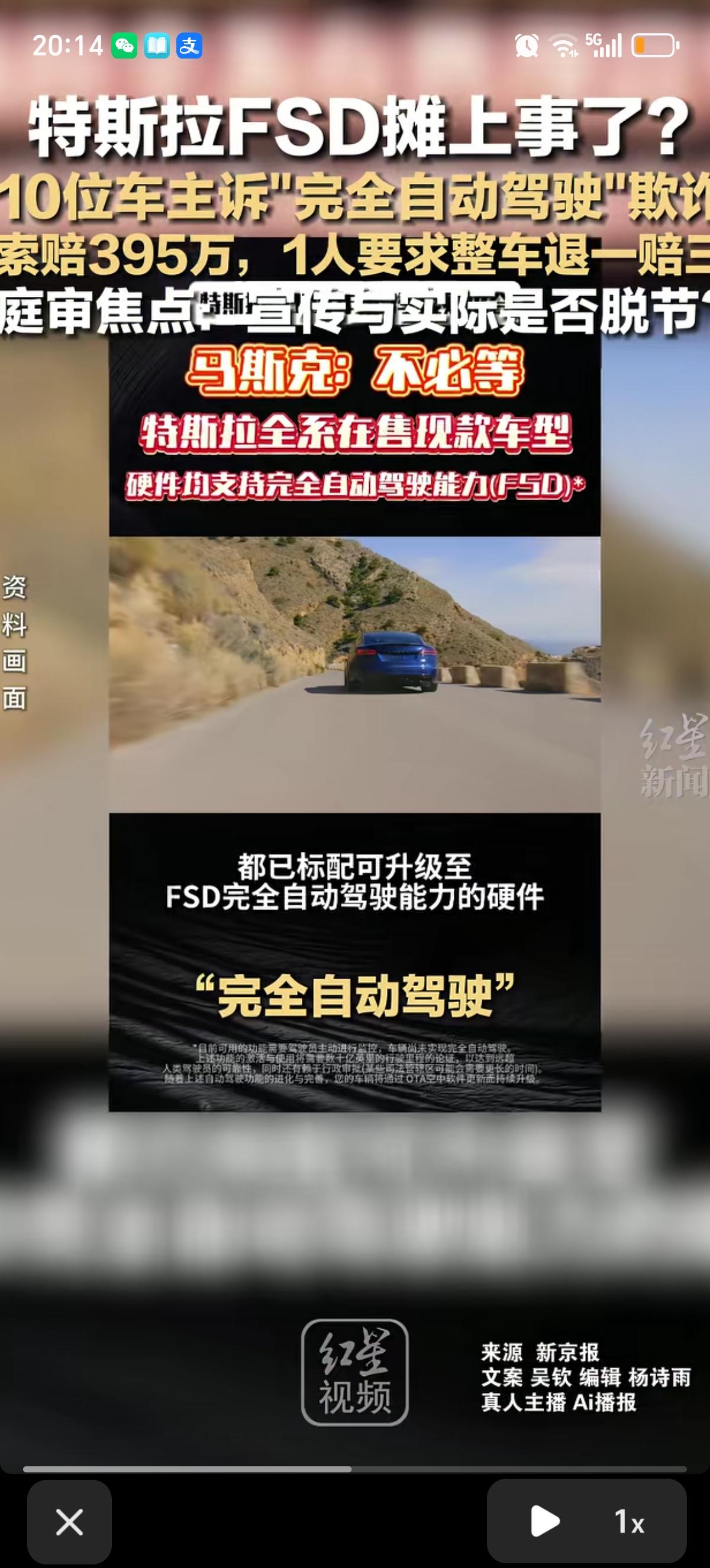
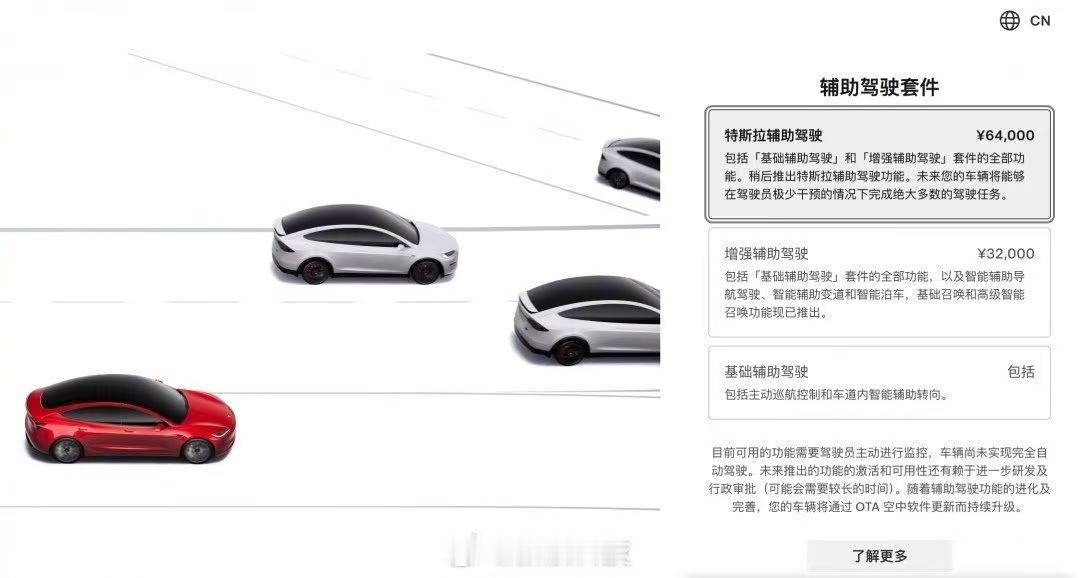
标签: 完全自动驾驶






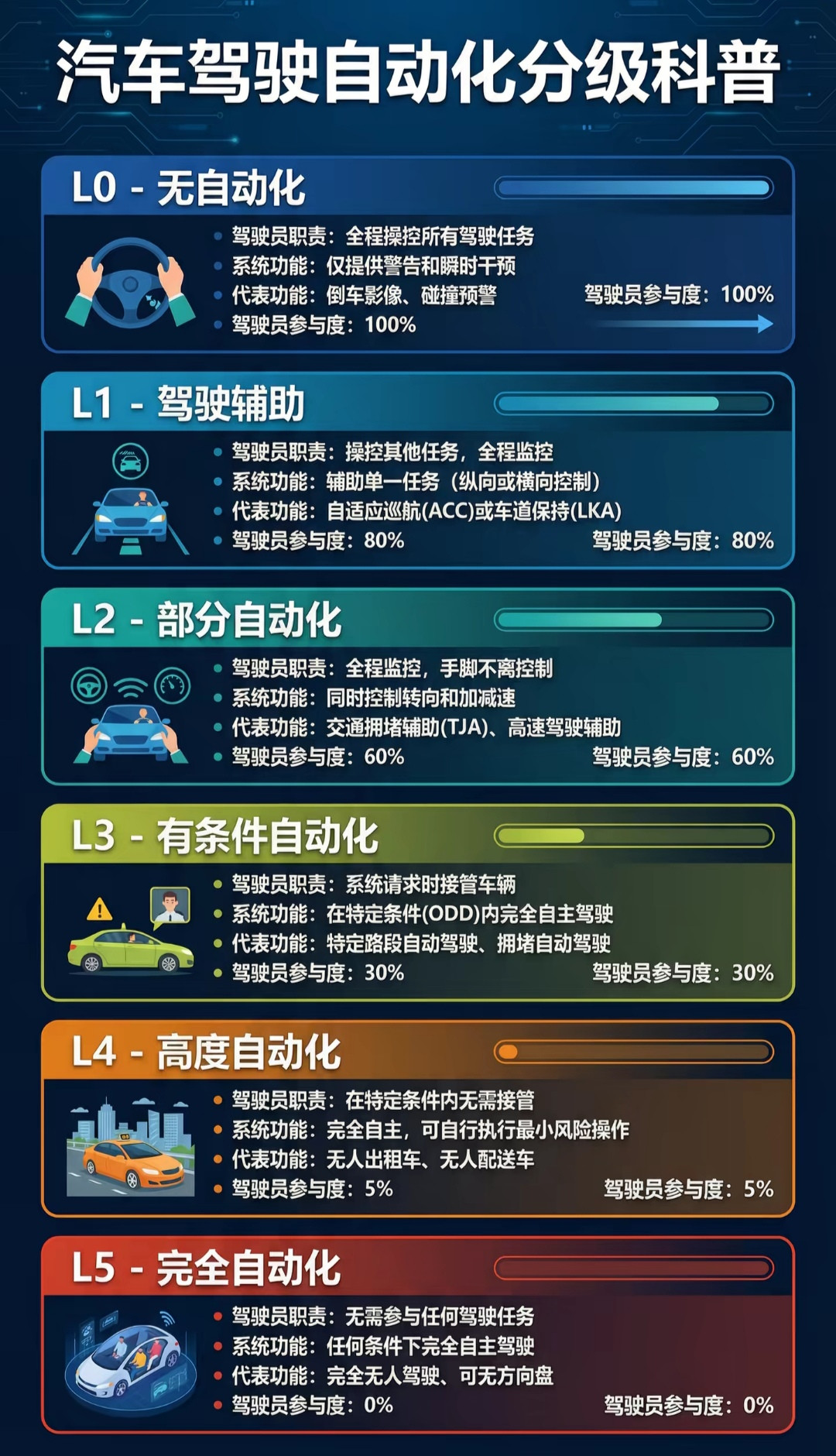
分不清辅助驾驶与自动驾驶很危险,不少车主因大意分心引发事故。多数车主都踩过这个
分不清辅助驾驶与自动驾驶很危险,不少车主因大意分心引发事故。多数车主都踩过这个误区,如今家用车搭载的智能系统统一是L2级辅助驾驶,法规要求司机全程专注。车辆可自动跟车、调速、避险,仅作减负工具,不能完全脱手。走神引发事故,驾驶员需要负主要责任。真正无随车司机的无人驾驶,不会一刀切全面铺开。往后3至5年(2028-2030年),高速干线货运无人重卡、限定城区Robotaxi会实现规模化商用。但全城市复杂路况、普通家用乘用车全场景L5完全自动驾驶,受法规、长尾路况约束,仅能小范围试点,很难全民普及。运力行业结构会明显调整,高速长途货运、固定线路无人出租会减少司机需求;但城市短途客运、装卸、复杂城区配送岗位很难被完全替代,不会出现全行业大规模淘汰人工司机的情况。自动驾驶普及会长期带动芯片需求,数据对比很直观:早年普通新能源车单车芯片搭载量约1500颗;如今搭载高阶智驾、多激光雷达的顶配测试车型,芯片总量最高可达4000-5000颗,智能化升级持续拉高芯片需求。中长期看,自动驾驶、人形机器人会带来海量新增芯片需求;短期全球芯片消耗主力依旧是数据中心算力设备,车载赛道属于持续高增长第二增长曲线。等到车上彻底没有随车驾驶员,事故责任划分是绕不开的难题。按国标划分,市面上家用车全是L2辅助驾驶,驾驶员全程担责;仅试点城市封闭区域的L4无人车(无随车司机),由车企、运营平台承担主要赔付责任,后台远程监控仅作应急兜底,不能覆盖全部事故责任。除无人驾驶需要完善交通权责法规外,通用AI大模型还单独面临数据合规、算力资源管控等互联网层面监管难题。无论是车载智能还是通用AI,技术发展都需要配套的伦理、安全监管规则同步落地。拥抱科技红利的同时,监管规范必须跟上技术脚步。客观提醒:全自动无人驾驶长期空间确定,但短期存在多重约束:复杂路口、雨雪恶劣天气、行人非机动车等长尾场景算法仍有短板;各地落地法规进度不一,芯片、激光雷达等硬件成本偏高,商业化落地节奏会分场景逐步推进,不宜短期过度乐观。参考资料:光明网:《智能辅助驾驶≠自动驾驶!L3级自动驾驶试点运营有何“升级”?》中国交通新闻网:《自动驾驶卡车竞逐干线物流》EEWorld电子工程世界:《智驾域控SoC安装量近800万,本土芯片市占升至20.7%|2025年1-11月市场分析》







中国自动驾驶技术正迎头赶上美国,就像10年前的电池!美国“汽车城”底特律的媒
中国自动驾驶技术正迎头赶上美国,就像10年前的电池!美国“汽车城”底特律的媒体《底特律新闻》6月2日刊登了一篇文章,说美国在自动驾驶技术的竞赛中,正面临被中国超越的风险。专家认为,这背后是中国独特的市场环境、监管政策变化,以及本土品牌令人惊讶的研发速度。就像十年前中国的电池技术从落后追到世界领先一样,现在自动驾驶也正在走同样的路。过去大家不太直接比较中美自动驾驶水平,因为中国车没怎么进美国市场,加上数据共享限制。但现在情况变了。特斯拉拖了好几年,最近宣布它的完全自动驾驶系统将通过软件更新登陆中国市场。与此同时,谷歌旗下的Waymo也准备在英国和中国企业正面竞争。越来越多的中国汽车品牌正在走向全球,北美也在计划之中。Omdia公司的电动汽车分析师刘运程说得很直白:中国正以前所未有的速度迎头赶上,这就像十年前。当时中国在电池技术上还比较弱,后来大量投入研发并实现规模化应用。现在同样的追赶势头出现在自动驾驶领域。专家普遍认为,特斯拉的FSD系统目前仍然是全球领先者之一。但尽管之前中国市场已经有简化版FSD,中国本土的小鹏汽车、小米汽车却率先推出了更先进的半自动驾驶功能。上个月马斯克随特朗普访华后宣布FSD正式获准进入中国,但大规模推广的最终审批还没下来。对于特斯拉来说,进入中国市场有助于巩固地位,而中国车企越来越依赖智能驾驶来打造差异化。刘运程还提到,中国从疯狂打价格战转向了更关注智能化和高级辅助驾驶系统,这些技术已经出现在很多主流价位的车上,普通消费者也能用得起。当然,中国对自动驾驶安全把控很严。去年年底出台规定,如果检测到驾驶员双手离开方向盘超过一分钟,系统必须警告、减速并靠边停车。相比之下,特斯拉FSD、通用SuperCruise和福特BlueCruise在美国仍允许使用。标普全球的专家评论说,中国有自己的节奏和要求。再看市场数据。预计到2025年底,中国L2级智能辅助驾驶渗透率将超过一半,2026年高速L3级自动驾驶将大规模商用。2025年1到7月,具备组合驾驶辅助功能的新车卖了776万辆,渗透率达到62.6%。每卖出10辆新车就有超过6辆带着智能驾驶功能,这个速度非常快。放眼海外,2026年被看作自动驾驶爆发的元年。美国的Waymo计划在全球20多个城市运营无人驾驶出租车,而中国的百度萝卜快跑在迪拜、英国、瑞士加速落地。小马智行今年要投放超过3000辆无人驾驶出租车,海外占比达20%到30%。伦敦正成为中美无人驾驶出租车正面较量的关键舞台。百度萝卜快跑与Uber合作准备在伦敦推出第六代无人车,谷歌Waymo也已经在伦敦启动路测。伦敦可能成为第一个同时运营中美无人驾驶出租车的城市。有英国投资人承认,中国在这个领域已经遥遥领先。中国企业出海第一站大多选在中东,因为当地政策宽松、客单价高,而且出租车司机多为外籍劳工,推广无人驾驶对本地就业冲击小。文远知行已经在阿布扎比与Uber合作启动了真正的无人驾驶出租车商业服务。底特律媒体的这篇报道其实是在提醒美国人:别光盯着特斯拉,看看对面那些中国车企吧。它们的速度和规模,也许会让整个行业重新洗牌。