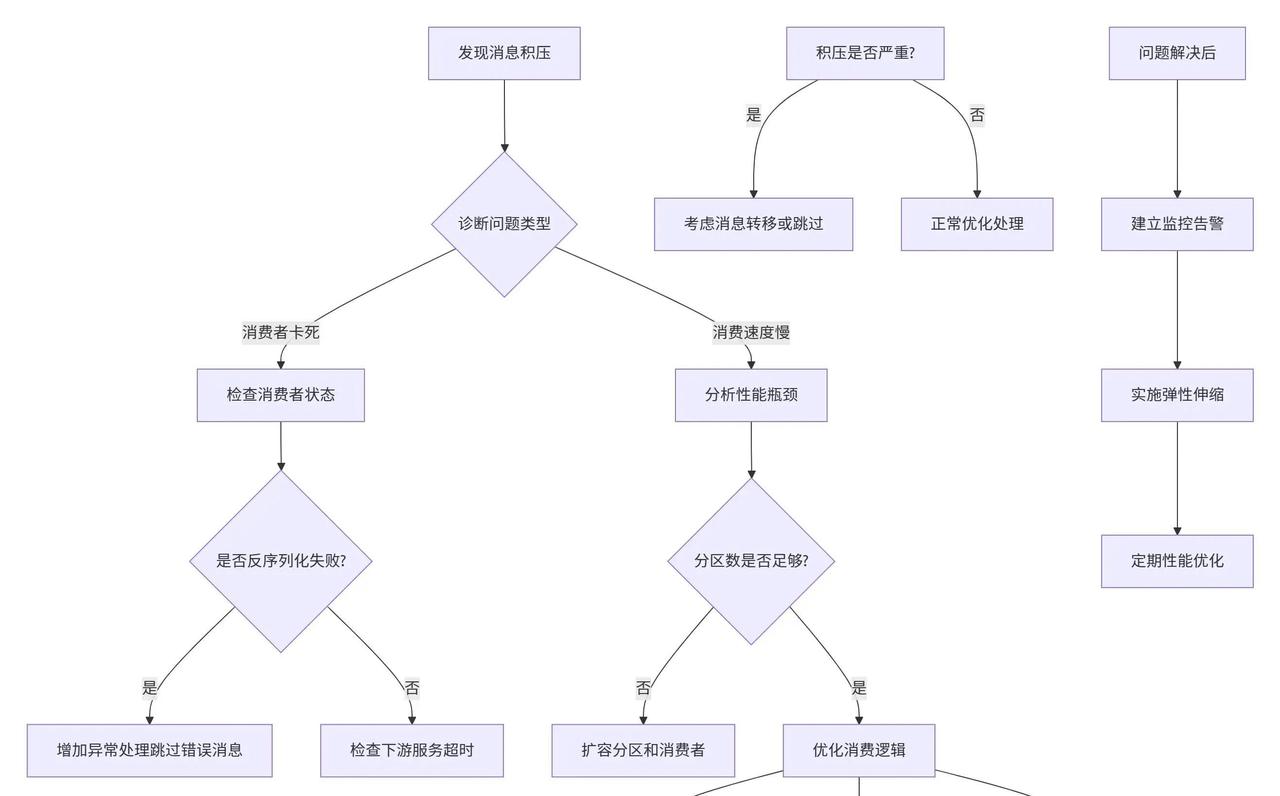
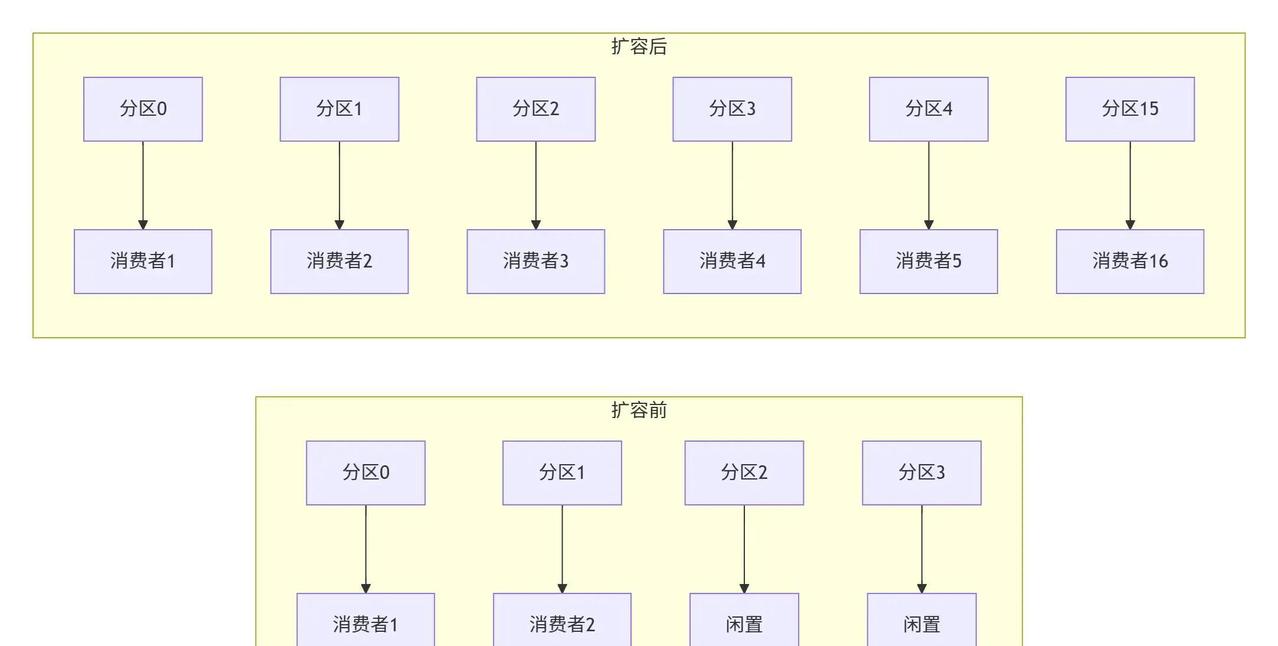
Kafka消息积压瞬间炸锅,Lag指标暴增上万,业务链条濒临断裂,这痛点为何总在高峰期爆发? 消息堆积的核心隐患分两种截然不同路径。第一种,Offset长期不动弹,消费者ID甚至空缺,这往往是实例悄然下线导致。系统会误判消费者活跃,Lag却如雪球般滚大。快速诊断后,重启实例或排查网络故障,就能让Offset重新提交,恢复正常流动。根据2023年Confluent公司报告,高达60%的积压源于此类消费者中断,及早监控可将恢复时间缩短至分钟级。 第二种情况更棘手,Offset正常推进,消费者在线却跟不上节奏,Lag仍旧攀升。这暴露吞吐量瓶颈,分区数或实例规模不足以匹配生产速度。扩容分区前后,并行度可从单线程翻倍到多路并进;实例扩展则直接抬高处理上限。拿批量消费来说,单条处理仅50-100条/秒,数据库每次单次叩门,网络开销居高不下。切换批量模式,吞吐量直冲1000-5000条/秒,数据库压力降八成,网络负载也大幅减轻。2024年Apache Kafka官方基准测试证实,这种优化在非强一致场景下,整体效率提升超5倍。 针对非实时需求,异步架构成关键解药。设立临时Topic转移积压消息,再用离线程序批量消化,避免主线阻塞。Prometheus加Grafana监控Lag阈值,设置告警规则;生产端加限流阀门,防洪峰涌入。透过这些,积压从急症变慢性管理,揭示出Kafka体系的规律:应急扩容治标,架构重塑方能根除隐患,确保消息链条长效稳健