从编程角度介绍下大模型应用(1)
最近大模型产业彻底爆发,从2022年底的聊天,发展到最近流行的Agent了,每天消耗的token数量爆增,几百万亿个了。日均Token消耗超过100万亿的公司就有三家,字节、谷歌、OpenAI。很多人天天用大模型很熟了,替代了搜索。agent功能都有不少人用了,小龙虾前段时间很火。有些大模型还是原生多模态的,聊天框里贴图直接就能理解。
但我感觉,大家主要还是从外部,形式上接触大模型和各种形式的大模型应用。它内部运作原理,模模糊糊知道一些,transformer都听说过,注意力机制,思维链,联网搜索,但概念多半不太清晰。其实开源运动起来后,特别是DeepSeek把底层技术说得很细,现在大模型行业基本没有技术秘密了。即使现在最火的Claude,怎么做出来的也不是机密,Claude Code的源代码都泄露了。各家大模型区别就是数据、规模、算力、实现细节,主要是工程上的,理论上没有秘密。当然这个工程特别复杂,没一堆天才支撑着玩不动,还要很多钱买算力,门槛相当高。
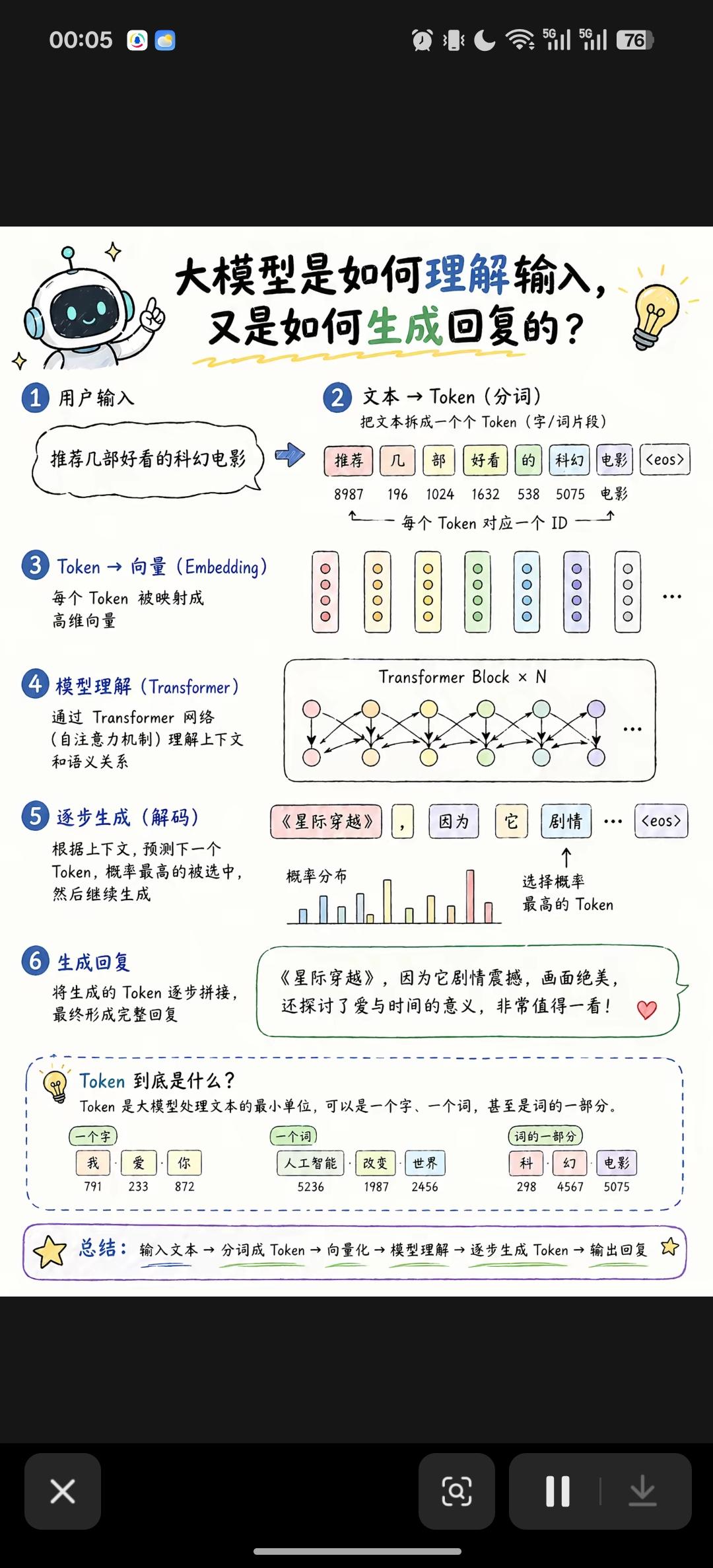
我学习以后,一个顿悟是,大模型这一个个厉害的功能与应用,说到底都是程序。只不过大模型应用和以前的程序有些区别,一个是神经网络规模特别大有“智能”了,二个是调用神经网络精心包了很多层,也和以前用神经网络不一样。大家理解程序都没啥问题,仔细解释后,应该就能深入理解大模型应用,并不神秘。首先一条,就不要被“智能”吓住,都是程序。
就比如,以前AlphaGo下棋碾压人类,说“智能”超过人了。但好多团队都开发出厉害的AI围棋程序,就发现这东西实质是程序,就不认为是多高级的智能了,实际功能非常单一。不用扯“智能”的定义,还原到底层,核心就是有一个神经网络数据结构,“价值网络”与“策略网略”合二为一的,一个不太大的神经网络,配个GPU强点的单机就能跑。然后还有CPU去调用这个神经网络,跑一个叫MCTS的概率搜索算法,一会让它输出棋局的价值(黑白局势评估),一会输出好的候选点(从这些点开始推理),跑时间够了概率靠谱了,就能输出“胜率”和前几个不错的高胜率好点,非常准确。
我最近寻思,现在的大模型应用,各类常见的Agent应用,本质上和AlphaGo的程序架构是一样的。只是大家不知道细节,就迷糊,把细节说清楚了,就明白居然是这么回事。小龙虾、AI编程、深度研究、文档处理,这些都可以说是Agent应用,而本质就是编程调用大模型,访问神经网络。甚至最简单的大模型聊天框,也可以这样理解。
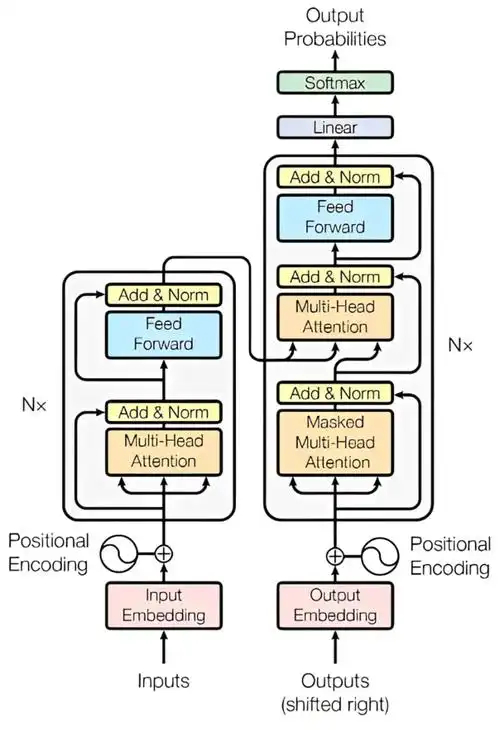
这里涉及大模型的结构细节,有时说得很复杂,就图中这个transformer结构框图,解释起来要30多个基础概念,根本没人看。但如果从编程角度看,完全可以当黑盒一样简化处理。大模型训练确实难如登天,但大模型推理真不难,人人都可以快速上手调用大模型,和编程一样玩起来不难。以前大伙学编程的时候,编译原理其实是不用学的,直接理解程序就行。下面我按这个路线,从大模型聊天框开始,解释各类大模型应用具体是如何实现的。确实很多细节,要了解细节才能明白怎么回事。