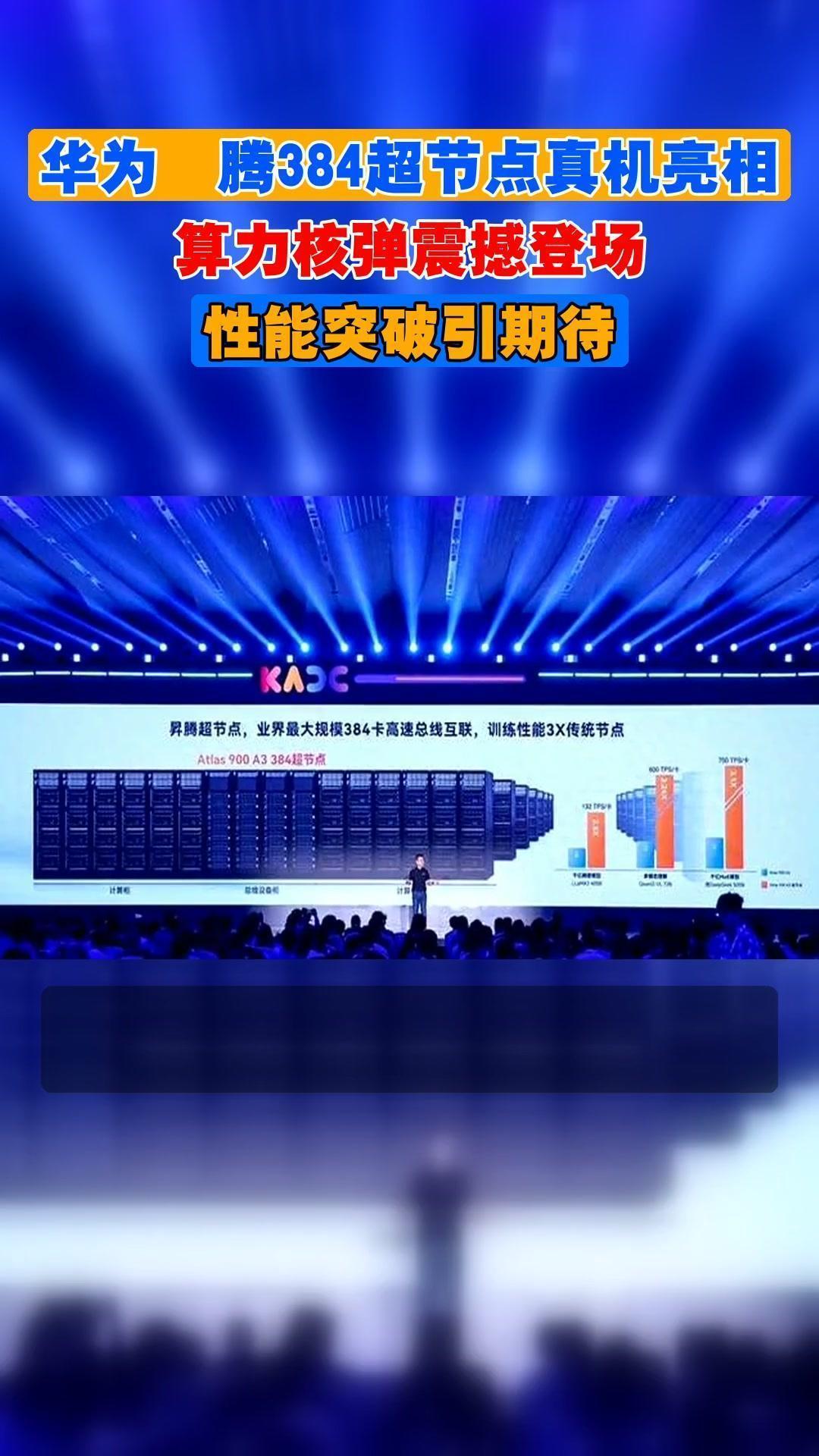
“核弹”!2.87倍!华为用一颗芯片,终结了美国对算力的统治! 3月22日,深圳坂田,华为中国合作伙伴大会2026现场。当昇腾计算业务总裁张迪煊公布那个数字时,全场掌声持续了整整三分钟。 Atlas 350 AI训练推理加速卡,搭载的正是华为2026年第一季度重磅推出的昇腾950PR芯片,在FP4低精度推理下,单卡算力达到1.56PFlops,第三方实测数据显示,这是英伟达H20的2.87倍。 这不是简单的性能提升,是一颗真正的“算力核弹”,直接炸穿了美国长达十年的算力垄断壁垒。 说实话,这个“2.87倍”的数字,比任何口号都来得实在。要知道,英伟达的H20芯片,已经是美国出口管制下能卖给中国市场的“顶配”了。 过去几年,国内无数AI公司和大模型团队,就是靠着这些被阉割过的“特供版”芯片,在算力紧箍咒下艰难前行。 每一次模型训练,都像戴着镣铐跳舞;每一次推理响应,都得多等那么零点几秒。 成本高、效率低,还得看人脸色。现在,华为直接把一张性能快三倍的牌甩在了桌上,意思很明白:以后这片赛场,规矩得改改了。 这颗“核弹”的核心,在于一个叫FP4的技术。你可以把它理解成一种“超级压缩包”。 以前AI计算,数据精度高,算得准但速度慢、耗电大。 FP4就是把数据精度大幅降低,用更少的“位数”来表示,牺牲一点点无关紧要的精度,换来的是计算速度和能效的爆炸式提升。 这就好比以前用高清无损格式传电影,现在发现用高度压缩的格式,画质肉眼几乎看不出差别,但传输速度快了好几倍,流量还省了一大半。 昇腾950PR是国内唯一支持这种“黑科技”的商用芯片,结果就是,一个700亿参数的大模型,原本需要140GB显存才能跑起来,现在用Atlas 350一张卡,35GB显存就能搞定。 这意味着什么?意味着以前需要堆好几张卡、搭复杂集群才能干的事,现在一张卡就可能办妥。AI推理的门槛和成本,咔嚓一下就降下来了。 当然,光有“压缩技术”不够,还得有强大的“内存”和“搬运工”。 华为这次祭出了自研的HBM(高带宽内存),容量112GB,比H20多了16%,相当于给芯片配上了更宽敞、更高速的“仓库”和“传送带”。 更绝的是,他们把数据搬运的“最小包裹”从512字节缩小到了128字节。AI计算里充斥着海量细碎的小任务,以前搬一次货是个“大箱子”,效率低;现在换成“小包裹”,随用随取,搬运效率直接提升了4倍。 这些看似微小的改进叠加起来,就让Atlas 350在处理推荐系统、视频生成、大模型对话这些实时推理任务时,又快又稳。 但华为的野心,远不止于造出一张比H20强的卡。真正的杀招,藏在“系统”里。单卡性能领先固然提气,可面对动辄万亿参数的未来模型,单打独斗永远不够。 华为早就布好了局,Atlas 950 SuperPoD超节点。 简单说,就是用自研的“灵衢”全光互联技术,把8192张昇腾950芯片像搭乐高一样连成一个超级大脑。在这个集群层面,其总算力号称能达到英伟达顶级集群NVL144的6.7倍。 这就像是从“比拼单个武士的武力值”,升级到了“比拼整个军团的排兵布阵和协同作战能力”。 美国可以限制最先进的单颗芯片流入,却无法限制这种基于自主技术构建的系统级创新能力。 这才是打破垄断的深层逻辑:不只在点上突破,更要在体系和生态上另起炉灶。 生态,恰恰是过去国产芯片最被诟病的软肋。芯片造出来,没人用、不会用,就是一块昂贵的硅片。 但这次大会,你看到的是完全不同的景象:昆仑、华鲲振宇、神州鲲泰等七家核心硬件伙伴,同步发布了基于Atlas 350的整机服务器,这意味着产品不是PPT,而是立刻能下单采购的现货。 华为自己的MindSpore开源框架,正在拼命完善工具链,降低开发者从英伟达CUDA生态迁移过来的成本。一个从芯片、到硬件、到软件、再到应用场景的国产算力闭环,正在以前所未有的速度成型。 所以,昇腾950PR的发布,绝不仅仅是一次产品迭代。它是一个清晰的信号,宣告了中国AI算力自主之路,已经从“解决有无”的求生阶段,迈入了“追求好用”的竞争阶段。 它告诉所有人,在推理这个占据AI应用成本大头的战场上,我们有了不输于人的选择,甚至在某些特定场景下,有了更优的选择。未来的竞争,将是集群对集群、生态对生态的全面较量。 当然,必须清醒看到,在最顶尖的AI训练芯片领域,在庞大的软件开发者生态上,我们与英伟达这样的巨头仍有差距。 但重要的是,通往山顶的路已经打通,并且我们正在自己的道路上加速奔跑。 这颗“算力核弹”炸开的,不只是一项性能纪录,更是一片属于中国AI产业的、广阔而自主的新天空。 参考:华为发布新一代算力芯片——证券时报