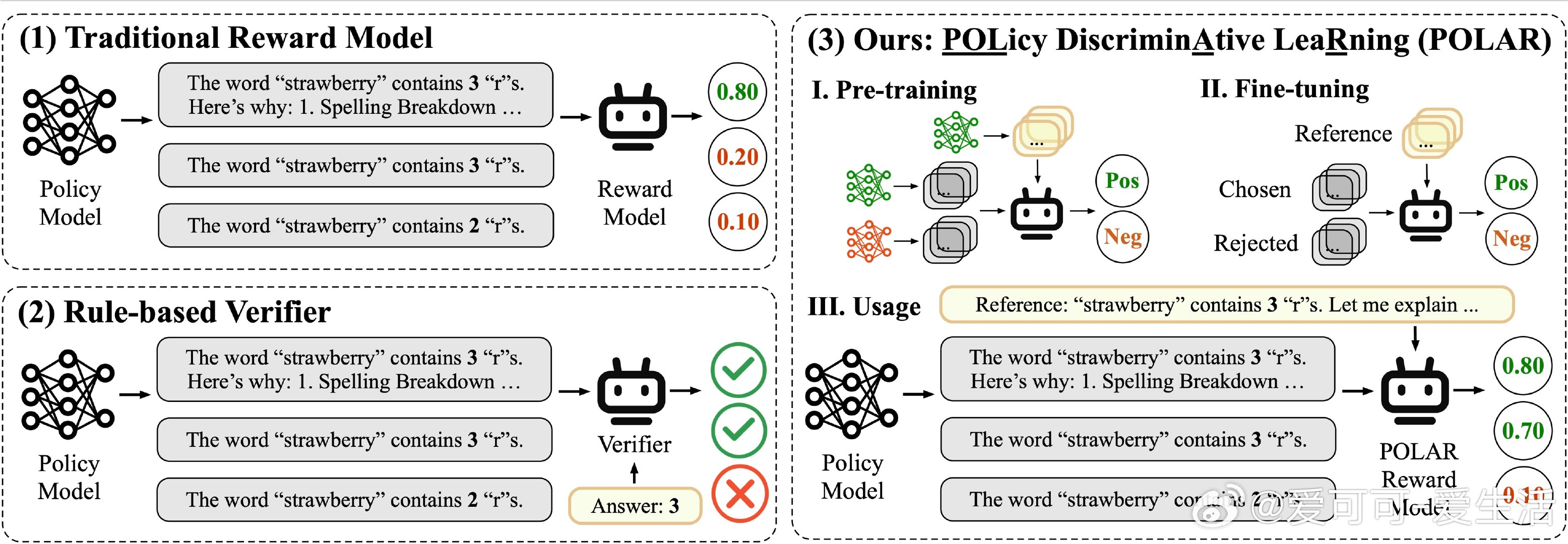
【[53星]POLAR:开创性的奖励模型,为强化学习任务提供精准奖励信号。亮点:1. 创新预训练范式,通过大规模合成语料高效区分策略;2. 提供1.8B和7B参数的预训练模型,灵活适配多种场景;3. 在下游强化学习任务中表现卓越,显著降低奖励劫持现象】
'POLAR: Pre-trained Policy Discriminators are General Reward Models'
GitHub: github.com/InternLM/POLAR
奖励模型 强化学习 AI预训练 人工智能 ai兴趣创作计划