原来中国AI是这么追上来的,不是蒸馏,现在中国AI用海量编程样本学习进步自我迭代了
最近美国人很着急,中国AI不断取得进步。GLM5.2指标据说超过了Gemini,追平Claude Opus 4.8,还放话今年就要追平Claude Fable。DeepSeek又开源了一个大招DSpark,大幅加速推理,底层原创成果一个接一个。Kimi三季度要发布K3,大版本升级,2.52万亿参数,原生多模态、百万字上下文。
不久前,我曾经担心美国AI进步比中国更快,据说AI编程改自己的代码,迭代改进加速,而中国AI受算力限制进步速度缓下来。现在感觉情况反过来了,中国AI找到了加速发展的办法,而美国AI反而被算力卡了。美国训练不缺算力,但这是硬堆卡,用户多的推理就很缺算力了。而且美国AI用的高成本方案,搞Dense模型,不注意优化,结果是业界抱怨token太贵,纷纷转向中国便宜的开源AI,惊喜地发现还挺不错。
最关键的,还是中国AI找到了突破的办法。现在业界有共识了,AI编程已经卡不住中国AI了,是一个已经解决的问题。
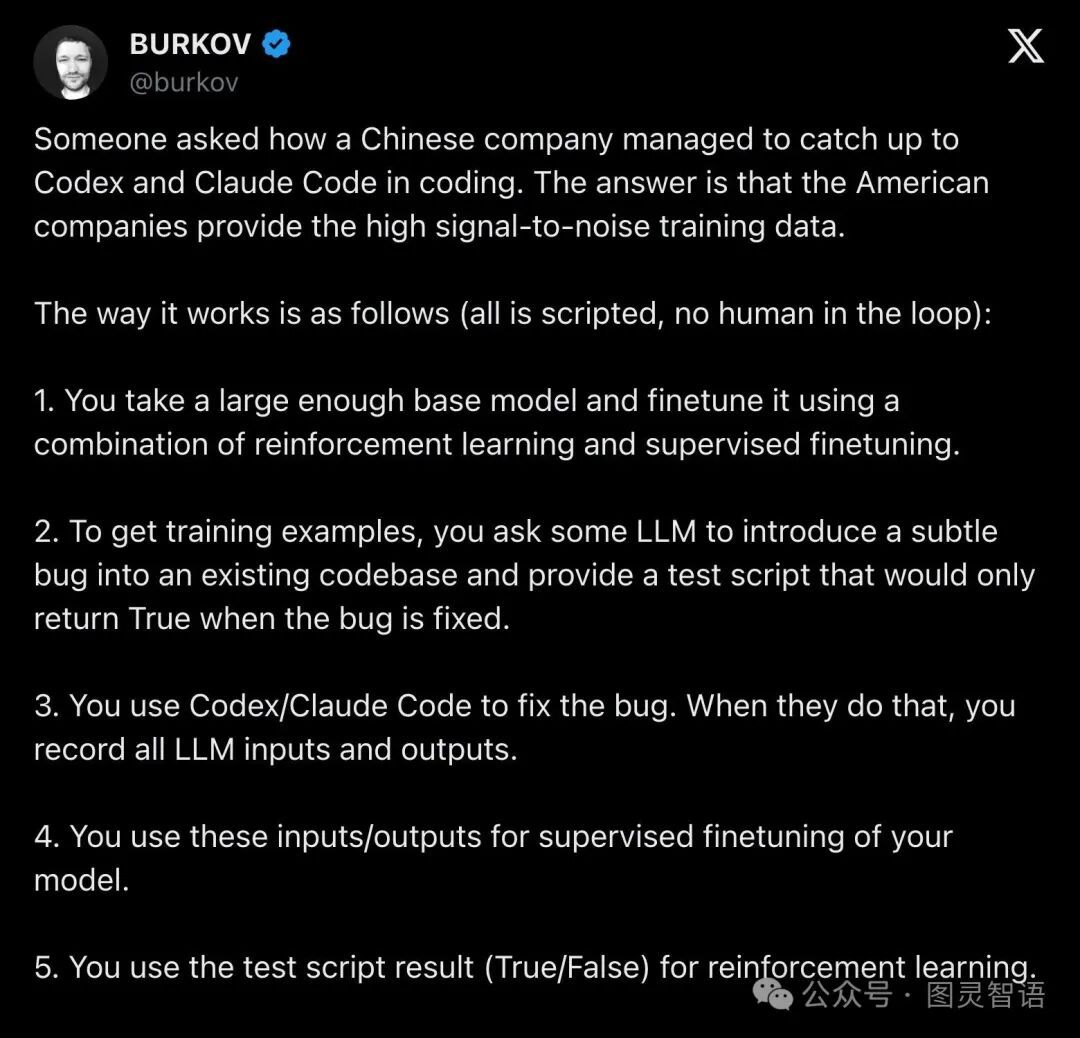
美国一个哥们介绍说,这个大招是,先找几十万例的编程代码,这容易。这些案例是人类编写跑通的,网上开源的到处是,算是正确的编程样本。然后做一个小模型,专门“干坏事”,往里加bug,这也不难。训练目标,就是中国大模型,学会改bug。如果把bug都修好了,这肯定就编程无所不精了,算通关了,bug并不容易改。
美国人说中国AI“蒸馏”,这是一种常见技术,Knowledge Distillation,十几年前就有的。这是说中国公司向美国AI提出上千万个问题,然后训练自己的大模型,模仿美国AI输出的答案(不是token序列,需要是概率分布),模仿好了就把美国AI的能力学会了。这其实是一种落后技术,根本没法学会,因为现在大模型输出过程很复杂,先要内部思考,要搜索,要Agent,最终输出只是一个综合结果,意义下降了。
现在的学习,不是这么简单地模仿答案。而是把高水平AI的思考过程,解决问题的序列都记下来。图中说方法 ,对应的是“数据提取 + 行为克隆 + RL”。Data Distillation、Capability Distillation、Behavior Cloning,关注的是行为轨迹。
最后一步是,RL强化学习。生成了几十万个实际编程的bug样例,然后让AI去学习摸索改正,结果是True或者False,就能训练成功。这类似DeepSeek R1的简单优雅的AI自学习办法,编程也能这么干了。所以编程进步变得简单了。
但这里需要一个SFT训练“冷启动”,如果大模型没有足够强的基础能力,这么去试着改bug,训练不会成功。美国AI能提供SFT的训练数据,帮助中国AI获得基础能力。
关键是,这个框架比蒸馏要强大!蒸馏学习是不可能比教师模型要强的,多半是弱不少。而SFT获得的基础能力之后,可以通过RL,比生成SFT训练样本的美国AI还强大!
因此,美国AI只是起了一些“历史作用”,帮助生成了一些训练数据。等中国AI突破了,就可以自己来循环迭代了,不需要再去参与美国AI了(除非美国AI又进步极大,中国AI自学无法突破)。即使中国AI不再用美国AI生成训练数据,也能继续进步。