目前来看Google 是唯一一家在 AI 价值链上实现端到端垂直整合的公司。从基础模型 (Gemini)、应用层 (ImageFX, Search with Gemini, NotebookLM),到云架构 (Google Cloud, Vertex AI) 以及硬件 (TPUs),几乎全都有所布局。

长期以来Google 一直在通过提升自身能力来减少对 NVIDIA GPU 的依赖。这种技术积累逐渐演变成了现在的 JAX AI 栈。

更有意思的是这套技术栈现在不仅 Google 自己用,Anthropic、xAI 甚至 Apple 这些头部 LLM 提供商也都在用
所以我们就很有必要这就很有必要深入聊聊这套技术栈了。
什么是 JAX AI 栈?简单来说,JAX AI 栈是一套面向超大规模机器学习的端到端开源平台。
核心组件主要由以下四个部分构成:
1、JAXGoogle 和 NVIDIA 联合开发的 Python 高性能数值计算库。
接口设计极其类似 NumPy,但区别在于它能自动、高效地在 CPU、GPU 或 TPU 上运行,无论是本地还是分布式环境。
底层的技术在于 XLA (Accelerated Linear Algebra) 编译器,它能把 JAX 代码转译成针对不同硬件深度优化的机器码。对比之下NumPy 的操作默认只能在 CPU 上跑,效率天差地别。
2、Flax基于 JAX 的神经网络训练库。Flax 的核心现在是 NNX (Neural Networks for JAX)。这是一个简化版的 API,让创建、调试和分析 JAX 神经网络变得更直观。
之前有个 Flax Linen,是那种无状态、函数式风格的 API。而 NNX 作为继任者,引入了面向对象和有状态的特性,对于习惯了 PyTorch 的开发者来说,构建和调试 JAX 模型会顺手很多。
3、OptaxJAX 生态里的梯度处理和优化库。
它的优势在于灵活性,几行代码就能把标准优化器和复杂的技巧(比如梯度裁剪、梯度累积)链式组合起来。
4. Orbax专门处理 Checkpoint 的库,用于保存和恢复大规模训练任务。
支持异步分布式检查点,这在大模型训练里至关重要——万一硬件挂了,能从断点恢复,不至于让昂贵的算力打了水漂。
下面这张图展示了完整栈的架构,除了上面这四个核心,还有很多其他组件,建议细看。
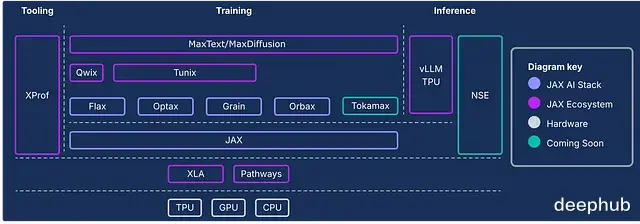
JAX 之所以在 GPU 和 TPU 上能跑赢 PyTorch,主要归功于即时 (JIT) 优化和 XLA 的后端编译效率。
我们直接上手用 JAX 撸一个简单的神经网络,搞个手写数字识别,看看这套栈在实际工作流里到底怎么用。
1、环境配置JAX AI 栈现在整合成了一个 metapackage,安装很简单。然后我们还需要 sklearn(加载数据)和 matplotlib(画图)。
!uv pip install jax-ai-stack sklearn matplotlib
2、加载数据直接用 sklearn 加载 UCI ML 手写数字数据集。
from sklearn.datasets import load_digits # Load dataset digits = load_digits()
数据是 8 x 8 的像素化手写数字图像(0 到 9)及其对应的标签。
print(f"Number of samples × features: {digits.data.shape}") print(f"Number of labels: {digits.target.shape}") """ Number of samples × features: (1797, 64) Number of labels: (1797,) """
3、 数据可视化先看看数据长什么样,挑 100 张图画出来。
import matplotlib.pyplot as plt fig, axes = plt.subplots(10, 10, figsize=(6, 6), subplot_kw={'xticks':[], 'yticks':[]}, gridspec_kw=dict(hspace=0.1, wspace=0.1)) for i, ax in enumerate(axes.flat): ax.imshow(digits.images[i], cmap='binary', interpolation='gaussian') ax.text(0.05, 0.05, str(digits.target[i]), transform=ax.transAxes, color='green')

常规操作,把数据切成训练集和测试集。
from sklearn.model_selection import train_test_split # Create dataset splits splits = train_test_split(digits.images, digits.target, random_state=0)
5、转为 JAX 数组这一步很关键,输入到模型之前,需要用 JAX Numpy 把数据转成 JAX 数组格式。
import jax.numpy as jnp # Convert splits to JAX arrays images_train, images_test, label_train, label_test = map(jnp.asarray, splits)
看一眼数据维度:
print(f"Training images shape: {images_train.shape}") print(f"Training labels shape: {label_train.shape}") print(f"Test images shape: {images_test.shape}") print(f"Test labels shape: {label_test.shape}") """ Training images shape: (1347, 8, 8) Training labels shape: (1347,) Test images shape: (450, 8, 8) Test labels shape: (450,) """
6、用 Flax 构建网络用 Flax NNX 搭建一个带 SELU 激活函数的简单前馈网络。习惯写 PyTorch 的朋友会发现,这语法看着非常眼熟。
from flax import nnx class DigitClassifier(nnx.Module): def __init__(self, n_features, n_hidden, n_targets, rngs): self.n_features = n_features self.layer_1 = nnx.Linear(n_features, n_hidden, rngs = rngs) self.layer_2 = nnx.Linear(n_hidden, n_hidden, rngs = rngs) self.layer_3 = nnx.Linear(n_hidden, n_targets, rngs = rngs) def __call__(self, x): x = x.reshape(x.shape[0], self.n_features) #Flatten images x = nnx.selu(self.layer_1(x)) x = nnx.selu(self.layer_2(x)) x = self.layer_3(x) return x
7、实例化模型JAX 处理随机数的方式比较特别。这里用 nnx.Rngs(0) 初始化一个种子为 0 的随机数生成器 (RNG) 对象。这个对象负责管理网络操作里的所有随机性,比如参数初始化和 Dropout。
注意,这和 PyTorch 直接设全局种子 torch.manual_seed(seed) 的逻辑不一样。
# Initialize random number generator rngs = nnx.Rngs(0) # Create instance of theifier model = DigitClassifier(n_features=64, n_hidden=128, n_targets=10, rngs = rngs)
8、定义优化器与训练步骤用 Optax 定义优化器和损失函数。
import jax import optax # SGD optimizer with learning rate 0.05 optimizer = nnx.ModelAndOptimizer( model, optax.sgd(learning_rate=0.05)) # Loss function def loss_fn(model, data, labels): # Forward pass logits = model(data) # Compute mean cross-entropy loss loss = optax.softmax_cross_entropy_with_integer_labels( logits=logits, labels=labels).mean() return loss, logits # Single training step with automatic differentiation and optimization @nnx.jit # JIT compile for faster execution def training_step(model, optimizer, data, labels): loss_gradient = nnx.grad(loss_fn, has_aux=True) # 'has_aux=True' allows returning auxiliary outputs (logits) grads, logits = loss_gradient(model, data, labels) # Forward + backward pass optimizer.update(grads) # Update model parameters using computed gradients
代码里用到了两个核心变换,这是 JAX 高效的秘诀:
jax.jit:即时编译,把训练函数扔给 XLA 编译器,重复执行速度极快。
jax.grad:利用自动微分计算梯度。
Flax NNX 把它俩封装成了装饰器 nnx.jit 和 nnx.grad,用起来更方便。
9、训练循环跑 500 epoch,每 100 轮显示 Loss。
num_epochs = 500 print_every = 100 for epoch in range(num_epochs + 1): # Training step training_step(model, optimizer, images_train, label_train) # Evaluate and print metrics periodically if epoch % print_every == 0: train_loss, _ = loss_fn(model, images_train, label_train) test_loss, _ = loss_fn(model, images_test, label_test) print(f"Epoch {epoch:3d} | Train Loss: {train_loss:.4f} | Test Loss: {test_loss:.4f}")""" Epoch 0 | Train Loss: 0.0044 | Test Loss: 0.1063 Epoch 100 | Train Loss: 0.0035 | Test Loss: 0.1057 Epoch 200 | Train Loss: 0.0029 | Test Loss: 0.1054 Epoch 300 | Train Loss: 0.0024 | Test Loss: 0.1052 Epoch 400 | Train Loss: 0.0021 | Test Loss: 0.1051 Epoch 500 | Train Loss: 0.0019 | Test Loss: 0.1050 """
10. 效果评估最后看看在测试集上的表现。
# Evaluate model accuracy on test set logits = model(images_test) predictions = logits.argmax(axis=1) correct = jnp.sum(predictions == label_test) total = len(label_test) accuracy = correct / total print(f"Test Accuracy: {correct}/{total} correct ({accuracy:.2%})") # Test Accuracy: 437/450 correct (97.11%)
97% 的准确率,对于这么简单的网络来说相当不错了。
最后把预测结果可视化一下,绿色是对的,红色是错的。
fig, axes = plt.subplots(10, 10, figsize=(6, 6), subplot_kw={'xticks':[], 'yticks':[]}, gridspec_kw=dict(hspace=0.1, wspace=0.1)) for i, ax in enumerate(axes.flat): ax.imshow(images_test[i], cmap='binary', interpolation='gaussian') color = 'green' if label_pred[i] == label_test[i] else 'red' ax.text(0.05, 0.05, str(label_pred[i]), transform=ax.transAxes, color=color)

到这里,你就已经在 JAX 生态里跑通了第一个神经网络。JAX 的门槛其实没那么高,但它带来的性能收益,特别是在大规模训练场景下,绝对值得投入时间去学。
https://avoid.overfit.cn/post/5279caa8ac7f4b1dbe34d90628a58672
作者:Dr. Ashish Bamania





![ai最终说出了真相[捂脸哭]](http://image.uczzd.cn/8204561385660780354.jpg?id=0)

