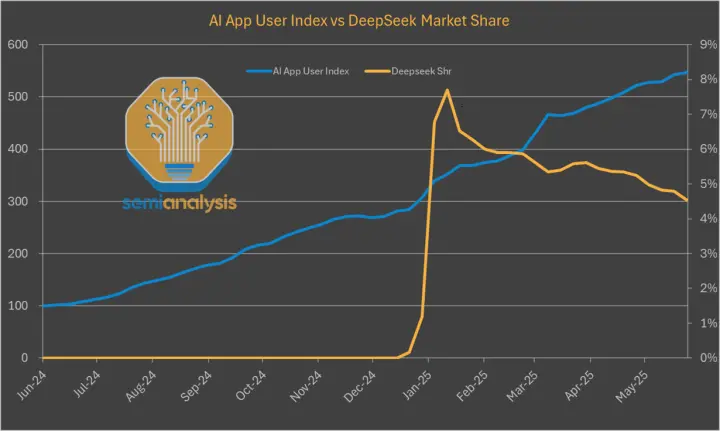
几个月前,DeepSeek还被寄予厚望。作为中国AI大模型领域的黑马,它曾在春节期间一度冲上使用率7.5%的高点,在多个平台展现出强劲的增长势头。
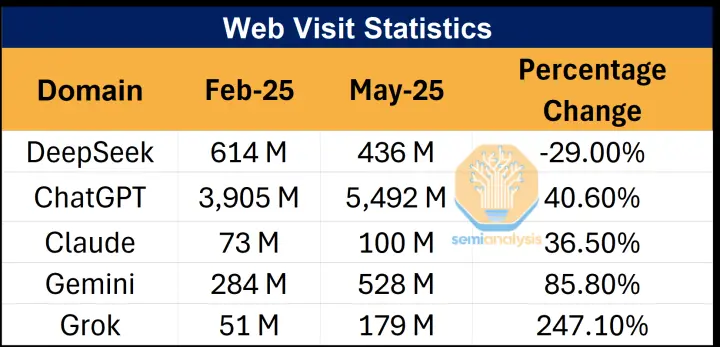
然而短短数月之后,形势急转直下。根据Semianalysis与Poe平台提供的数据,截至今年5月,DeepSeek使用率已骤降至3%,官网流量下滑近三成,Token调用流量也从42%萎缩到16%。面对这种堪称“断崖式”的退潮,DeepSeek到底怎么了?
一、模型未迭代,新鲜感退却
技术产品的生命线,是迭代。AI大模型的更是如此。
DeepSeek之所以在年初获得一波流量爆发,很大程度上是因为其推出的R1模型在中文处理能力上表现亮眼,吸引了不少中文用户和开发者。然而,这种增长并未得到持续的产品支持。
原计划在5月发布的DeepSeek-R2迟迟未能上线,这成为使用率暴跌的直接导火索。市场原本期待通过R2看到DeepSeek能否突破R1的能力瓶颈,在多轮对话、长文本理解和代码生成等方面迎头赶上OpenAI的GPT-4和Anthropic的Claude。
如今这个期待被反复推迟,自然也就演变为失望。
更何况,AI用户对模型能力的容忍度极低,一旦性能增长停滞,他们转身的速度甚至比网文读者弃书还快。跟传统产业相比,AI时代的新常态是:技术红利有保质期,而用户忠诚却没有。
二、技术焦虑:硬件短缺、模型能力双重滞后
DeepSeek并非无所作为。据TheInformation报道,其团队一直在密集推进R2开发,CEO梁文锋本人对模型能力的标准相当严苛,这种“追求更好”的执念值得敬佩。然而,技术产品的尴尬在于——“还没准备好”也可能意味着“已经太迟”。
此外,英伟达H20芯片短缺对整个中国AI产业链都是一道难题,DeepSeek首当其冲。高性能GPU的匮乏限制了模型的训练效率和部署能力。也正因如此,R2的跳票并非单纯的产品管理失误,也暴露出国产AI基础设施的脆弱性。
在AI大模型领域,仅靠算法与人才远远不够,算力与资本才是决定生死的基石。
三、市场环境变了,强敌环伺之下腹背受敌
在DeepSeek陷入“更新难产”之际,竞争对手们却在全速前进。
OpenAI发布GPT-4o后,ChatGPT官网流量增长40.6%;谷歌Gemini则借助多模态能力,实现了85.8%的流量增长。Anthropic的Claude、Mistral的开源模型、Meta的Llama家族也都在不断抢夺用户注意力。
尤其是GPT-4o的免费化策略,对所有中高端国产模型构成降维打击。当用户能在官方渠道免费使用一个比DeepSeek更强、更快、更稳定的模型时,国产模型所仰赖的“民族亲切感”与“中文优化”就显得不那么有杀伤力了。
换句话说:产品力不足时,情怀也拯救不了冷冰冰的留存率。
四、产品战略失衡:模型强,但“平台感”不足
相比OpenAI、Anthropic等公司,DeepSeek在“产品+平台”的打造上还显稚嫩。虽然DeepSeek官网功能齐全,但在用户体验、插件生态、文档支持、第三方API接入等方面明显滞后。而ChatGPT已经逐步完成了从“AI模型”到“AI操作系统”的跃迁。
此外,不少用户反映DeepSeek官网对话体验缺乏记忆能力、响应速度不稳定,甚至UI设计也偏“工程气”,难以打动泛用户人群。这种“重技术、轻产品”的倾向,在初期可以靠硬核用户撑起门面,但在市场扩张期就成了短板。
更致命的是:DeepSeek虽然有被腾讯元宝、夸克、百度等平台接入,但自身缺乏像Claude或OpenAI那样具备清晰品牌感与平台闭环的核心阵地。在用户心中,它更像是一个“被接入的模型”,而非“主动打开的网站”。
五、数据争议也难改趋势真相
也有人对Semianalysis和Poe的数据提出质疑,认为其忽略了中国市场上各类分发渠道的真实活跃情况。比如很多用户通过夸克、QQ浏览器等场景调用DeepSeek,官网流量下降未必代表整体使用萎缩。
这个质疑并非毫无道理。但需要注意的是:即使排除数据偏差,DeepSeek用户活跃度的下滑也基本成为共识。不少开发者反馈,DeepSeek最近两个月在API调用与集成服务中的响应质量明显波动,部分用户已迁移到Kimi、百川智能等平台。
换言之,即便数据不精确,但“趋势是真实的”。一个模型使用率在多个平台、多种渠道下同步走低,其背后必然是能力、产品、运营三者的共振下滑。
结论:当潮水退去,谁在裸泳?
DeepSeek的断崖式下跌提供了一个重要警示:AI行业的爆发,不等于某家公司的成功。
中国大模型赛道从“百模大战”走到“几强争霸”,已经进入洗牌期。技术、算力、运营、生态,缺一不可。
当然,DeepSeek并不是失败了,它只是暂时没能跨过第二道门槛。从技术人主导的科研项目,进化为一个真正可持续的AI产品平台,仍需时间。但市场不会停下来等你。
潮水退去时,所有公司的底牌才开始显露。DeepSeek能否逆风翻盘,不仅取决于R2的上线速度,更取决于它能否真正打磨出一个足以留住用户的“体验闭环”。
而这,恰恰是中国所有AI模型的下半场考题,也是中国科技行业一直以来的老大难问题。
文转自凤凰网科技






大禹
我觉得好用,非常棒,[点赞][点赞][点赞][点赞]
用户12xxx24 回复 07-26 12:18
腾讯元宝的deepseek 是我用得最多的 效率提升得一塌糊涂 学几行会议概要 马上就能给你一篇专业会议纪要
用户18xxx37
一问问题就是服务器繁忙,鬼才用他的
用户12xxx24 回复 07-26 12:19
用腾讯的deep seek 呗
剑意
说实话,问点复杂的问题,回答的就是错的,还有大聪明网友不懂装懂啥都问ai
农人语
下滑3%很正常,毕竟国内很多平台已经接入了,包括微信和UC。
农人语 回复 天高云淡 07-25 23:34
肖你户了?不用告诉我的,我跟你不认识[笑着哭]二缺!傻缺一个,还以为自己有得聪明。
天高云淡 回复 07-25 22:40
你都销户了,还咋呼个屁!你还算个人吗?傻逼一个
沙漠里的泥鳅
这TMD活脱脱一个广告平台!去咨询一些技术问题,然后给你推荐的全是各类收费APP、需要充值会员的平台,甚至连推荐给你的百度百科里的文章都是需要收费的!
用户10xxx74
反正我觉得很好用,也一直在用。谢谢!
胡总督军
被打回原形,说实话不好用
大漠胡杨
别搞笑了,deepseek已经上岸了,前途无量。
刘某某 回复 07-26 00:18
看了其他人评论 就你是明白人
唐伯虎点蚊香
Deepseek广告太多了,询问一些需要答案是公司或者app的问题,经常回答非行业公认的公司和app。 很明显走的百度搜索打广告的老路。这是国内公司的通病,相比搞好产品更愿意牺牲质量来搞钱。。。
百分百神圣一击率
难道你不知道没有它之前,外国从来没有正眼看过中国的ai吗?
南天门
好用
daI
炒作跟风一过逐渐被打回原形而已
风城烟俞丶
从来不用,拉几一般的公式化答案
菠萝菠萝蜜
这个又不是给普通人娱乐的,要什么流量?
用户15xxx35
我已经将它卸载
毛头
DeepSeek 好像狗屁不通也就是模棱两可胡扯八道
用户10xxx00
一去再用
老老书虫
最近很多这种推送新闻,都什么成分啊?!
cfet
DS动了太多人的奶酪,前景堪忧
JIMMY
我早都卸载了。
知足常乐
我是说,现在用起那么丝滑,感谢各位承让。
天高云淡
牛皮吹破了
名字被占用
评论区还搁这“被打回原形”呢?事实上是他根本不在乎,甚至把算力资源都抽回去研发下一代模型了,这代的开源模型早就被腾讯元宝、百度、微信搜索、微博等各种各样的平台放到自家app上了,早就遍地开花了,你可以在任何app用到ds,所以就没必要用他的本体了呀,这就是别人的初衷,还搁这“打回原形”呢?
振衣
本来就是炒作
微笑的贝壳
我的使用体验是没有豆包好用
神物自晦
天哪,大多数人用的deepseek更多的时候就像是幻方的展品,人家就是用这个产品来告诉你,ai其实没你想的那么神秘,就是用来撕开chatgpt的神秘面纱的,真正适用deepseek的,是不会拿deepseek当chatgpt来用的,deepseek最大的价值在于本地化,中型企业花个几百万就能拥有完全属于自己的deepseek,就算你花几十亿美元,你能拥有自己的chatgpt吗,有人说我花200美元不就行了吗,大哥,那200美元是租金,个人玩玩还行,但企业能把自己的核心数据核心机密交给chatgpt吗
用户12xxx24
[得瑟]deepseek 自身服务能力有限 不等于deep seek大模型有问题 各个平台都有自己的deepseek 比如腾讯元宝 百度地图 叮咚买菜