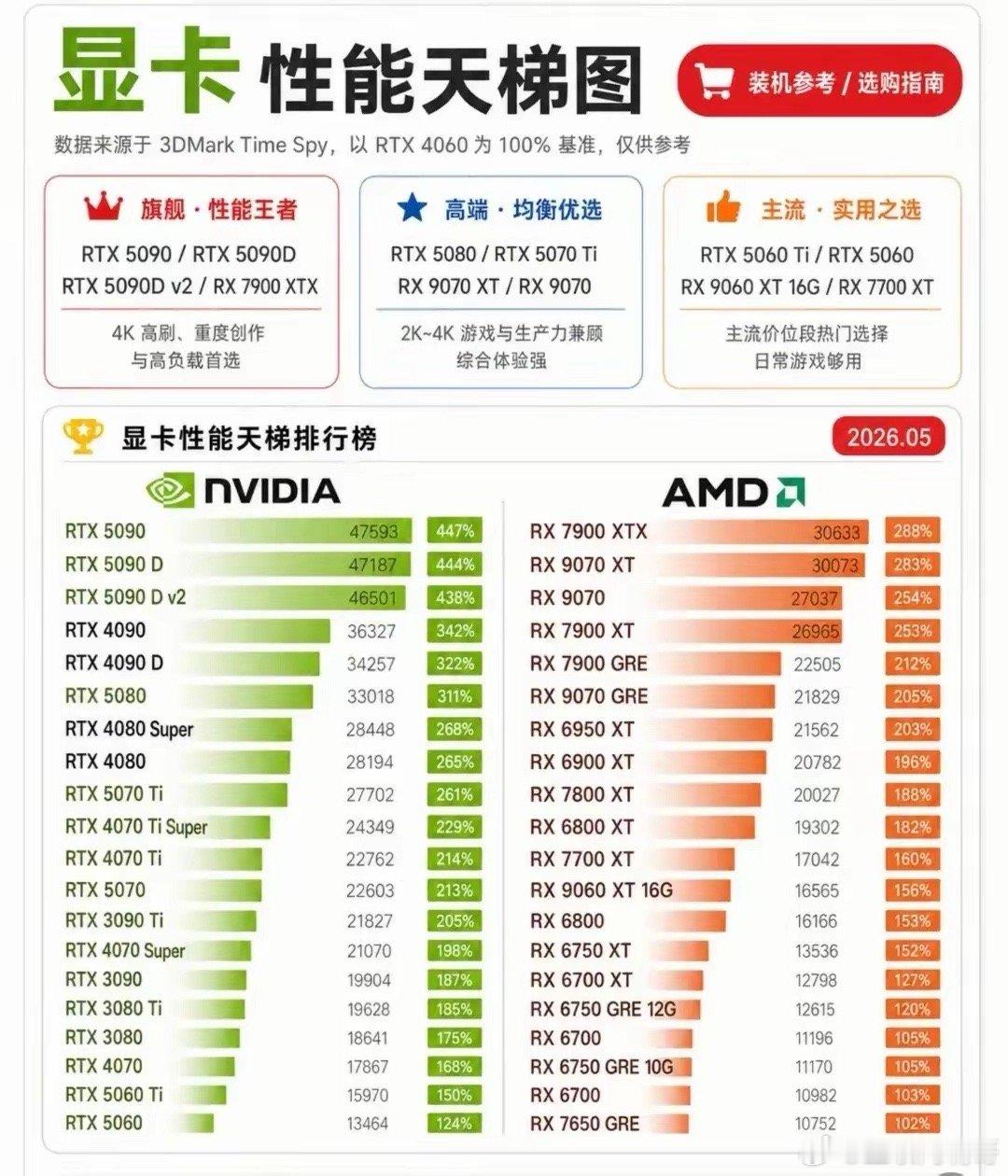
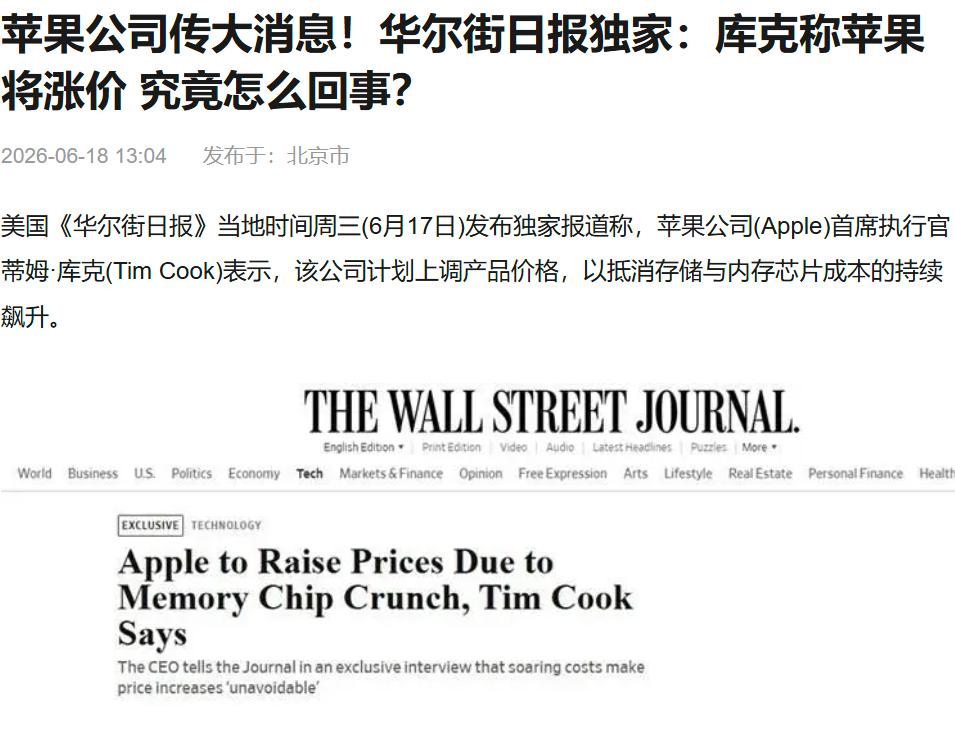
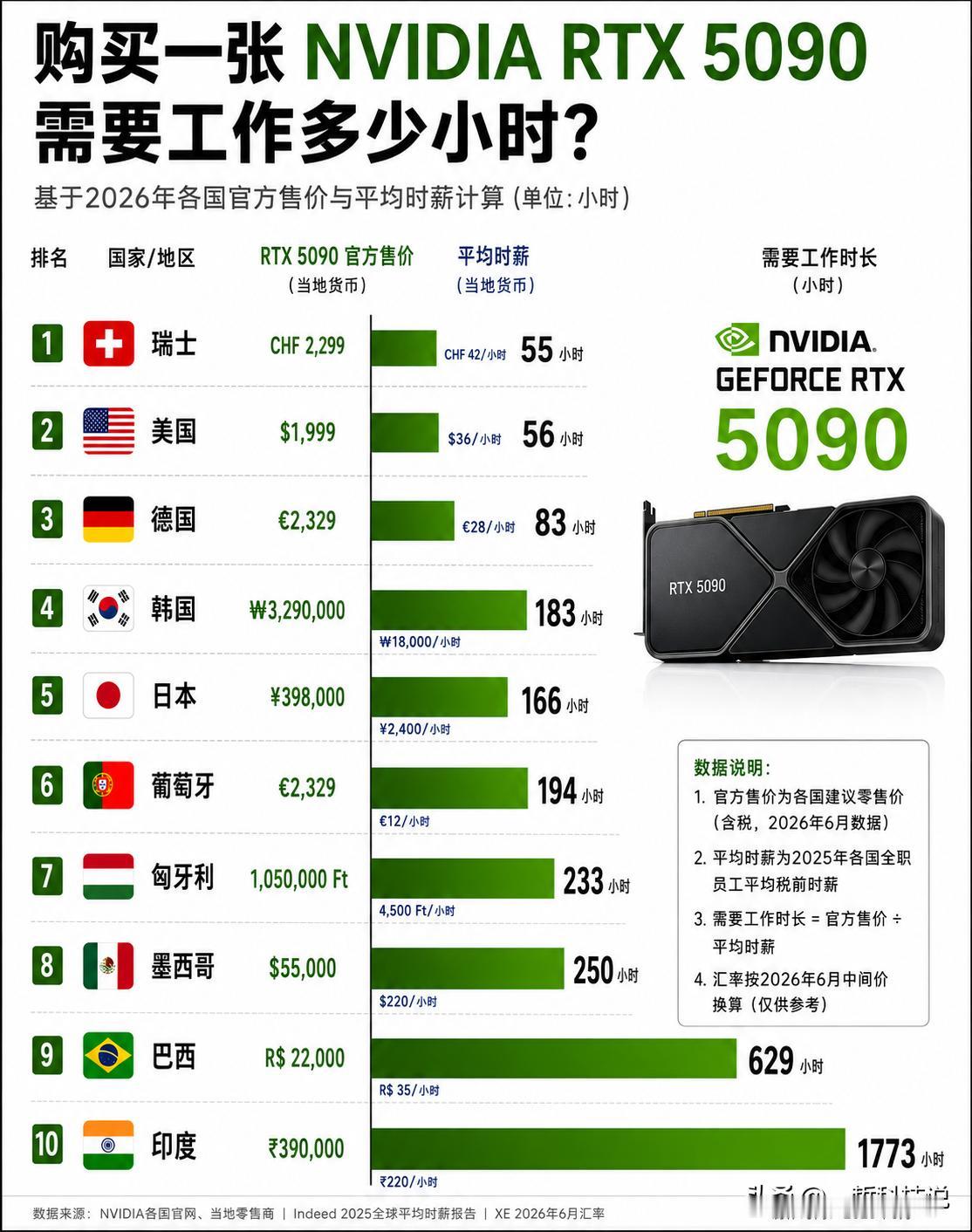
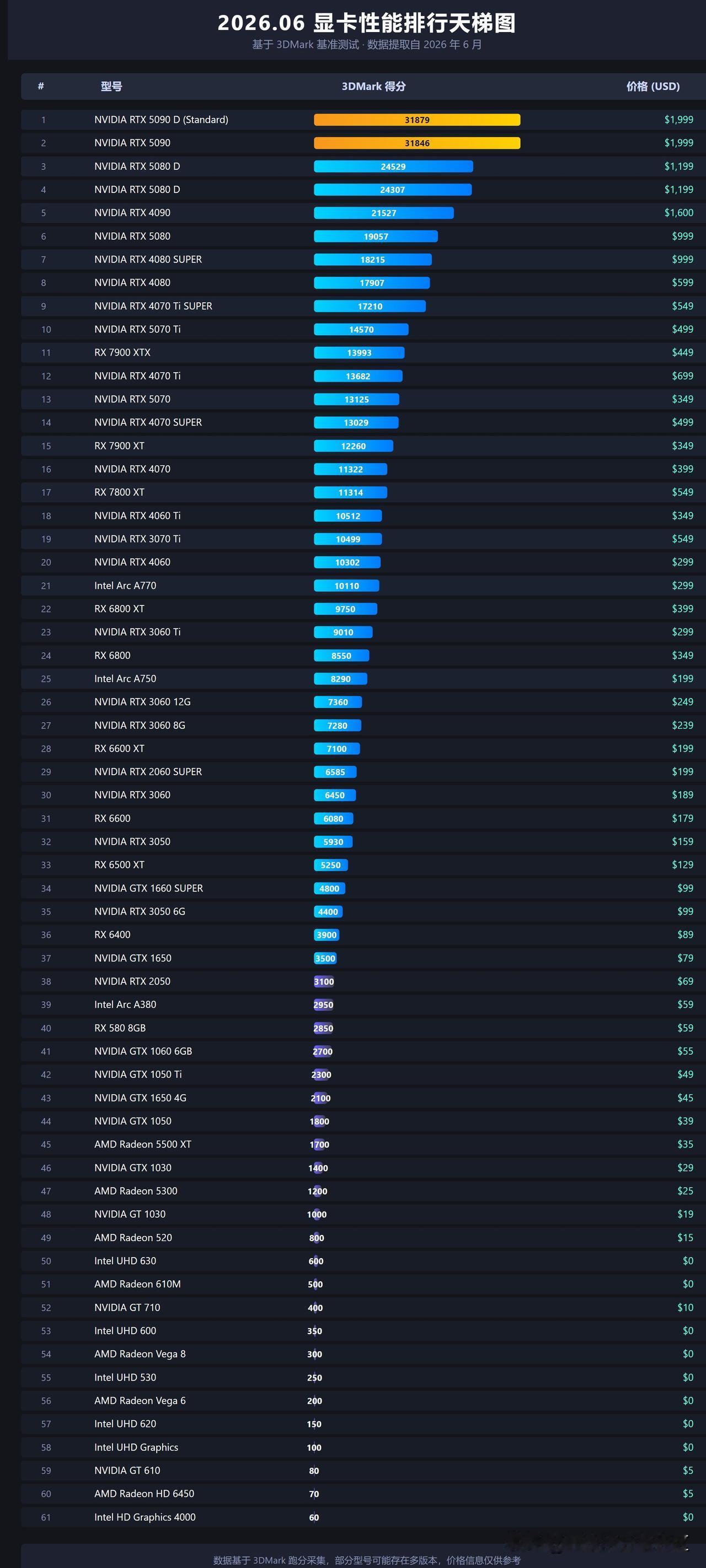
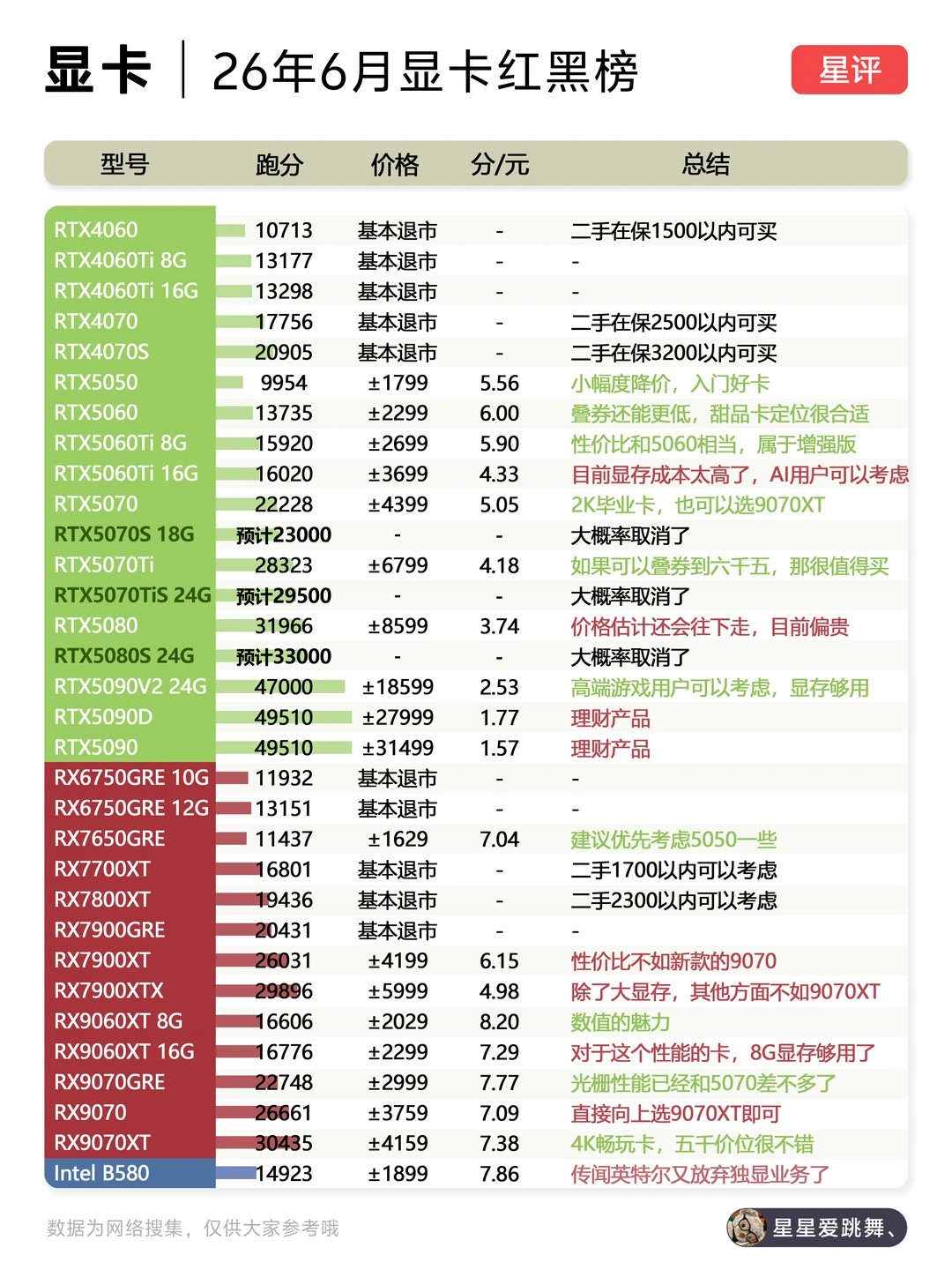
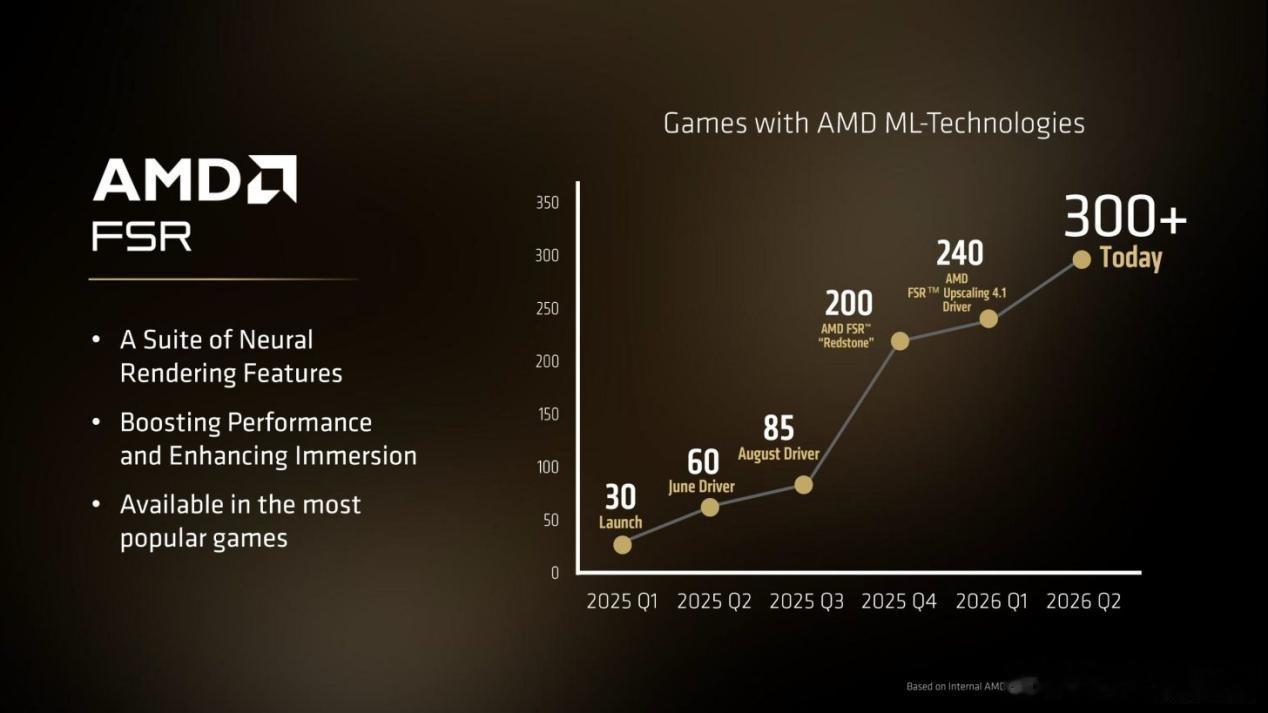
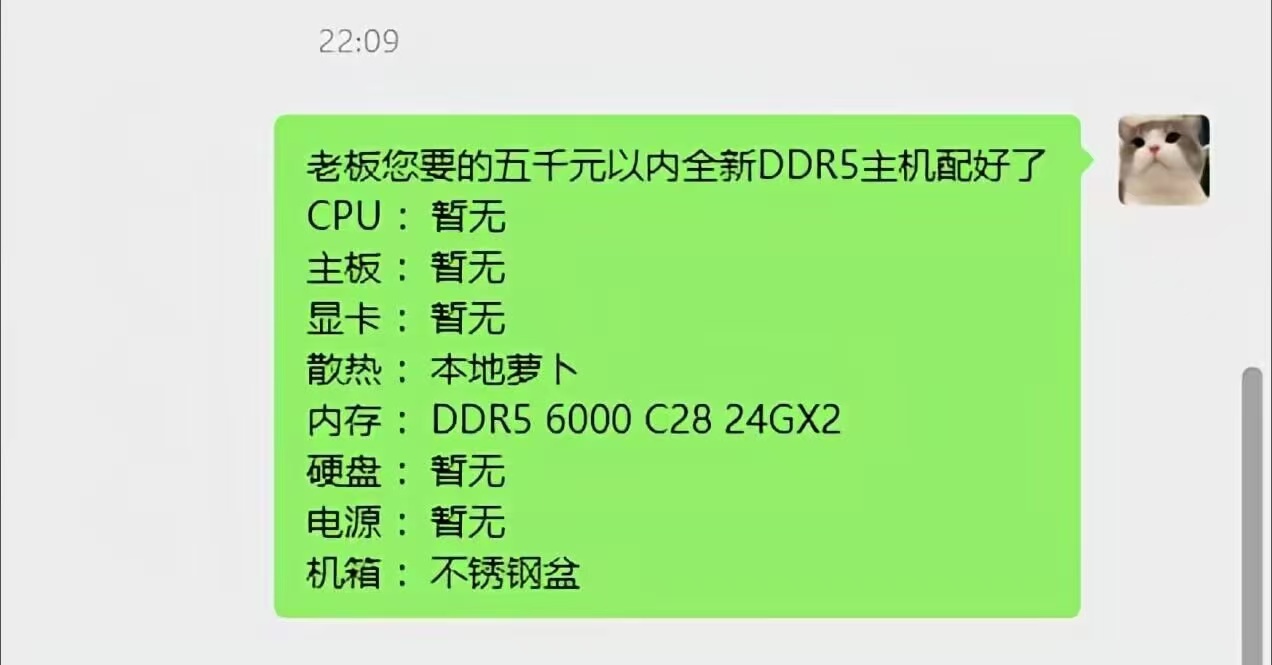
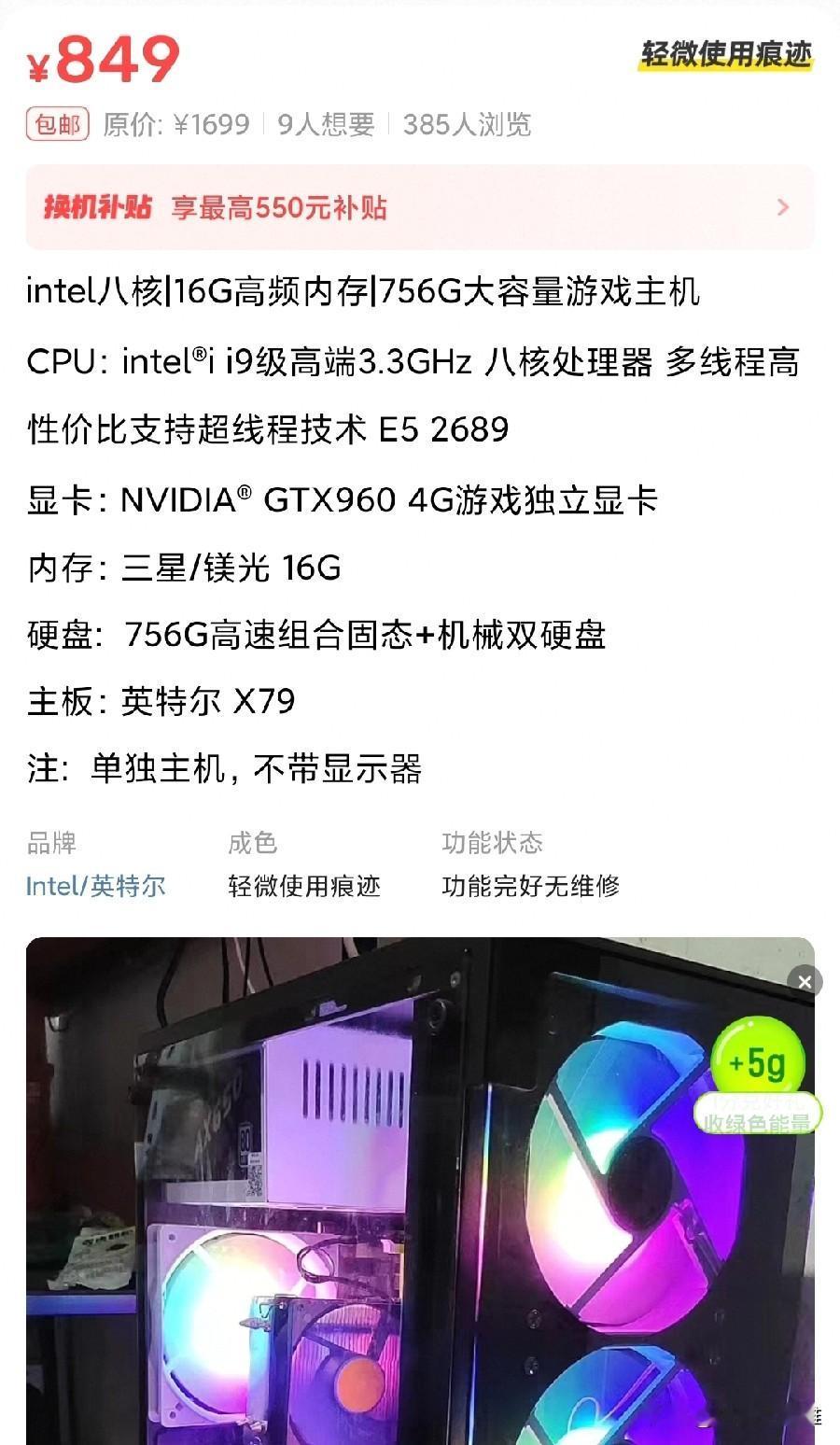
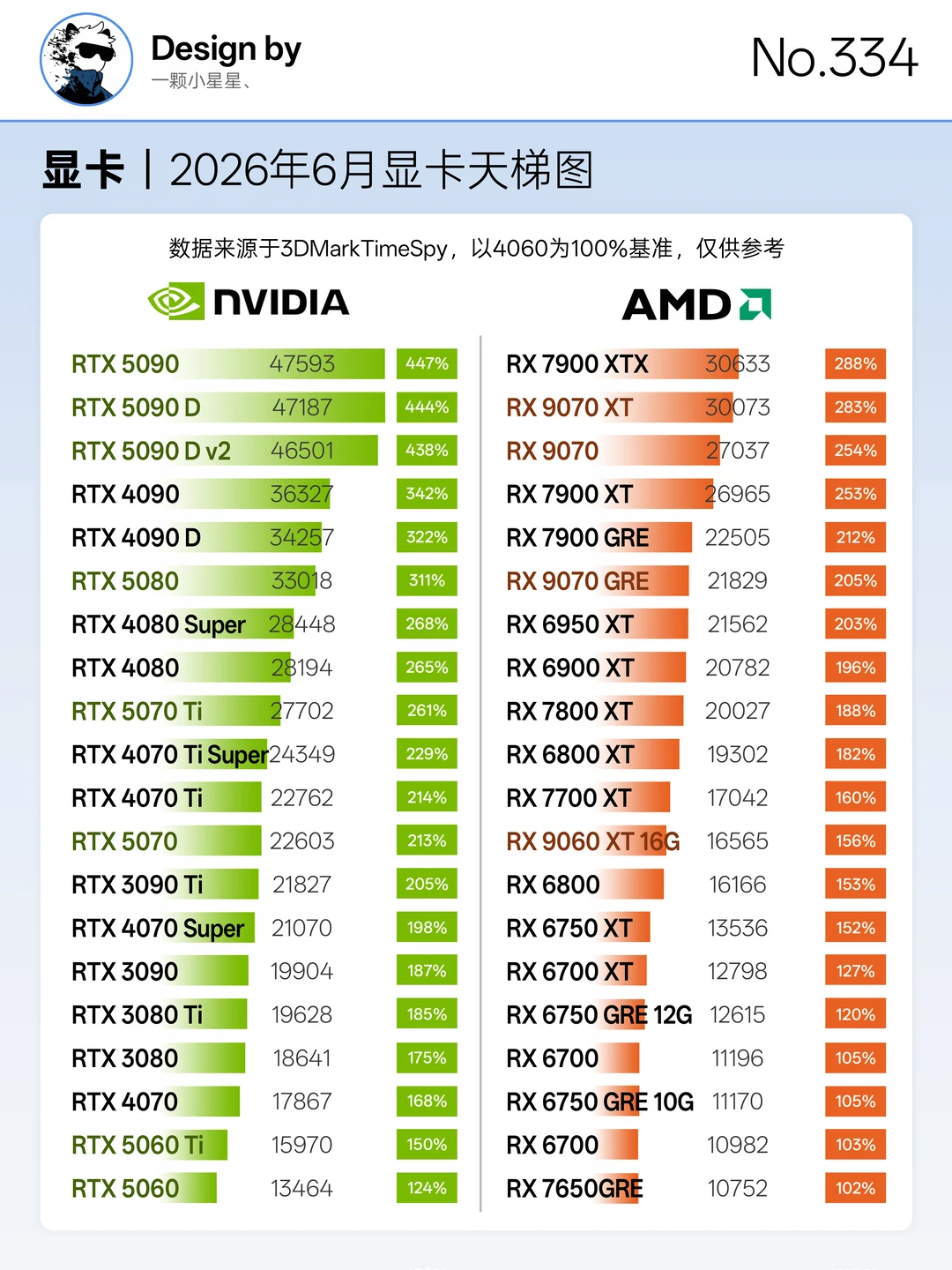
标签: 显卡














超时空抓捕
超时空抓捕












英雄联盟念念不忘前任🙂T1和华硕联名显卡宣传图:AD位置放了Gumayusi
英雄联盟念念不忘前任🙂T1和华硕联名显卡宣传图:AD位置放了Gumayusi今天T1官方发布了和华硕联名的显卡宣传图,但失误的是AD位置放上了Gumayusi的漫画小人物。将食指和拇指张开放在嘴边为gumayusi经常在赛后必出的动作,而Peyz则是手放在胸口。英雄联盟S162026MSILCK



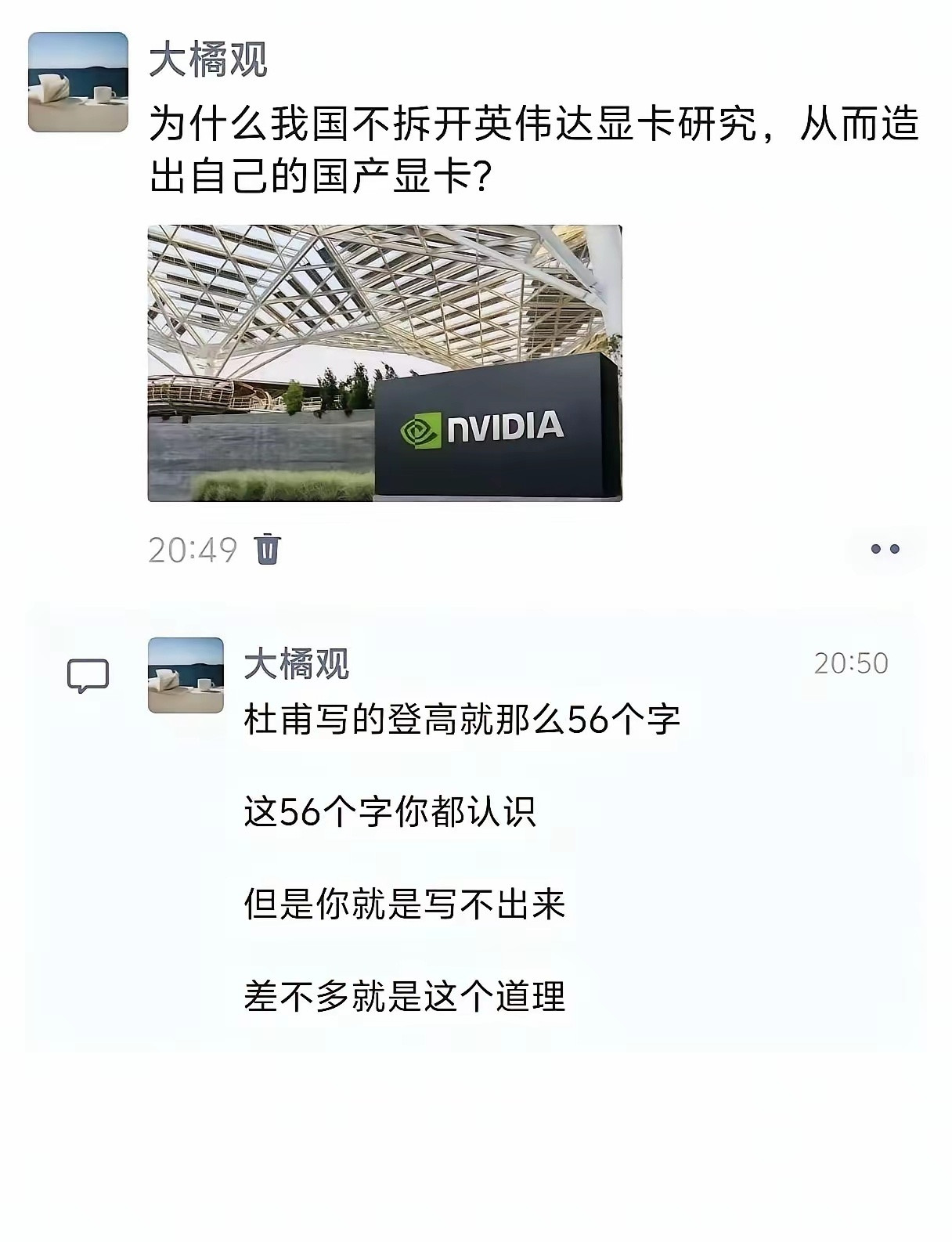
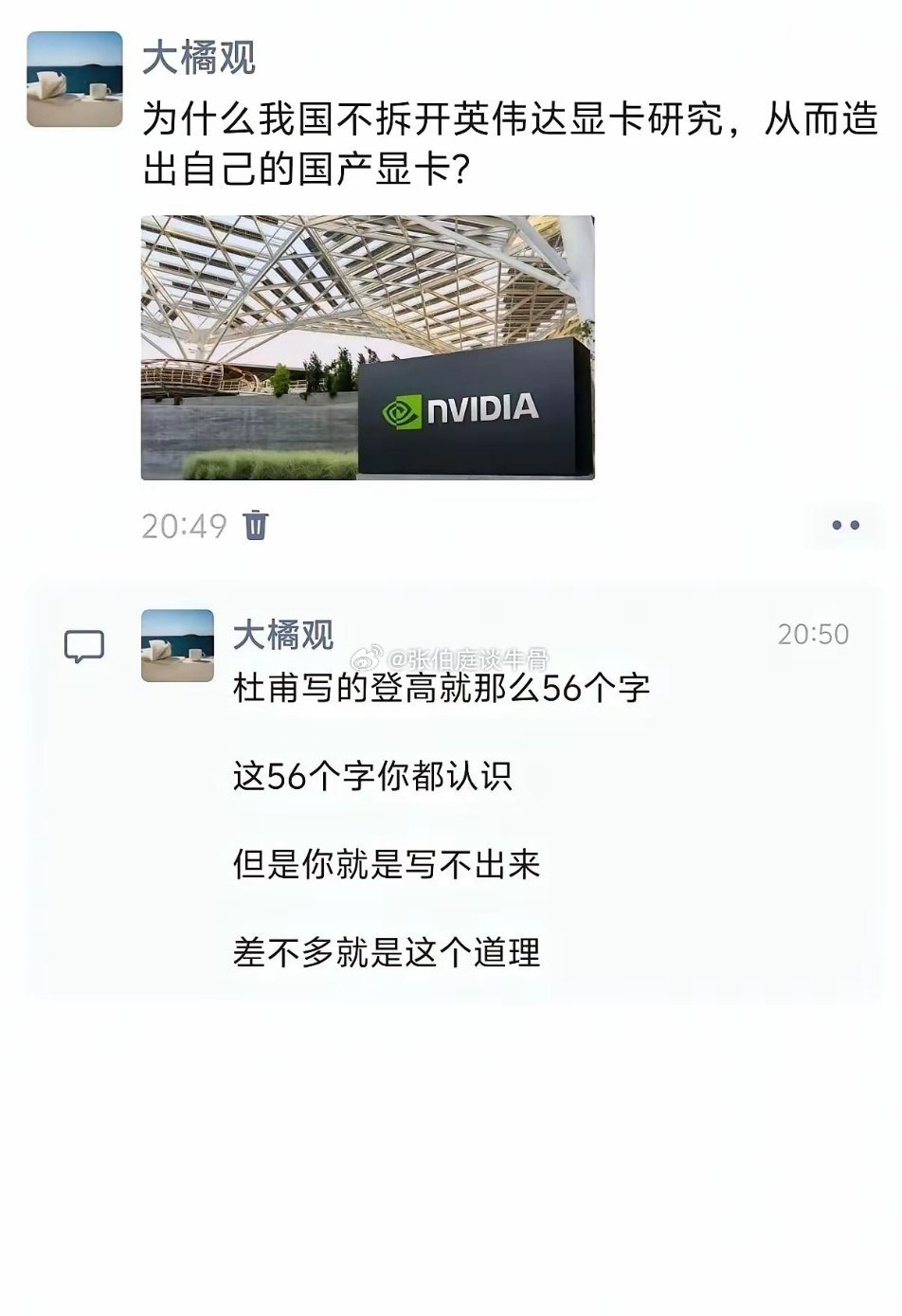
三次绝境翻盘,黄仁勋三十年创业路,藏着普通人可复用的底层启示很多人只看见如
三次绝境翻盘,黄仁勋三十年创业路,藏着普通人可复用的底层启示很多人只看见如今英伟达垄断全球AI算力的风光,却忽略黄仁勋的创业全程满是绝境、纠错与长线布局。从4万美元启动资金、首款芯片滞销濒临破产,到预判并行计算、搭建CUDA生态拿下AI时代话语权,他三十年经历三次生死危机,每一步选择都能给创业者、职场人带来不一样的现实启发。1993年,黄仁勋与两位工程师在平价餐厅创立英伟达,仅4万美元启动资金入局早已挤满35家玩家的图形芯片赛道。初代产品NV1追求多功能集成,技术路线与行业新标准相悖,上市彻底滞销,公司账上资金仅够发放30天工资,核心员工批量离职,走到关停边缘。生死关头他做出反常识选择:主动向合作方世嘉坦诚路线错误,放弃现成合约收益,裁员收缩全部非核心业务,把仅剩资源单点押注PC专用3D显卡,最终靠RIVA128实现盈利。第一重启示:敢于及时止损、直面错误,是创业活下去的底线。多数人会为沉没成本硬撑,而承认路线偏差、主动舍弃短期利益,才能避开全盘崩盘。度过破产危机后,行业对手扎堆争抢存量游戏显卡市场,价格战愈演愈烈。黄仁勋没有跟风内卷,而是确立“只做一件事,做到极致”的战略:放弃全品类芯片布局,深耕图形渲染赛道;同时提前布局长期投入,在现金流紧张时斥资购入仿真设备,大幅缩短芯片试错周期,产品迭代速度达到行业两倍。1999年行业首次提出GPU概念,重新定义品类,直接拉开与竞品差距。第二重启示:拒绝同质化内卷,找准差异化窄门深耕。与其在红海市场分蛋糕,不如聚焦单一优势做出新标准,用极致专业建立不可替代的壁垒。最具远见的一步,是2006年不计短期收益押注CUDA通用计算架构。彼时全球市场只看重游戏显卡营收,并行计算没有商业化案例,投入巨大却看不到即时回报。黄仁勋预判CPU性能增长会遇瓶颈,并行算力是未来刚需,持续免费开放CUDA适配全系显卡,搭建软硬件一体化生态。十几年后AI浪潮到来,这套底层平台成为全球科研、大模型企业的唯一主流选择,让英伟达跳出硬件厂商局限,掌控算力生态话语权。第三重启示:短期不赚钱的长期价值,才是真正的护城河。短期利润容易被复制,但提前布局、持续沉淀的完整生态,能形成难以追赶的长期优势。贯穿三十年的还有他常态化的危机意识,常年提醒团队“我们距离破产永远只有30天”。哪怕市值一路暴涨,也从未停下技术迭代与赛道拓展,从游戏显卡延伸数据中心、工业智能、机器人算力,持续开辟全新增量市场,而非固守原有业务躺平获利。第四重启示:顺境常怀危机感,永远主动开拓增量。市场没有永久红利,安于现有成绩,很容易被时代风口淘汰。不同于市面上单纯鼓吹“逆袭传奇”的浅层解读,黄仁勋的成功从不是运气加持,而是止损魄力、差异化战略、长线布局、危机思维四层逻辑叠加的结果。无论是自主创业还是职场发展,这套思路都具备现实参考价值。你认为普通人创业,最难做到的是及时止损,还是坚持长线布局?欢迎分享你的看法。