[CL]《Reasoning-Driven Synthetic Data Generation and Evaluation》T R. Davidson, B Seguin, E Bacis, C Ilharco… [EPFL & Google] (2026)
在专用AI领域,高质量训练数据极度稀缺——人工标注成本高昂、隐私敏感场景无法触及,而现有合成数据方案要么依赖手工提示难以规模化,要么基于随机演化缺乏透明度,根本原因是没有人将"数据如何生成"视为独立的工程问题。
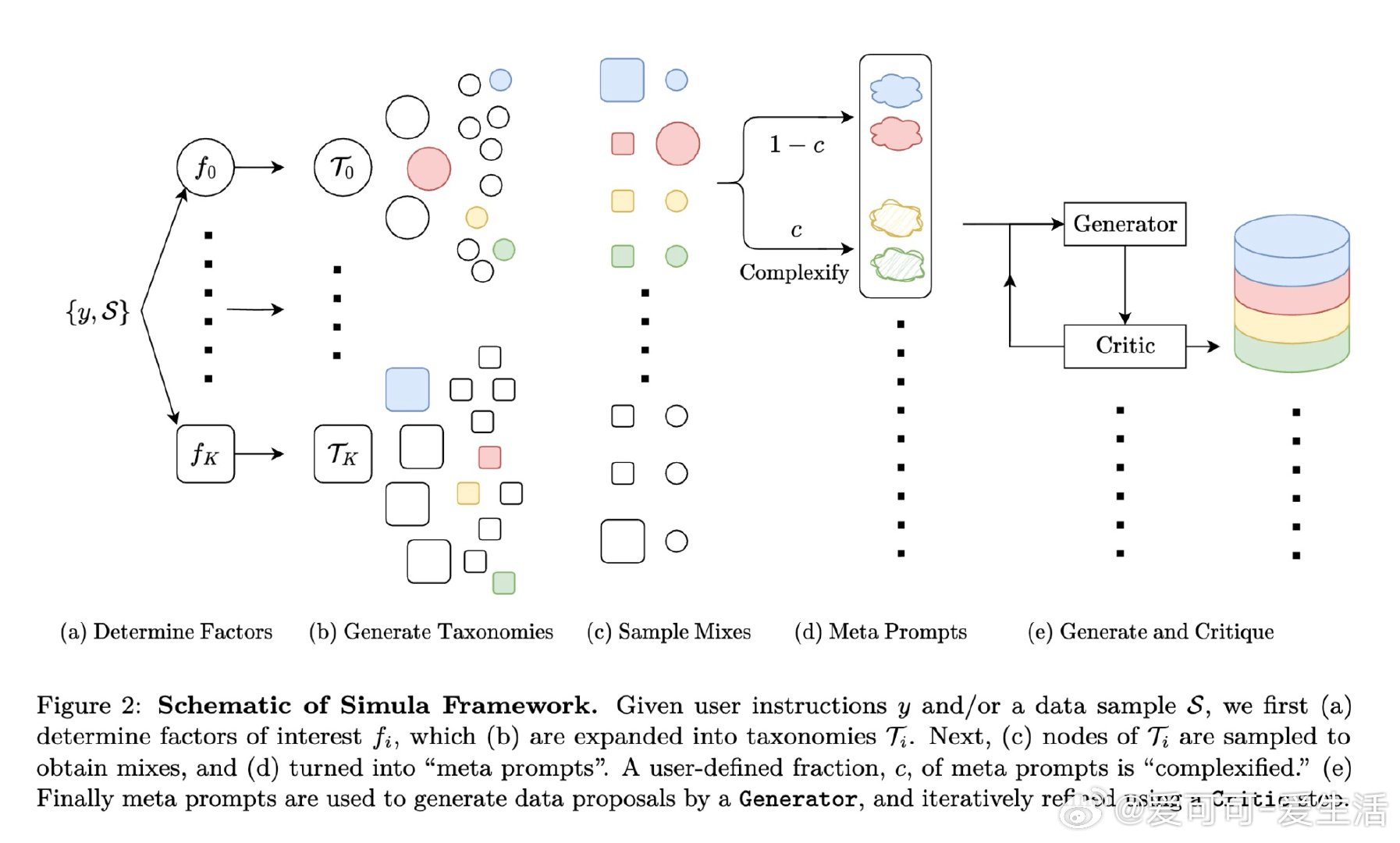
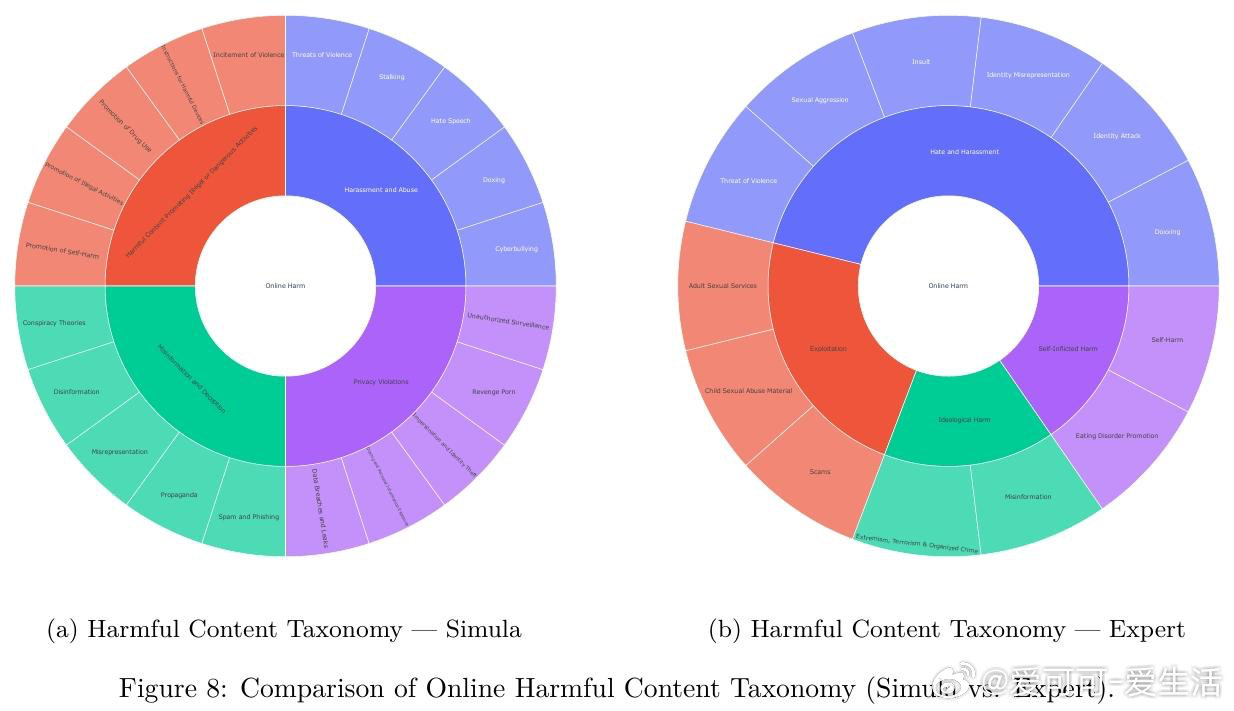
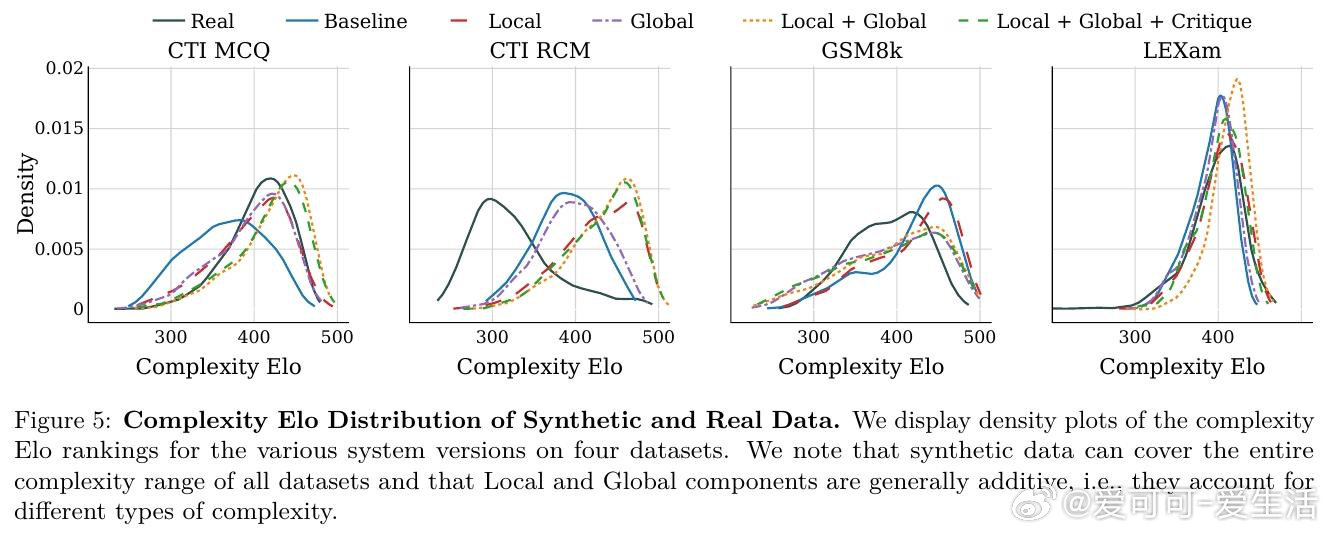
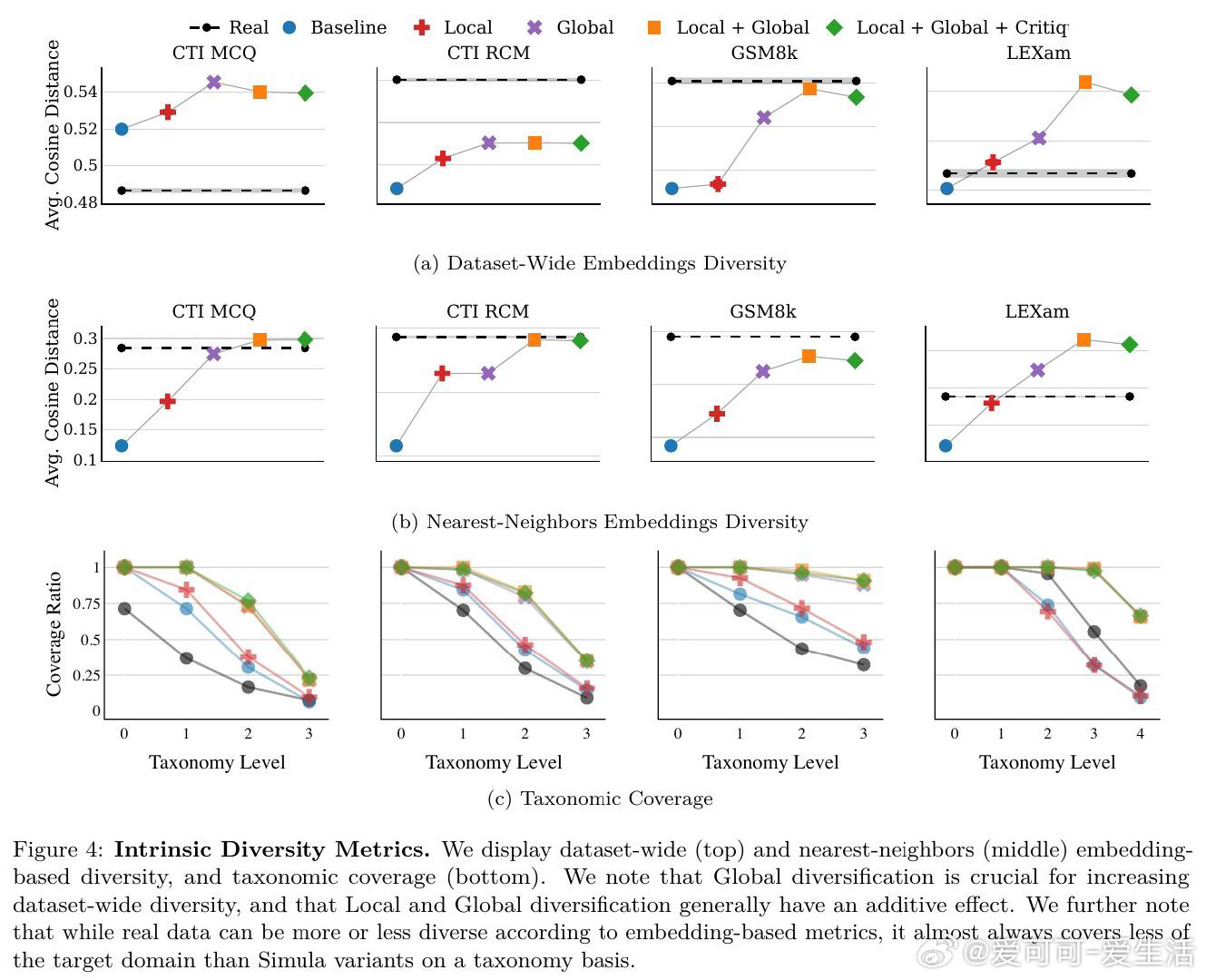
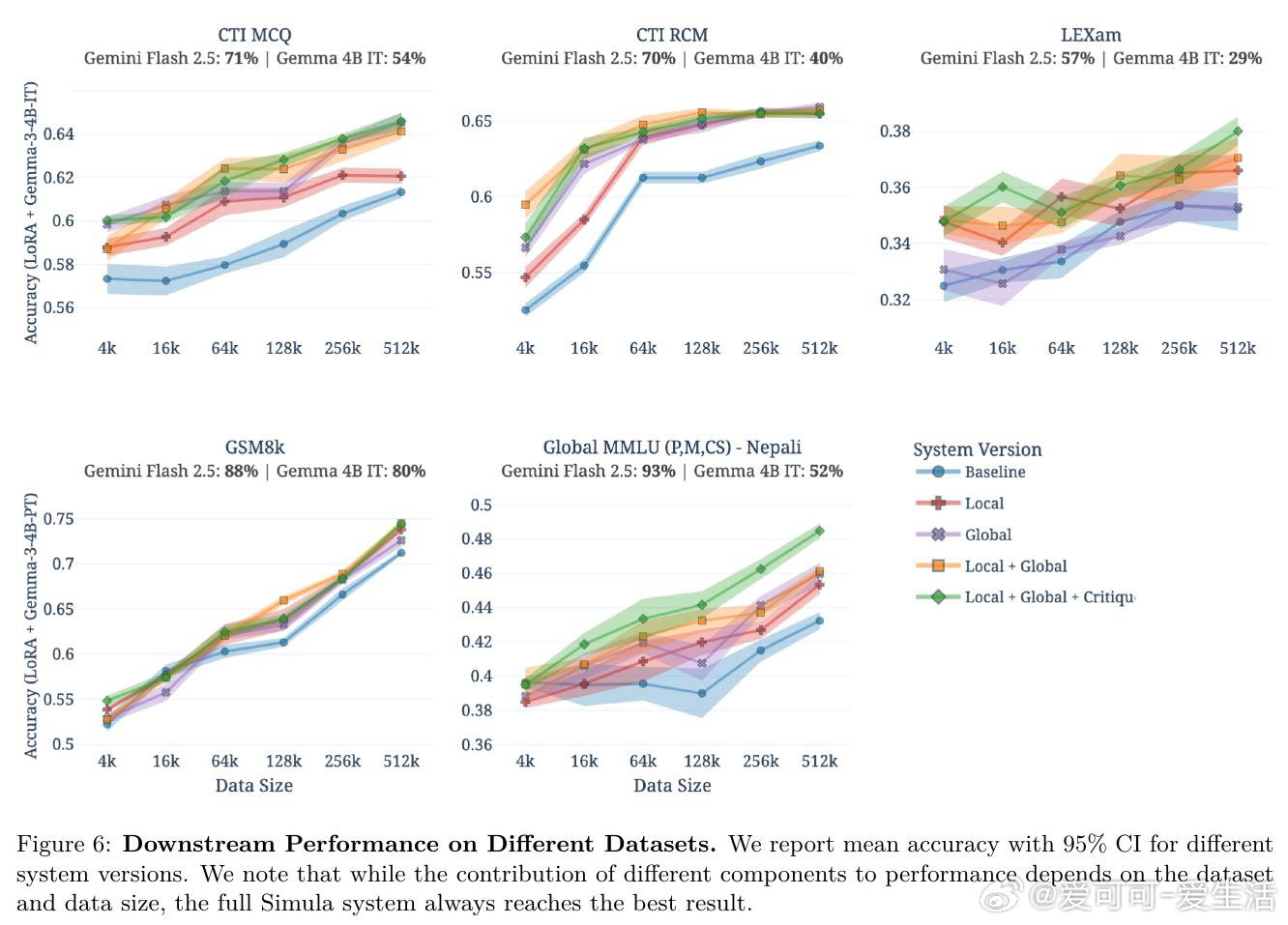
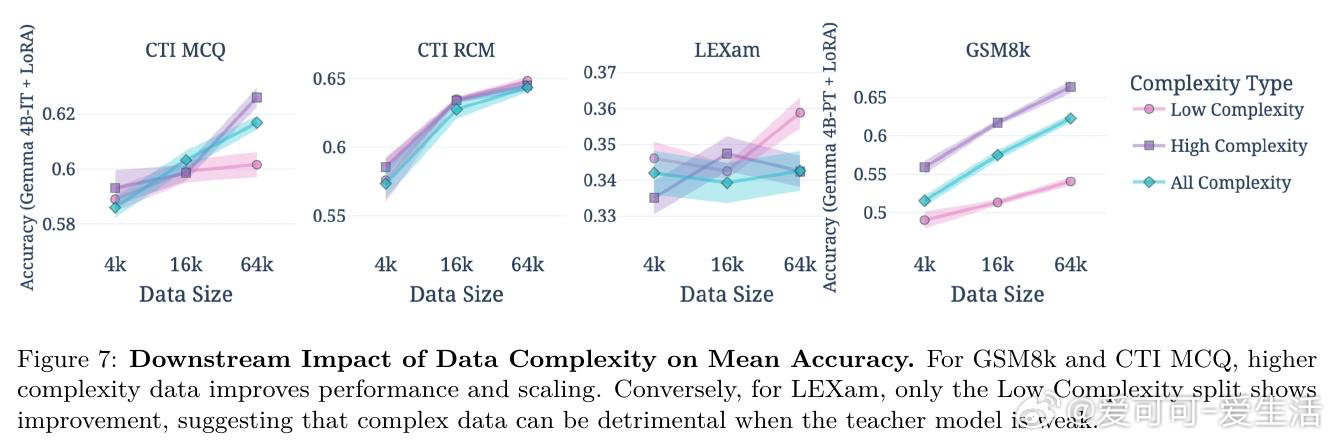
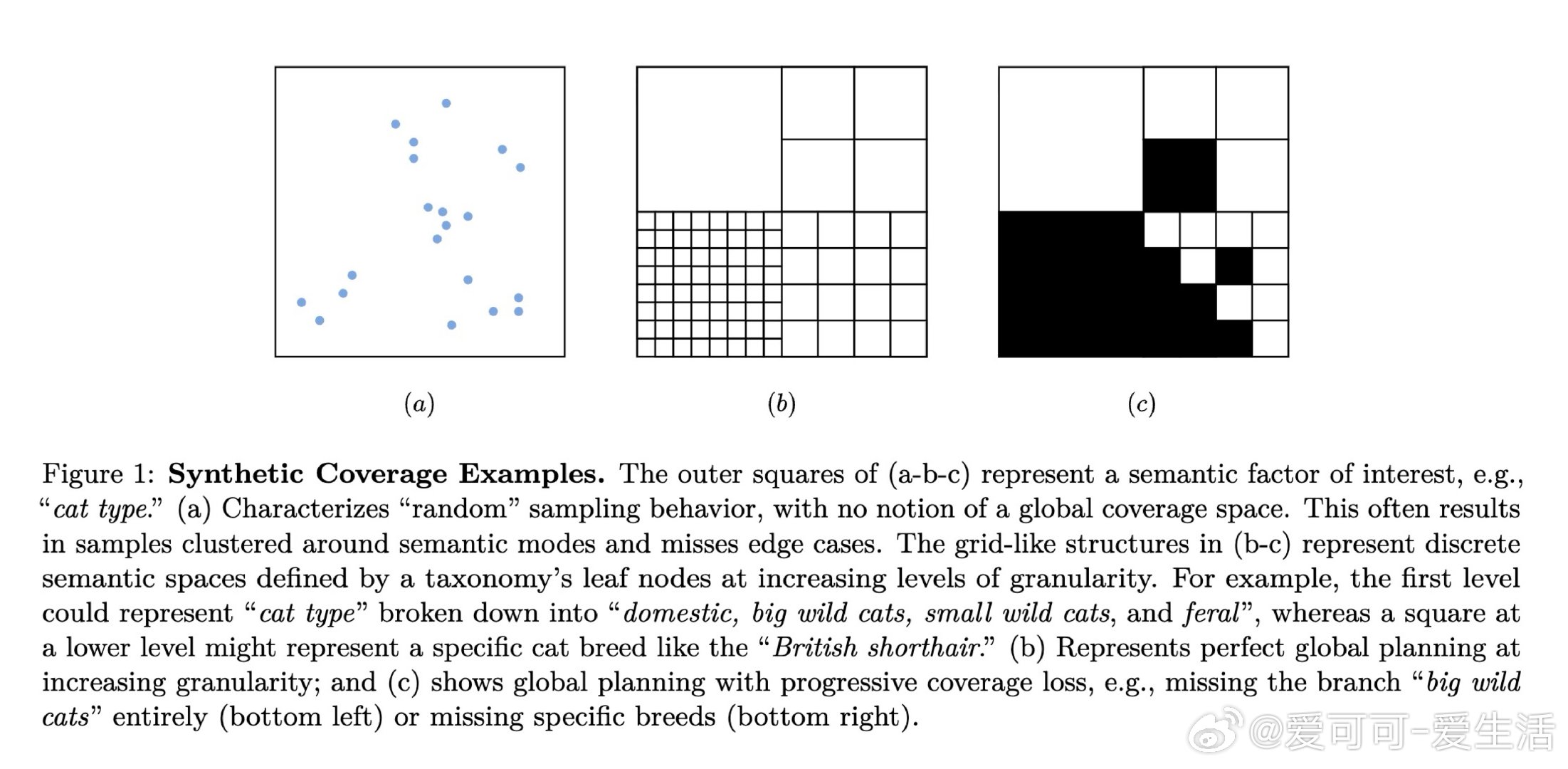
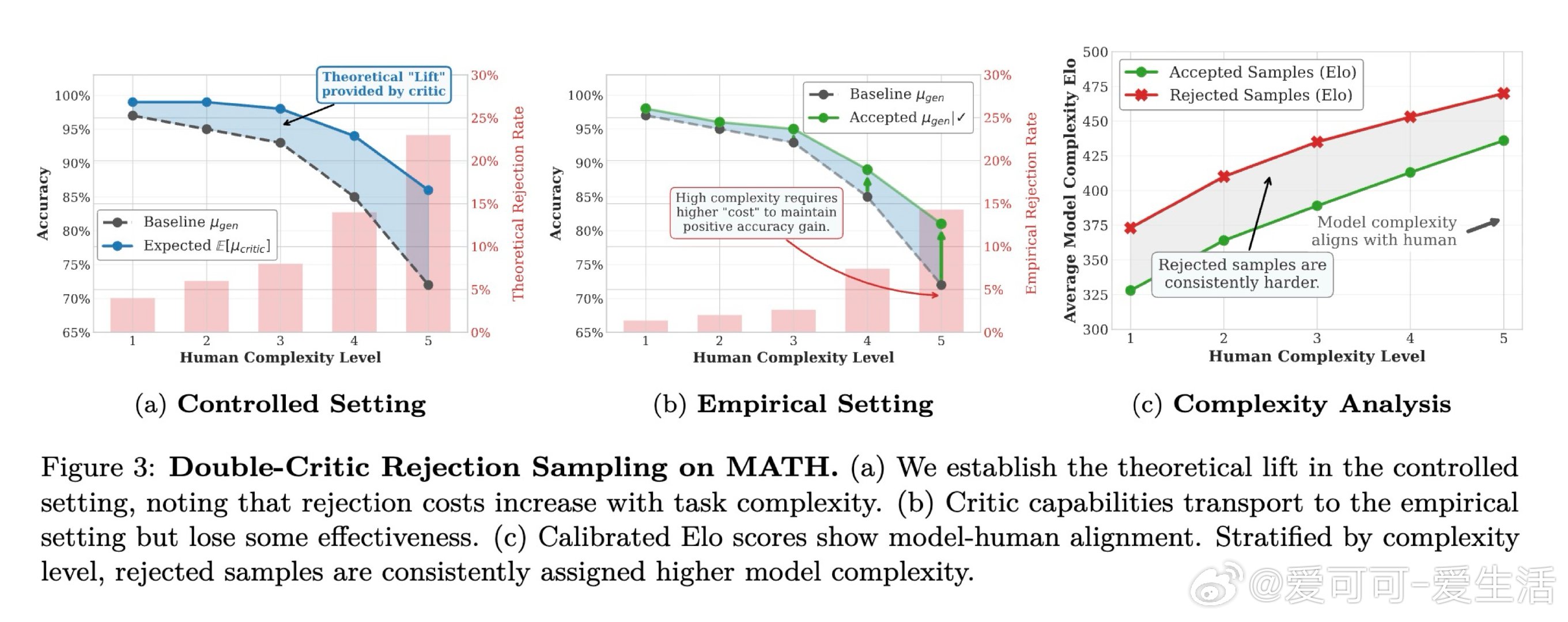
本文的核心洞见是:把"生成一个数据集"重新看作"对概念空间的系统性覆盖问题"。由此,用分类树锚定全局多样性、用智能体迭代扩展局部多样性、用双重批评者过滤质量这一三段式流水线,使可解释、可控、可扩展的合成数据生产成为现实。
这项工作真正留下的遗产是:将机制设计确立为合成数据研究的独立轴——与"好数据是什么"同等重要。它为后来者打开的新门是:在数据稀缺或隐私敏感的垂直领域(法律、网络安全)构建专用模型的可行路径;但尚未跨过的门槛是:框架仍限于文本单模态,且重度依赖教师模型能力上限,弱教师反而会因高复杂度数据拖累学生表现。
arxiv.org/abs/2603.29791
机器学习 人工智能 论文 AI创造营