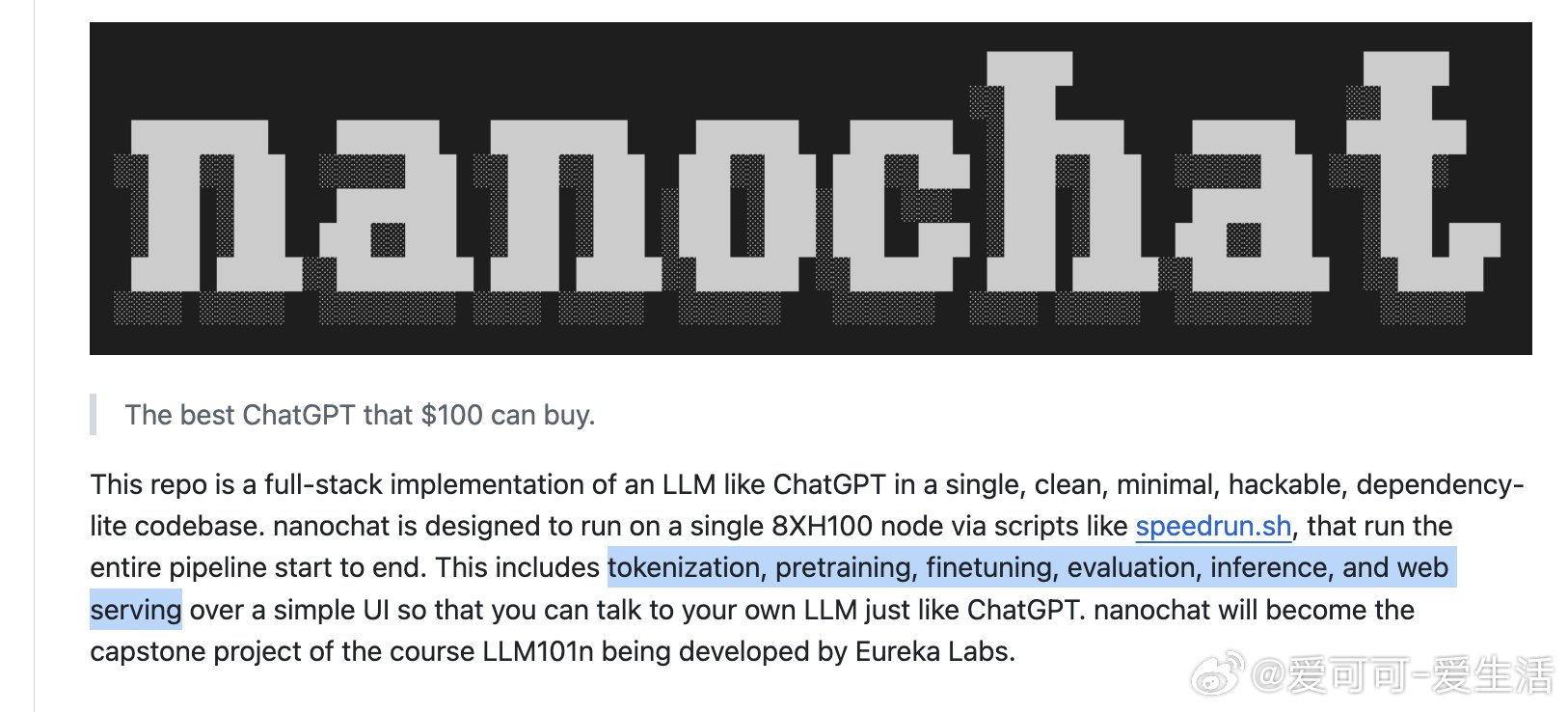
- Karpathy 推出 nanochat,几行代码即可训练模型
- Thinky Machines 推出微调产品
- vllm、sgl、Loras、trl等工具快速走红
- Hugging Face 90天内新增100万个代码库,甚至包括OpenAI首个开源LLM
- NVIDIA发布DGX Spark,强大到足以让每个人在家微调模型
这背后原因?除了强化学习(RL)和后训练成本下降,企业对数据隐私、模型透明度和业务定制的需求也推动了这波浪潮。
不过,也有人认为:
- 大多数普通用户依然依赖ChatGPT、Gemini等大厂通用模型
- 微调和自主训练还主要是资本雄厚企业的游戏
- 开源和闭源模型性能差距依然存在,但已趋于接近
- 专业化小模型未来更受欢迎,尤其在医疗、心理咨询等领域表现更优
趋势的核心在于:
“小而专”的模型能更好地贴合企业具体需求,降低成本,保护隐私,促进生态共建。
未来,AI将从“通用黑盒”走向“专属定制”,人人皆可拥有适合自己业务甚至个人的大模型。
这不仅仅是技术迭代,更是AI应用和商业模式的深刻变革。我们正进入一个“后训练时代”,数据质量、微调能力和工具链成熟,推动AI走向去中心化和多样化。
原推文:
x.com/ClementDelangue/status/1978113358772449379


![最火ai排名,你平常用哪个[思考]](http://image.uczzd.cn/13567813052405002715.jpg?id=0)



