字节Seed首次开源代码模型字节Seed开源代码模型夺SOTA
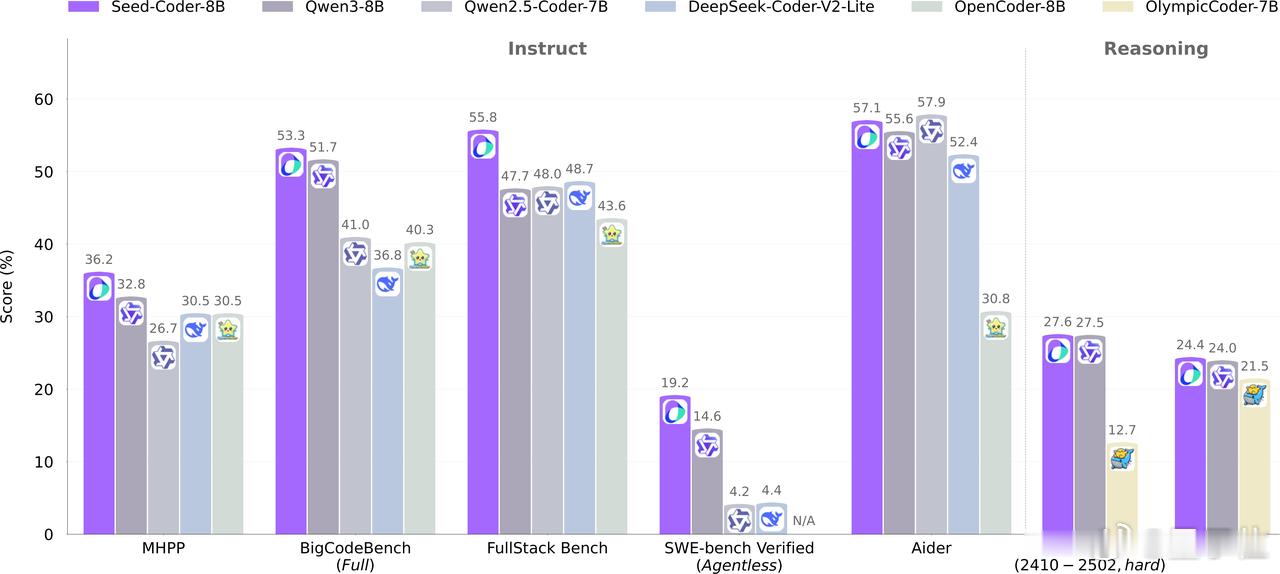
字节跳动的Seed团队,首次开源了他们的代码大模型——Seed-Coder,参数规模8B,在多个权威基准上击败了Qwen3、DeepSeek-R1,夺得SOTA成绩。
Seed-Coder共发布了三个版本:
- Base:基础模型
- Instruct:强化指令理解,通过监督微调+偏好优化,提升模型“听懂人话”的能力
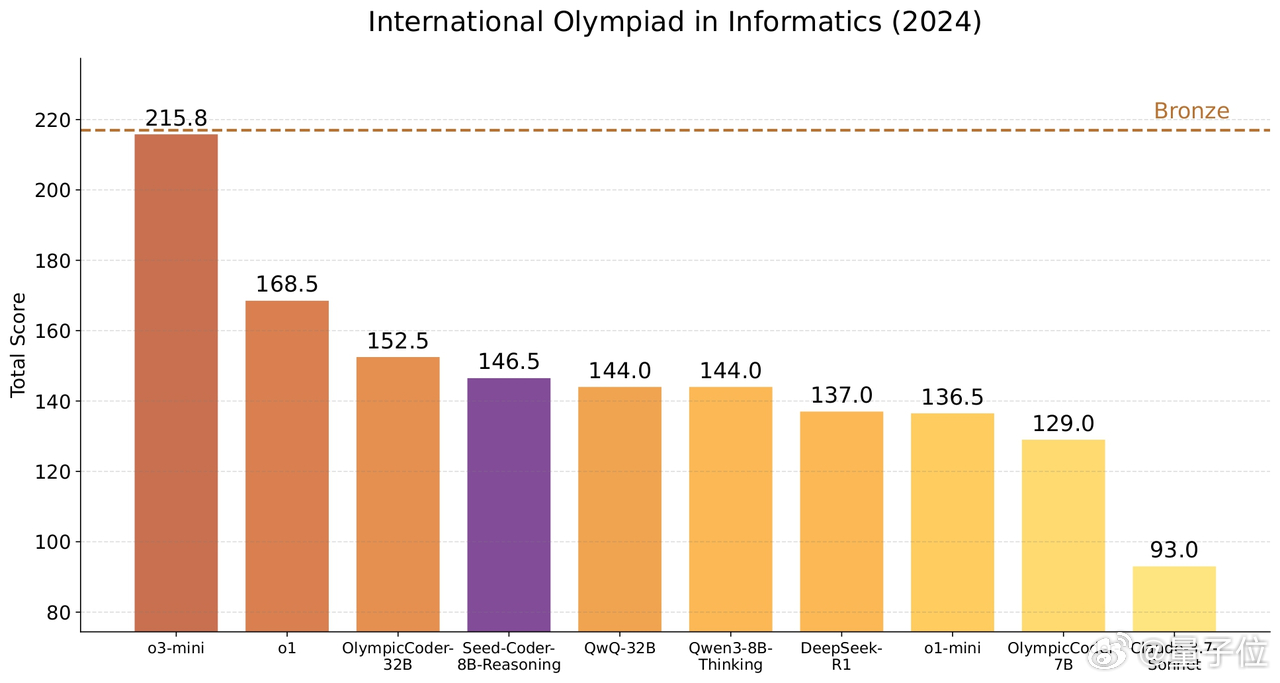
- Reasoning:面向复杂推理任务,采用强化学习的方式,锻炼多步推理能力,在IOI 2024超过QwQ-32B
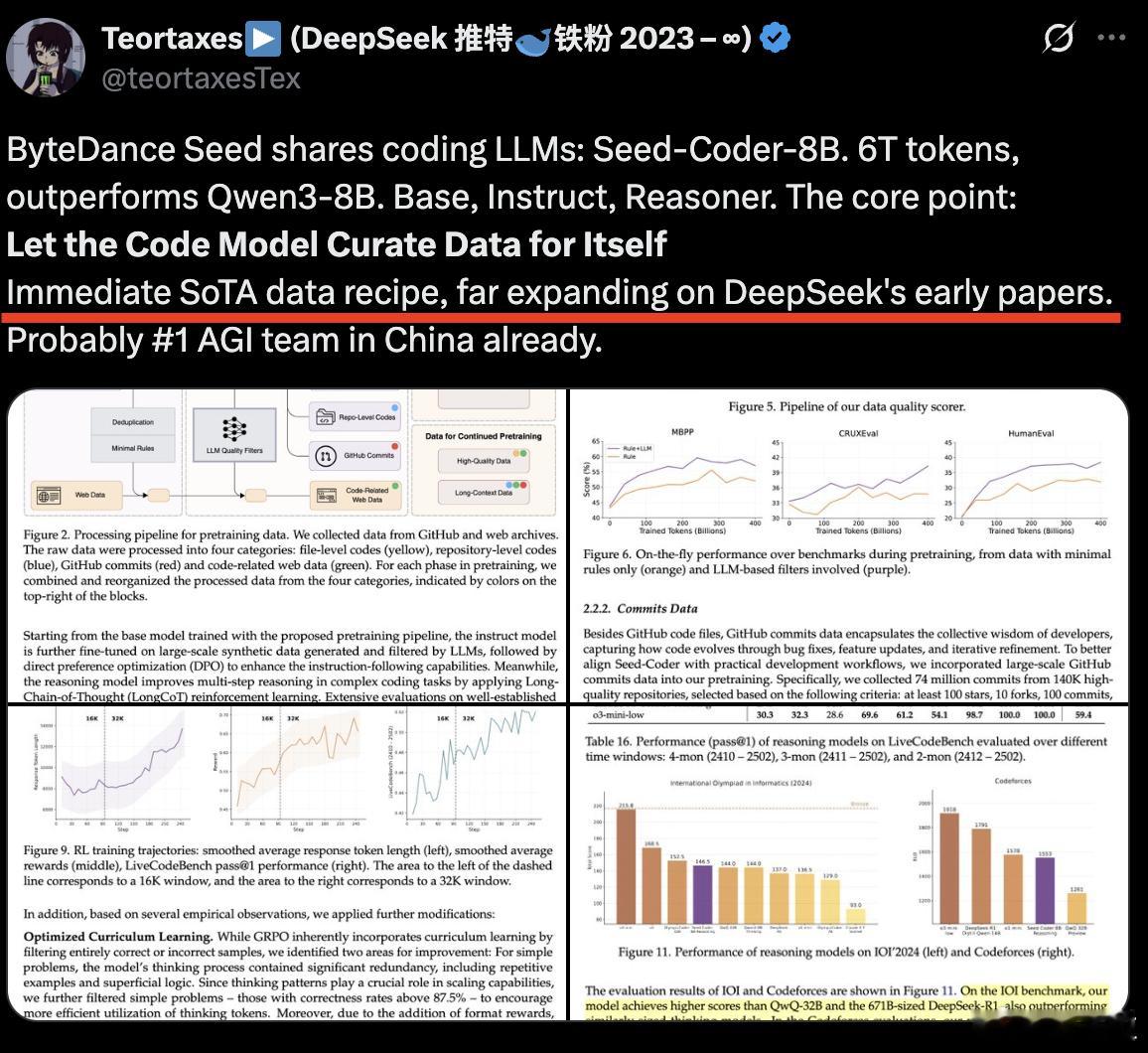
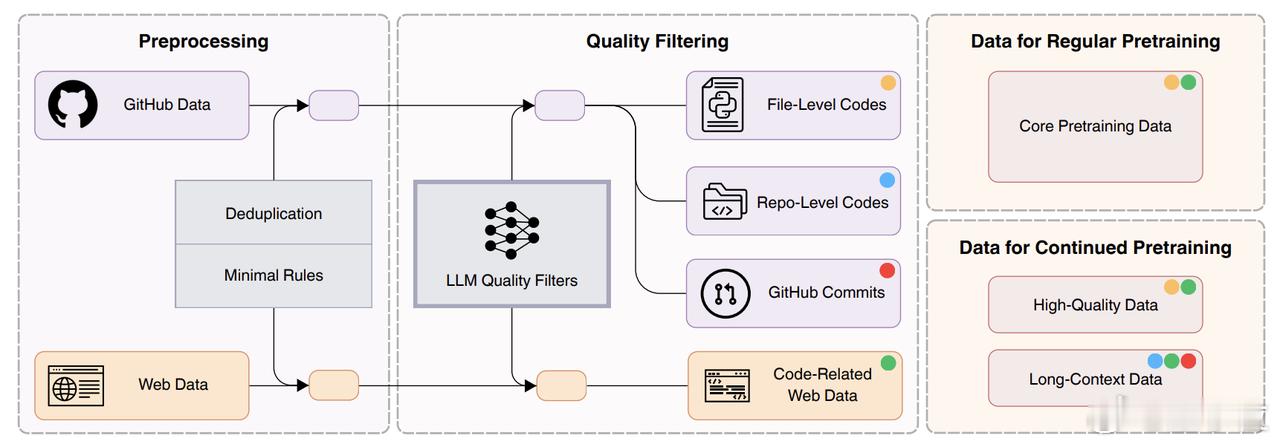
这个模型的特别之处在于,团队提出了“用小模型自管数据”的新范式,也就是模型自己策划训练数据,连生成和筛选都由模型完成,人工干预极少,具体方式包括:
1. 四类高质量数据源:
- 文件级代码:从GitHub提取单个文件内容
- 仓库级代码:保留项目结构关系
- Git Commit:覆盖7400万次提交,格式化为代码变更预测任务
- 网络代码相关内容:从网页提取结构化和非结构化代码信息
2. 数据去重与筛选:
- SHA256+MinHash双重去重
- 使用语法解析器排除错误代码
- 通过LLM评分模型评估代码可读性、模块性等质量维度
3. 定制化评分机制:
- 针对不同网站内容风格(博客/论坛)制定不同评分标准,避免误判有价值内容
目前完整代码和模型均已开源: