三图解析RAG两大技术路线传统RAG与智能体RAG的核心差异
你是否还不清楚传统RAG和智能体RAG两大技术路线的核心差异?
简单来说,传统RAG就像一次性问答,而智能体RAG更像是会反复思考的对话。下面用三张图带你看懂这个技术升级。
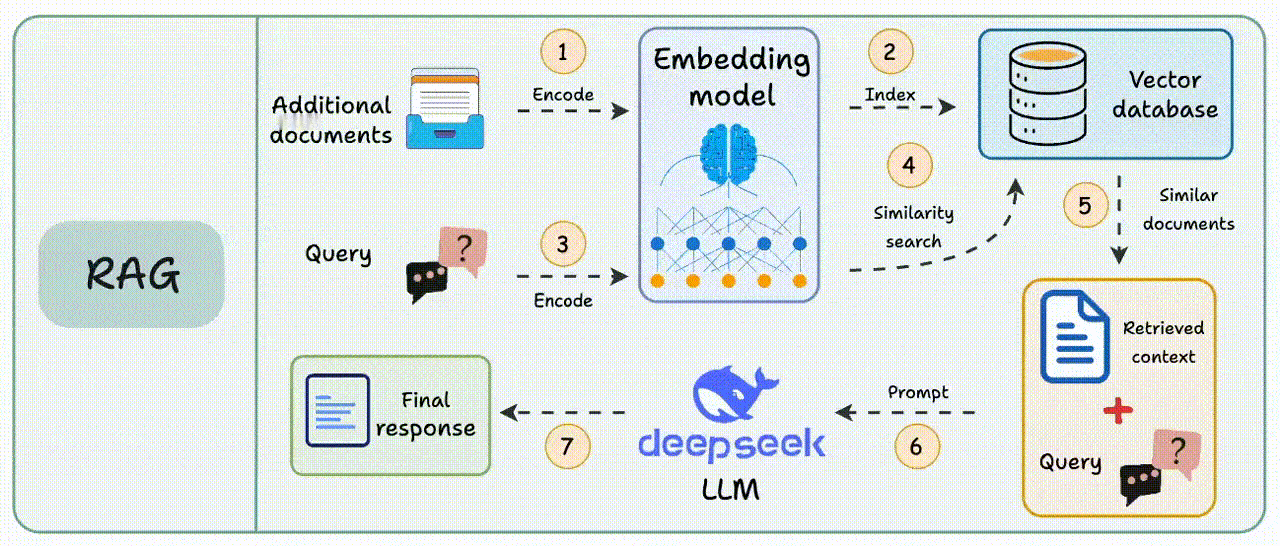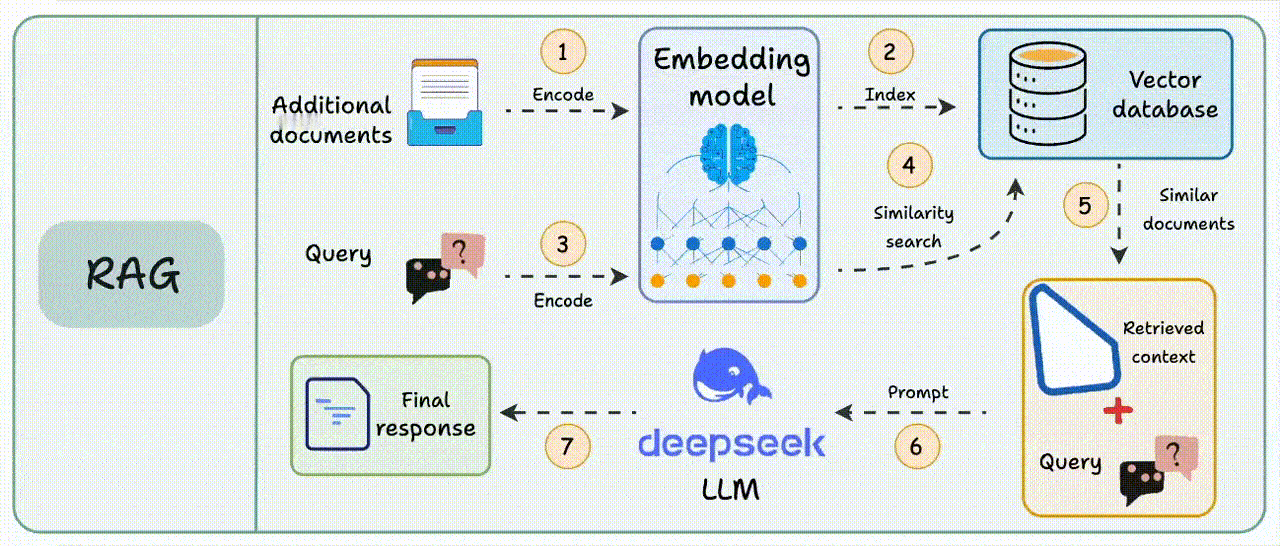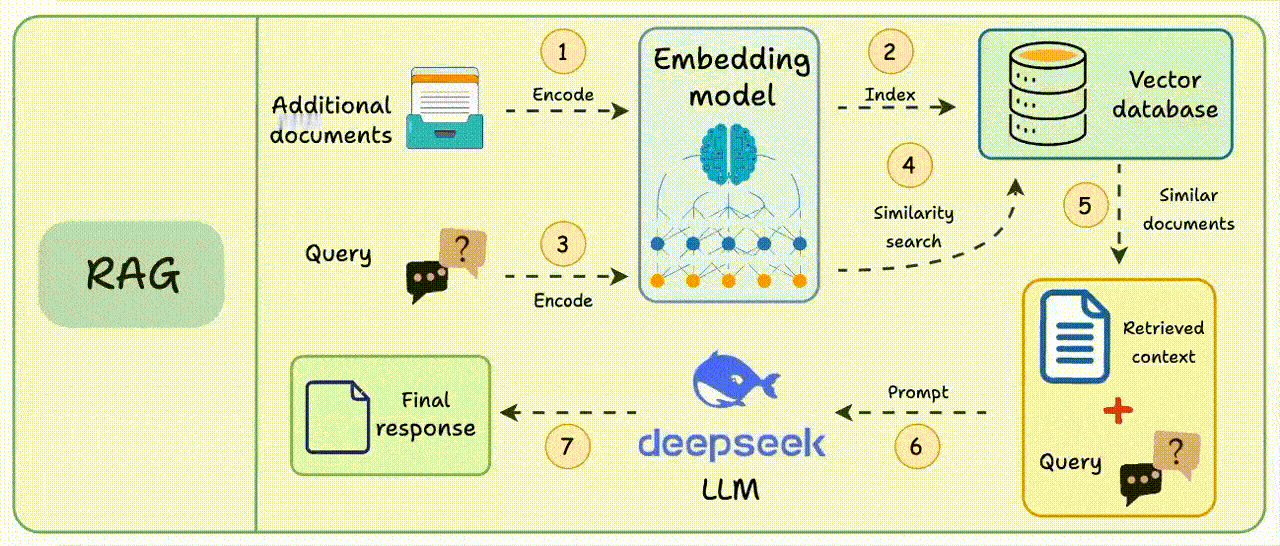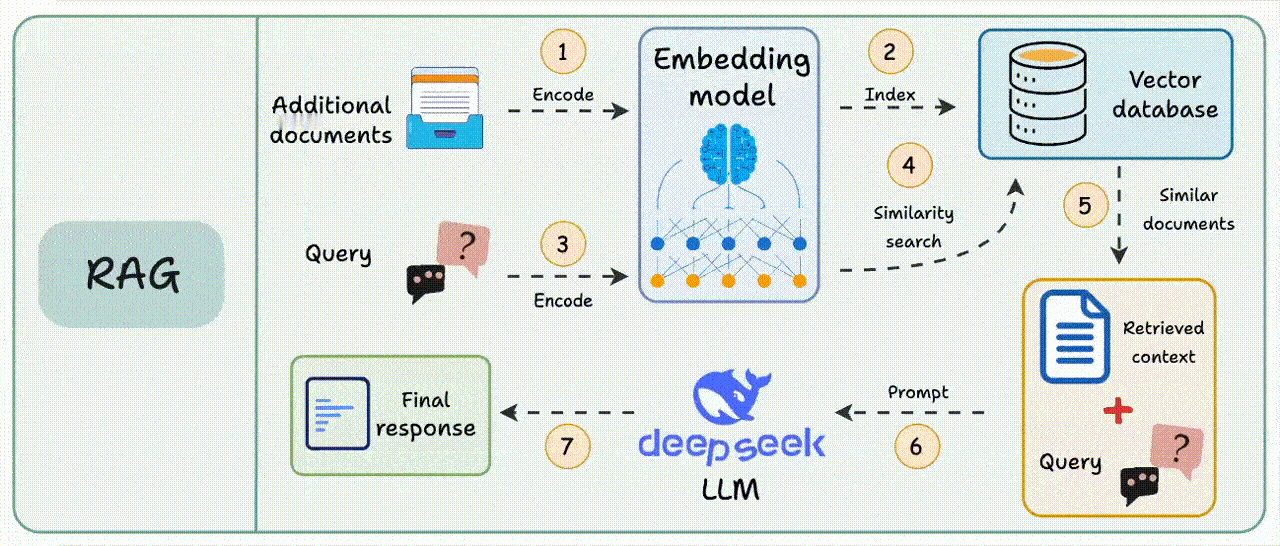
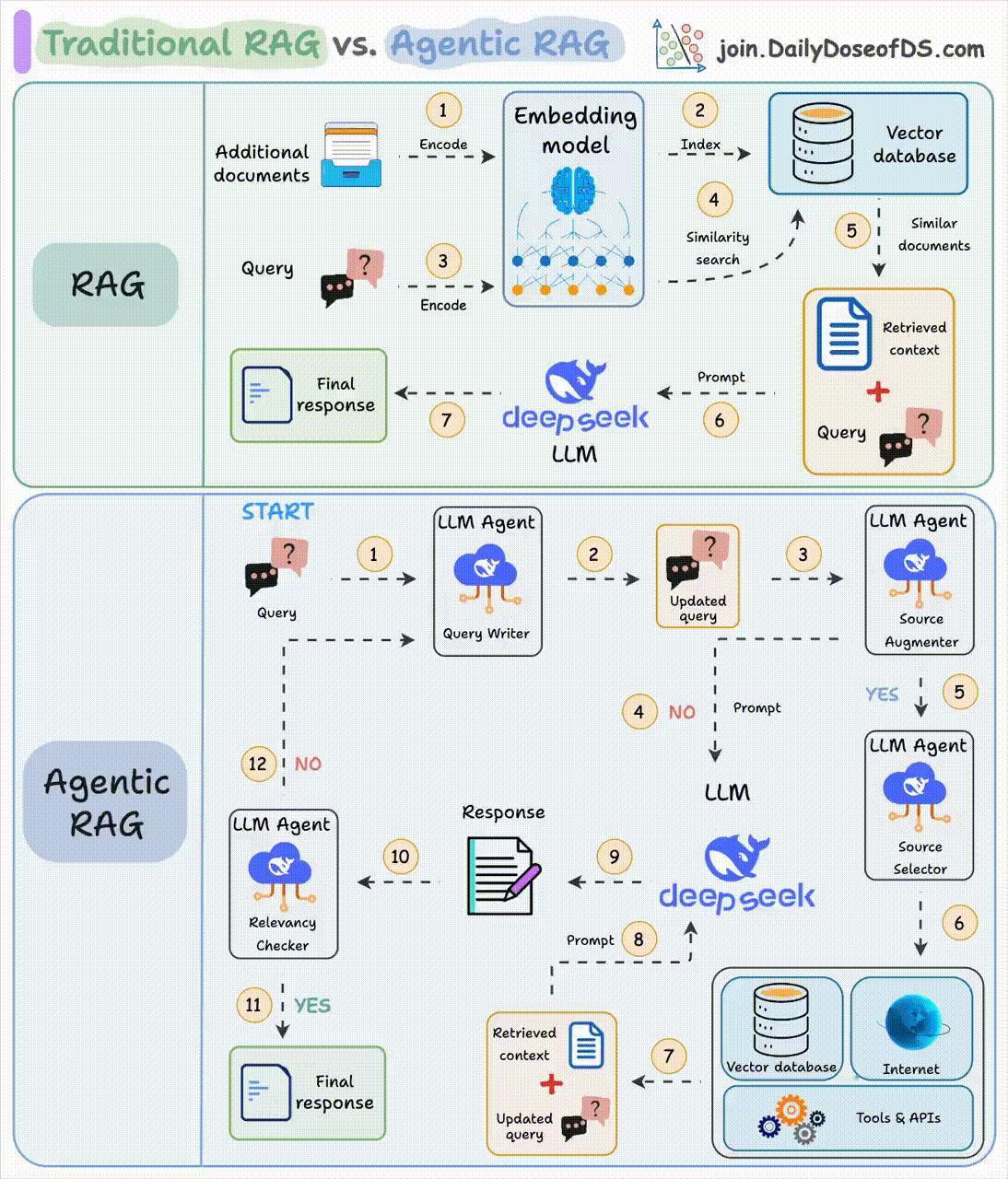
在传统RAG的检索过程中,用户提出的问题会被转换为向量,根据向量相似度,从数据库中查询最相关的文本片段,生成模型会结合检索到的上下文和原始查询生成答案。【图1】
但这样做有三个明显短板:
1. 单次检索单次生成:如果第一次找的资料不够,系统不会自己补充
2. 缺乏复杂推理能力:遇到需要多步推理的问题就容易卡壳
3. 处理方式固定:不管什么问题都用同一种方法解决
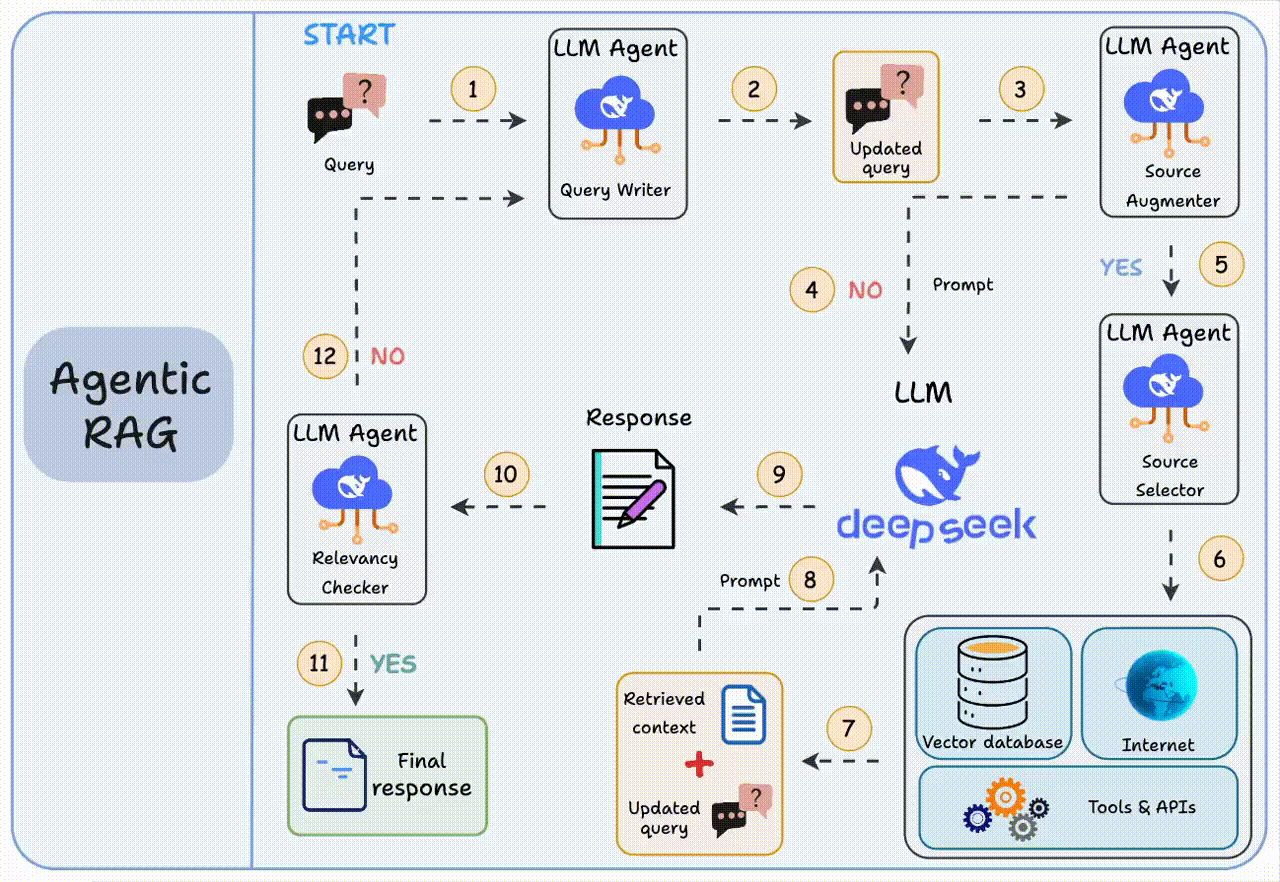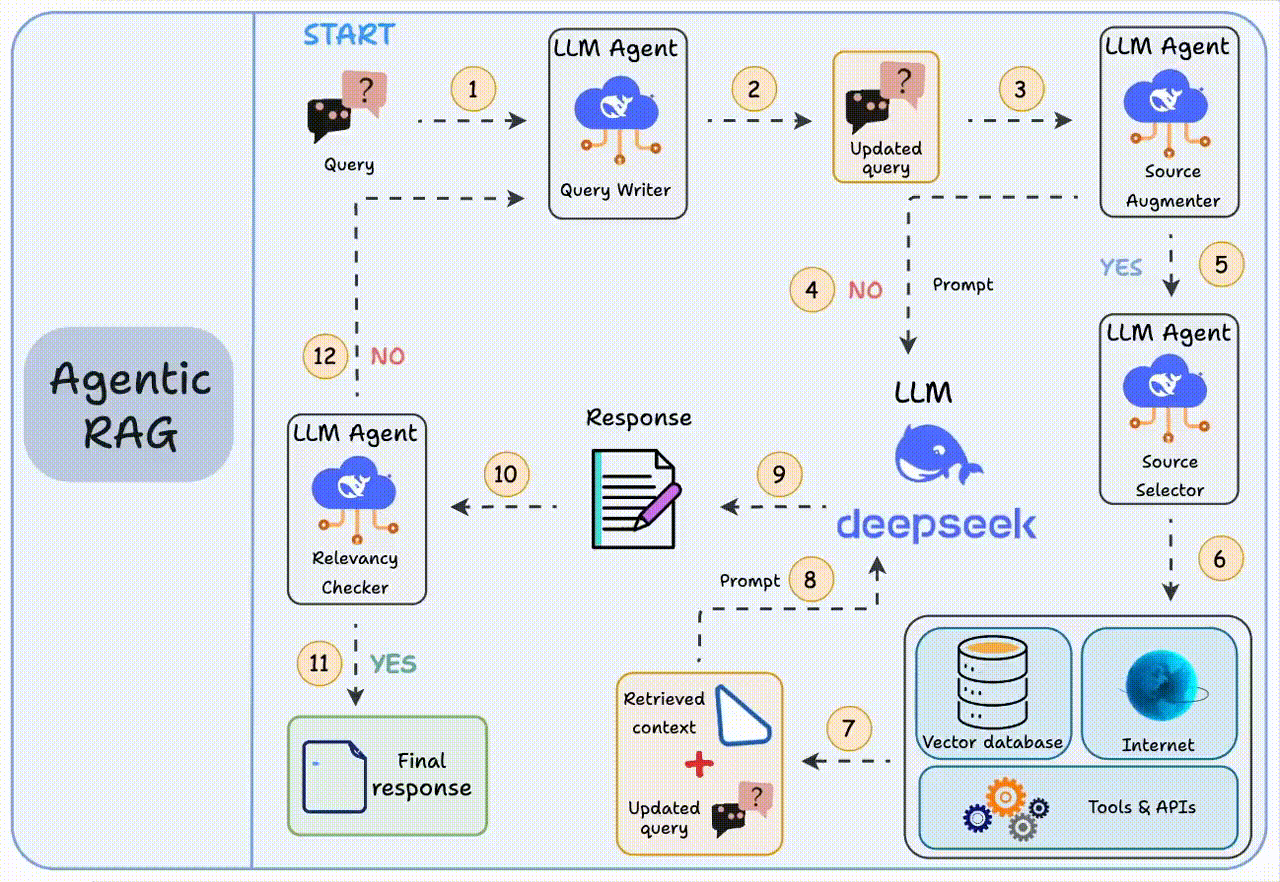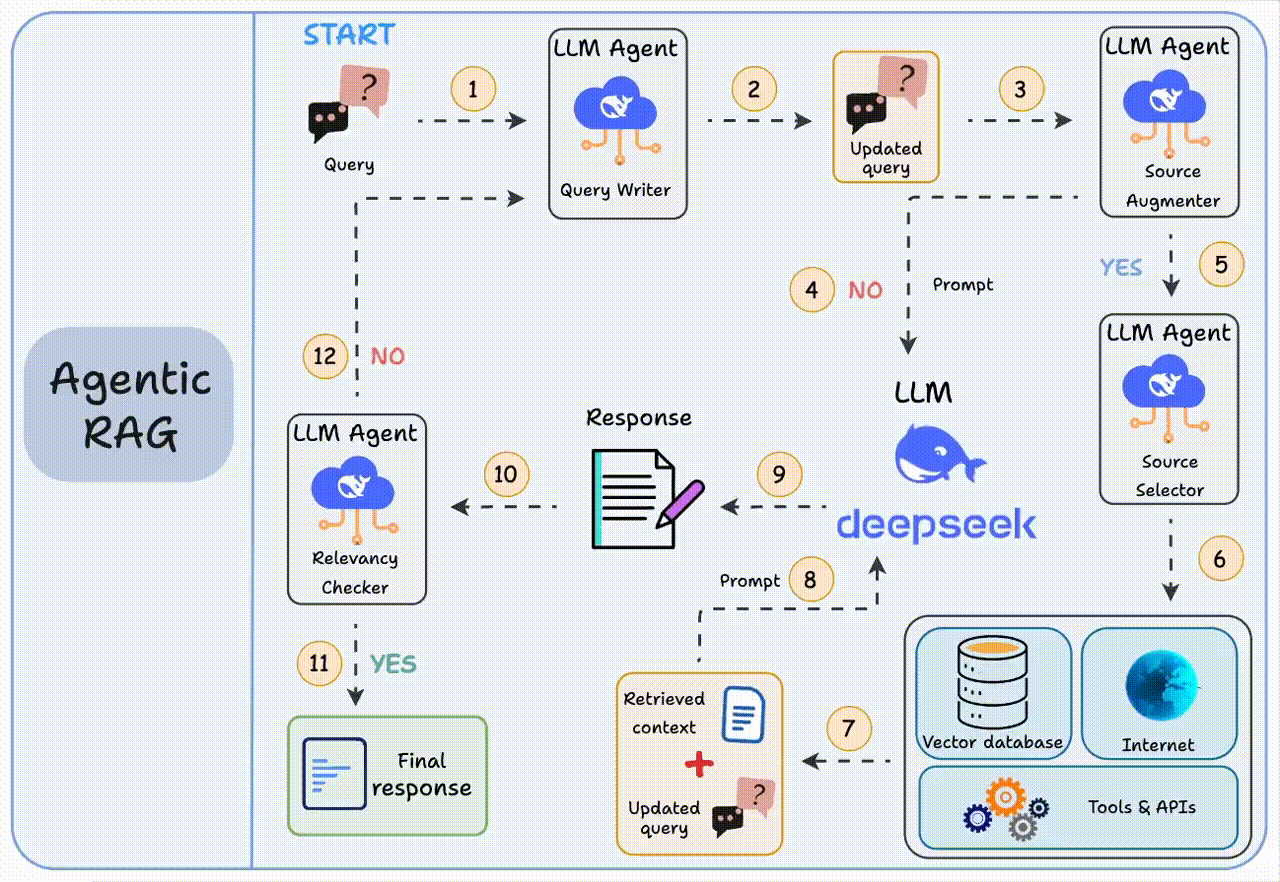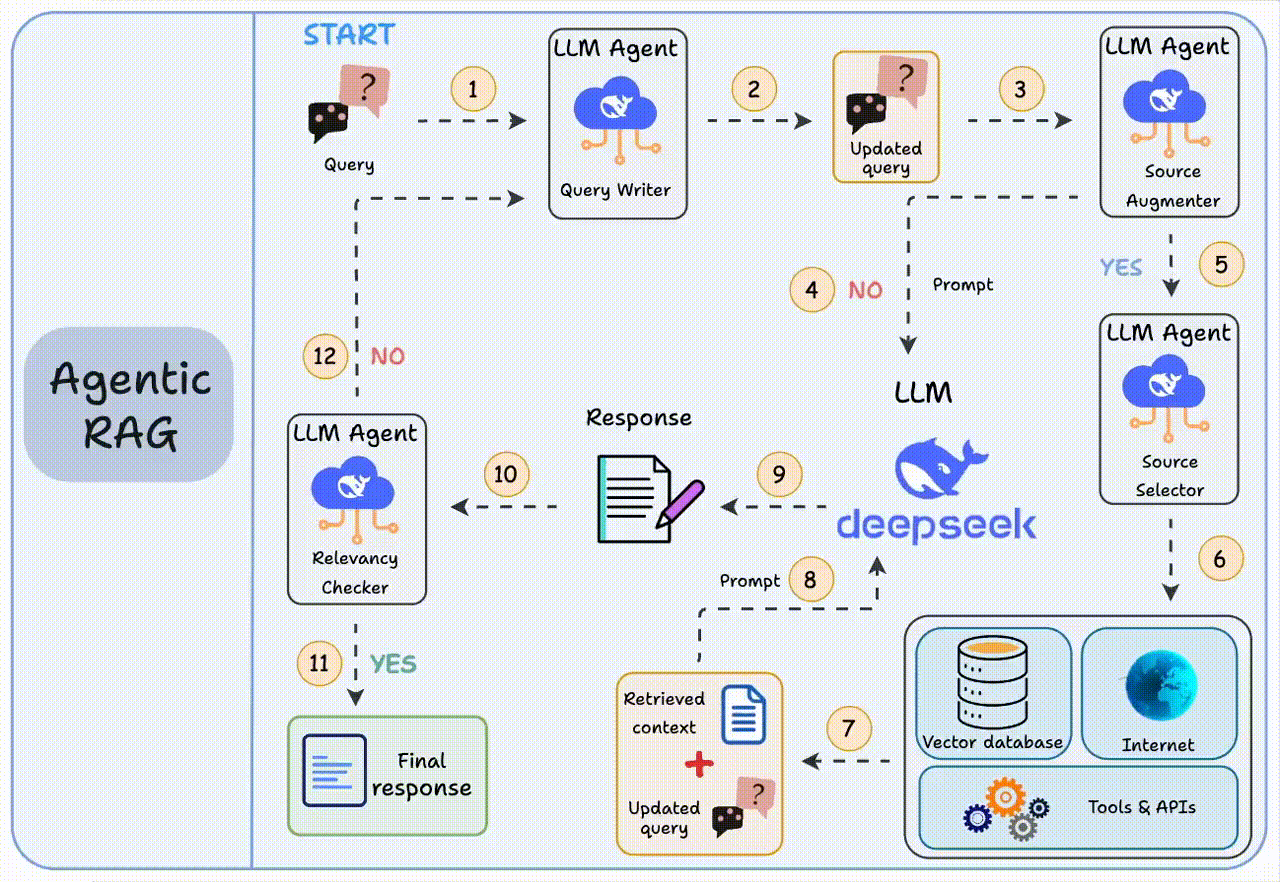
而智能体RAG就通过引入智能体,来解决这三个短板:【图2】
1. 步骤1-2:先帮你优化问题,比如自动改正错别字
2. 步骤3-8:判断是否需要补充上下文。若不需要,将优化后的查询直接发送给大模型;若需要,智能体将会自己去找合适的参考资料
3. 步骤9-12:获得初始响应后,智能体验证答案相关性:若相关,返回最终答案;若不相关,返回步骤1重新执行
这个“思考-验证-调整”的过程会循环几次,直到给出满意答案或确认真的回答不了。
这就相当于给系统装了个“质检员”,RAG的鲁棒性得到了提升,每个环节都朝着给出好答案的目标努力。