之前分享了零刻GTi15 Ultra 拆解和性能测试,这篇主要探讨的零刻GTi15 Ultra 在 AI 以及搭建本地大模型的性能表现。

要说零刻 GTi15 Ultra 最大的升级,无疑是搭载的这颗英特尔酷睿 Ultra 9 285H 处理器。
相比上代,Ultra 9 285H 处理器不仅有性能提升,更重要的是,该处理器整合了 三 种计算单元,提供了高达99 TOPs的总算力,具体分配如下:
GPU:77 TOPs (主要图形和 AI 负载)
NPU:13 TOPs (持续性低功耗 AI 任务)
CPU:9 TOPs (轻量级和即时 AI 响应)

参数方面,酷睿 Ultra 9 285H采用台积电 N3B 工艺,从根本上优化了能效比。拥有16 核 16 线程的强大规格,具体包括6 颗性能核(最大睿频 5.4GHz) + 8 颗能效核(最大睿频4.5GHz) + 2 颗低功耗能效核(最大睿频 2.5GHz),L2 缓存 8MB、L3 缓存 24MB,集成基于全新 Xe-LPG 架构的锐炫 140T 显卡,TDP 45W,最大功耗为 115W

▼首先利用UL Procyon 量化基准测试数据 ,这是 ULSolutions(3DMARK 母公司)出品的、面向专业人士的测试软件,包括 MicrosoftOffice 生产力性能测试、PS / LR 性能测试、以及基于 Stable Diffusion模型,专门用于测量高端硬件 AI 性能基准工具。

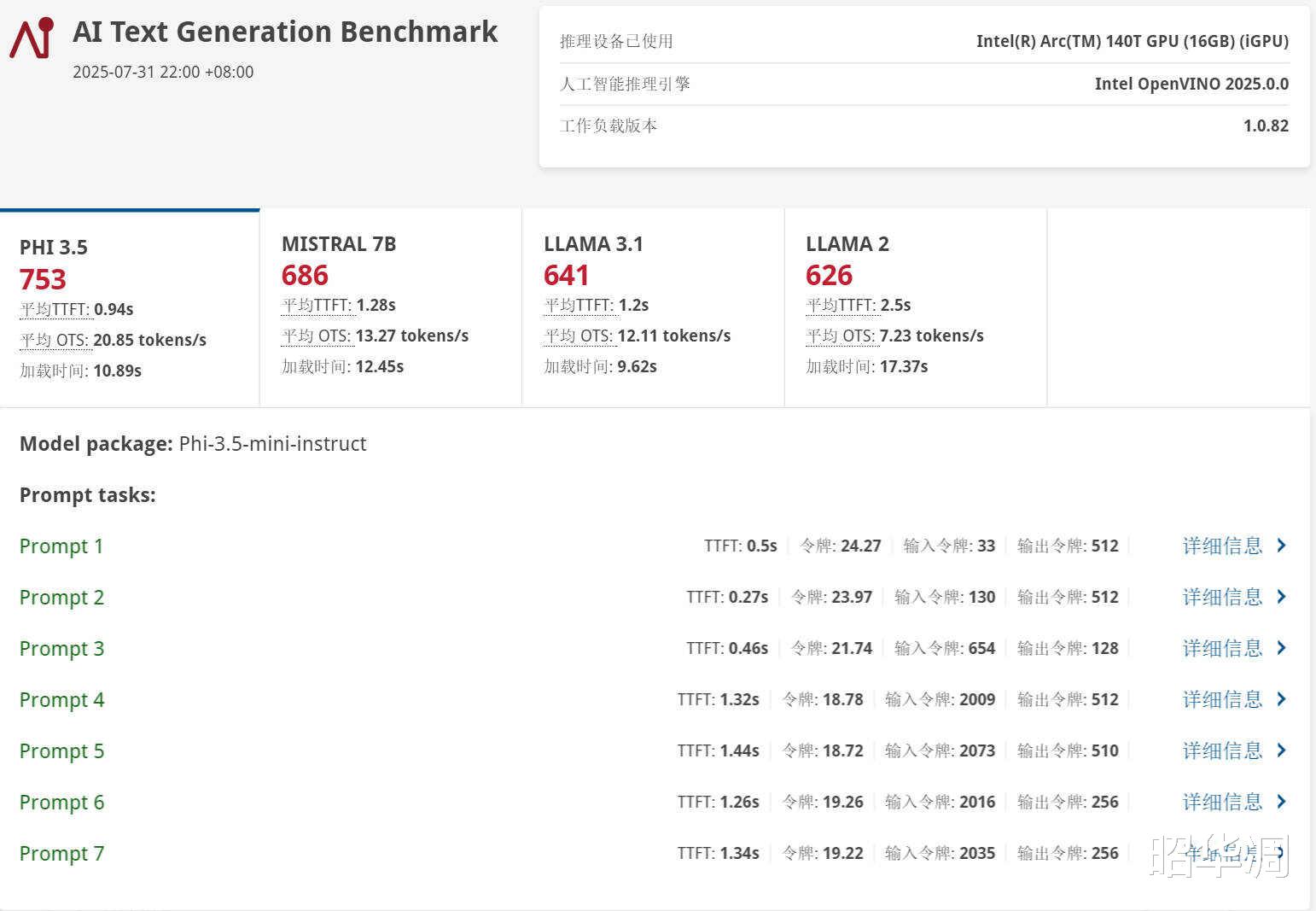
▼UL Procyon AI 文本生成基准测试:此项测试专注于本地大型语言模型(LLM)的推理能力,模拟设备端 AI 助手应用。零刻GTi15 Ultra在各项模型测试中的得分如下:PHI 3.5:753 分 、 平均 TTFT 0.94s 、 平均 OTS 20.85 tokens/s 、 加载时间 10.89s
MISTRAL 7B:686 分、平均 TTFT 1.28s、平均 OTS 13.27 tokens/s 、 加载时间 12.45s
LLAMA 3.1:641 分、平均 TTFT 1.2s 、 平均 OTS 12.11tokens/s 、 加载时间 9.26s
LLAMA 2:626 分 、平均 TTFT 2.5s、 平均 OTS 7.23 tokens/s 、 加载时间 17.37s
▼AI Image Generation Benchmark(文生图),这个测试通过创建 8 幅分辨率为512 X 512的图像,汇总效率并打分。零刻GTi15 Ultra 在本次测试得到了 1665分,总体消耗时间150074s,图像生成速度为18.579s/image,平均 UNET 速度 2.692it/s,。

本地部署 Ollama 英特尔优化版
本地搭建 AI 大模型是比较流行的玩法,相较于使用在线 AI 平台,不仅拥有敏感数据保护、规避云端波动风险,离线运行保障等优点,高频使用也更经济。当然缺点也有,那就是硬件要求较高,其次部署需掌握环境配置、模型优化等技能,长期使用还需要定期更新模型版本并监控硬件状态。
▼之前笔者分享过利用Ollama 进行本地部署的例子,但可能很多朋友不知道,Intel 也针对 Ollama 推出了款定制优化版,能够更好的调用285H 强悍的 GPU 性能,相关软件和教程已在ModelScope 魔搭社区正式上线,感兴趣的朋友可以自行下载。
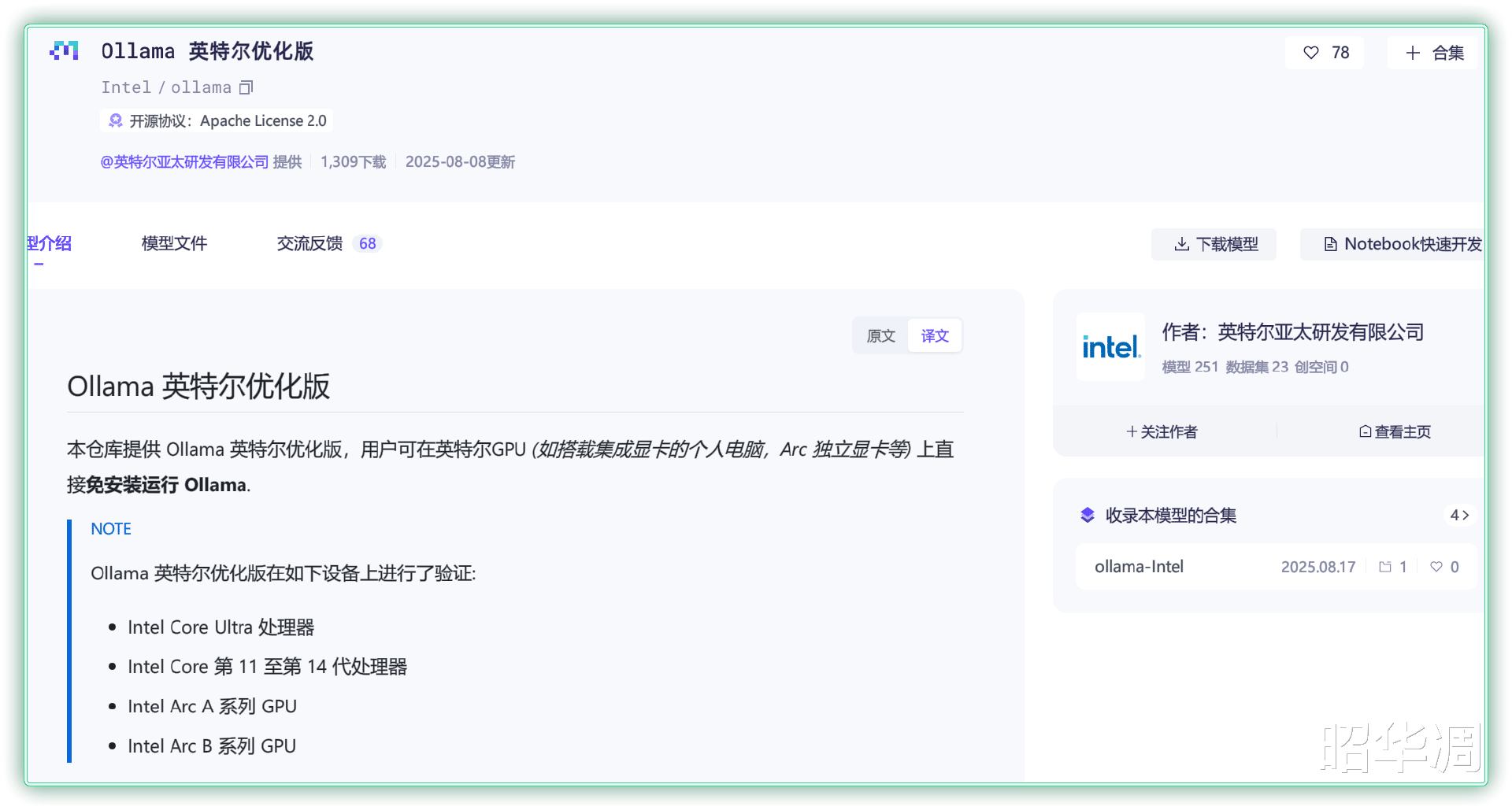
▼先从连接进行下载解压,双击 start-ollama.bat 文件,然后右键复制解压文件夹地址。
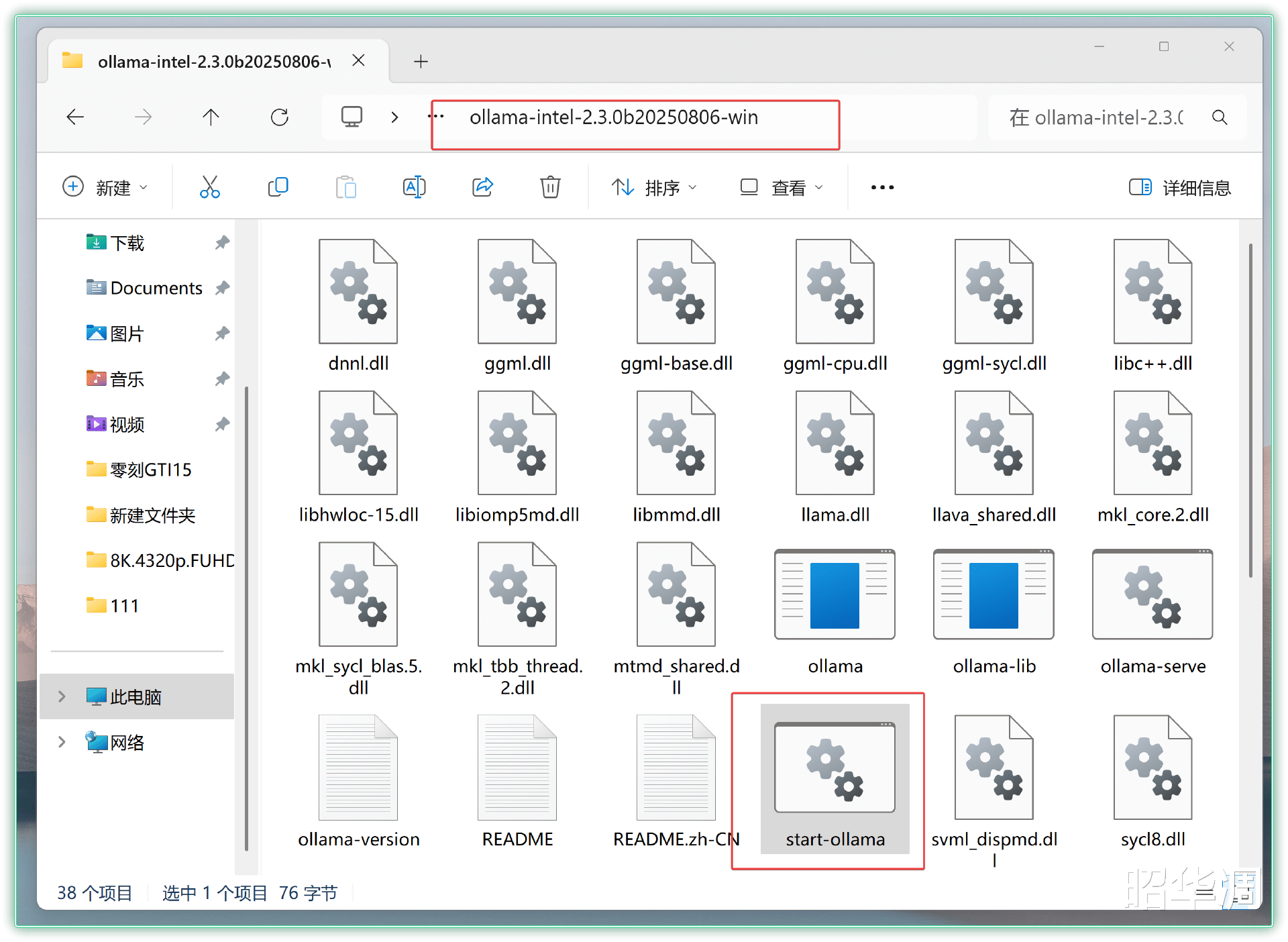
▼接下来 CMD 打开命令提示符,输入 CD:文件夹地址进入解压缩后的文件夹
▼再次输入以下命令进行模型拉取,这里选择的 7B 模型,毕竟285H 的核显能够将部分内存划分为显存使用,显存基本不会成为瓶颈。
ollama run deepseek-r1:7b
▼拉取完成后,新建 CMD 窗口,并输入下面的命令和模型进行问答,后面添加的verbose 后缀能显示当前问答的耗时、速率等相关参数,方便进行性能对比。
ollama run deepseek-r1:7b --verbose
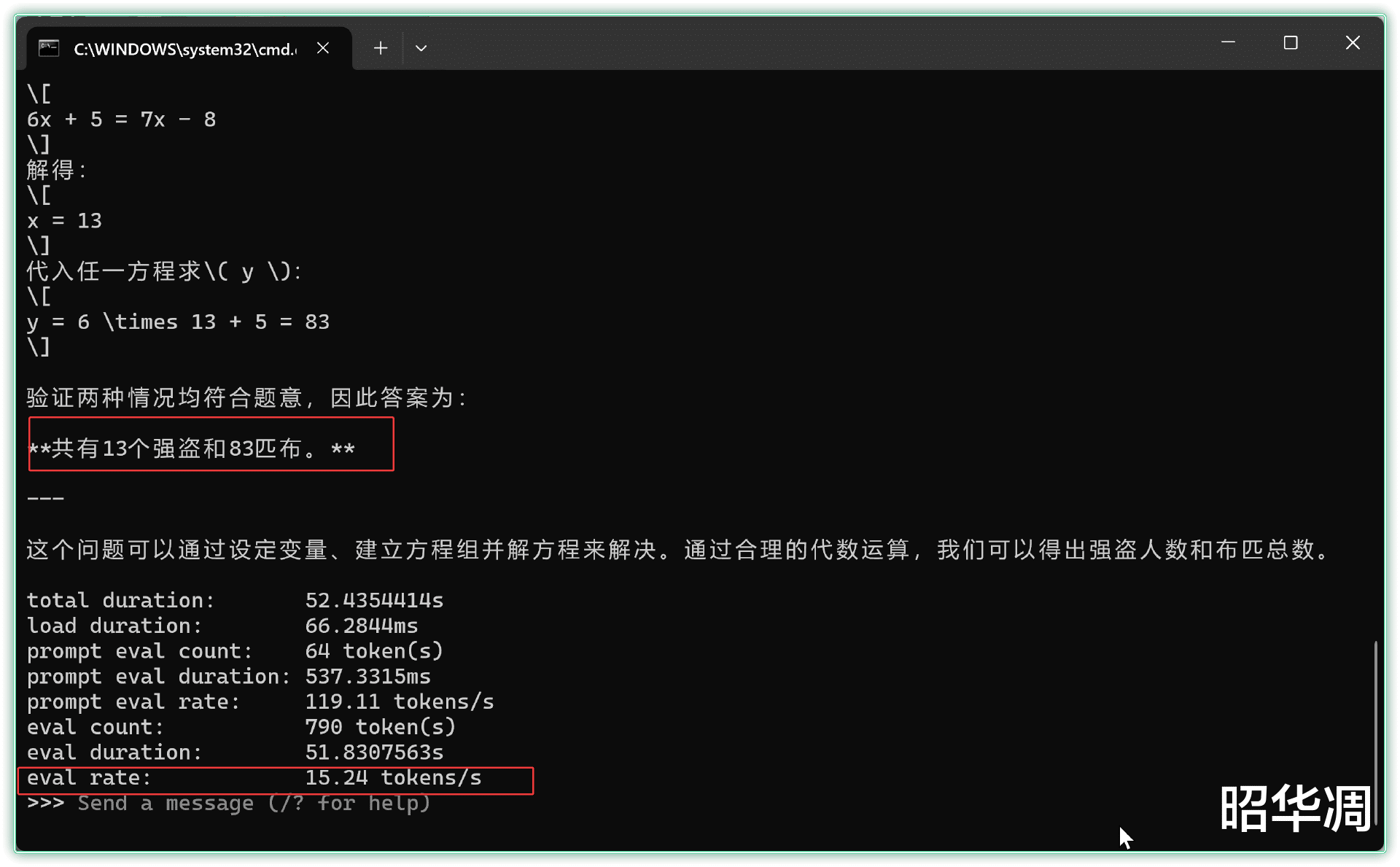
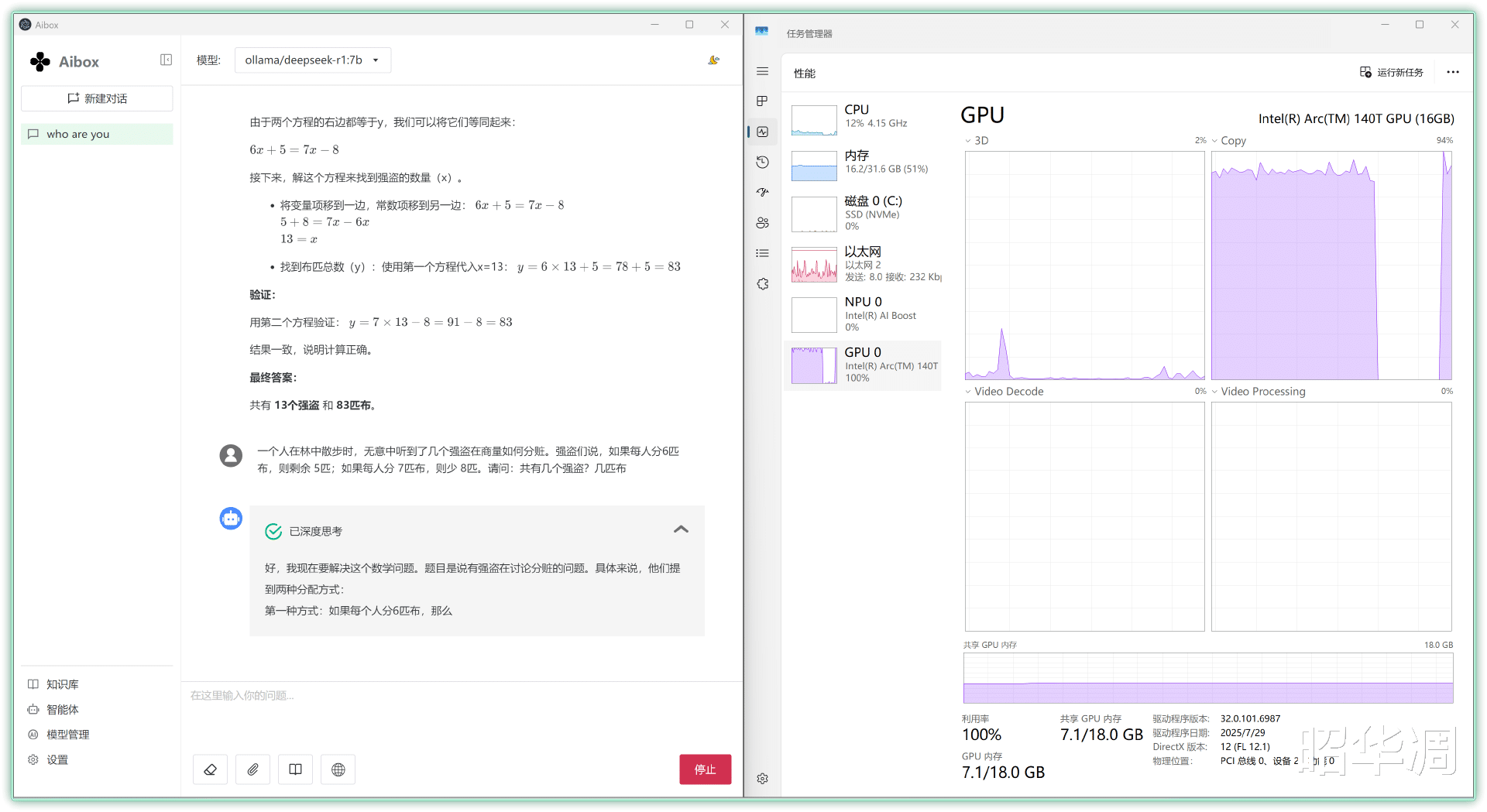
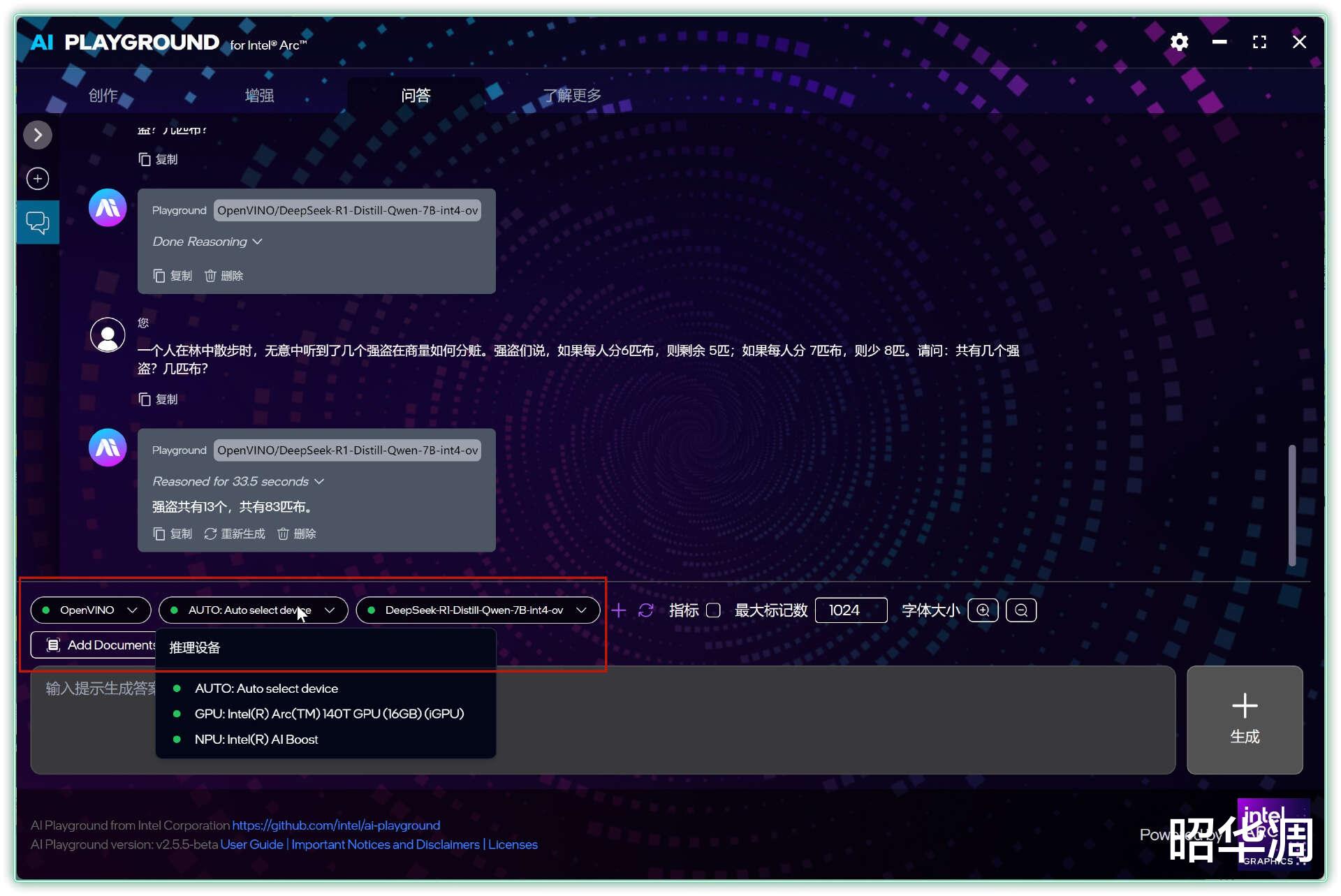
▼比如用强盗分赃这个经典推理题为例,下方显示的速率达到了15.24 token/s,
一个人在林中散步时,无意中听到了几个强盗在商量如何分赃。强盗们说,如果每人分6匹布,则剩余 5匹;如果每人分 7匹布,则少 8匹。请问:共有几个强盗?几匹布?
答案是,共有 13个强盗, 83匹布。
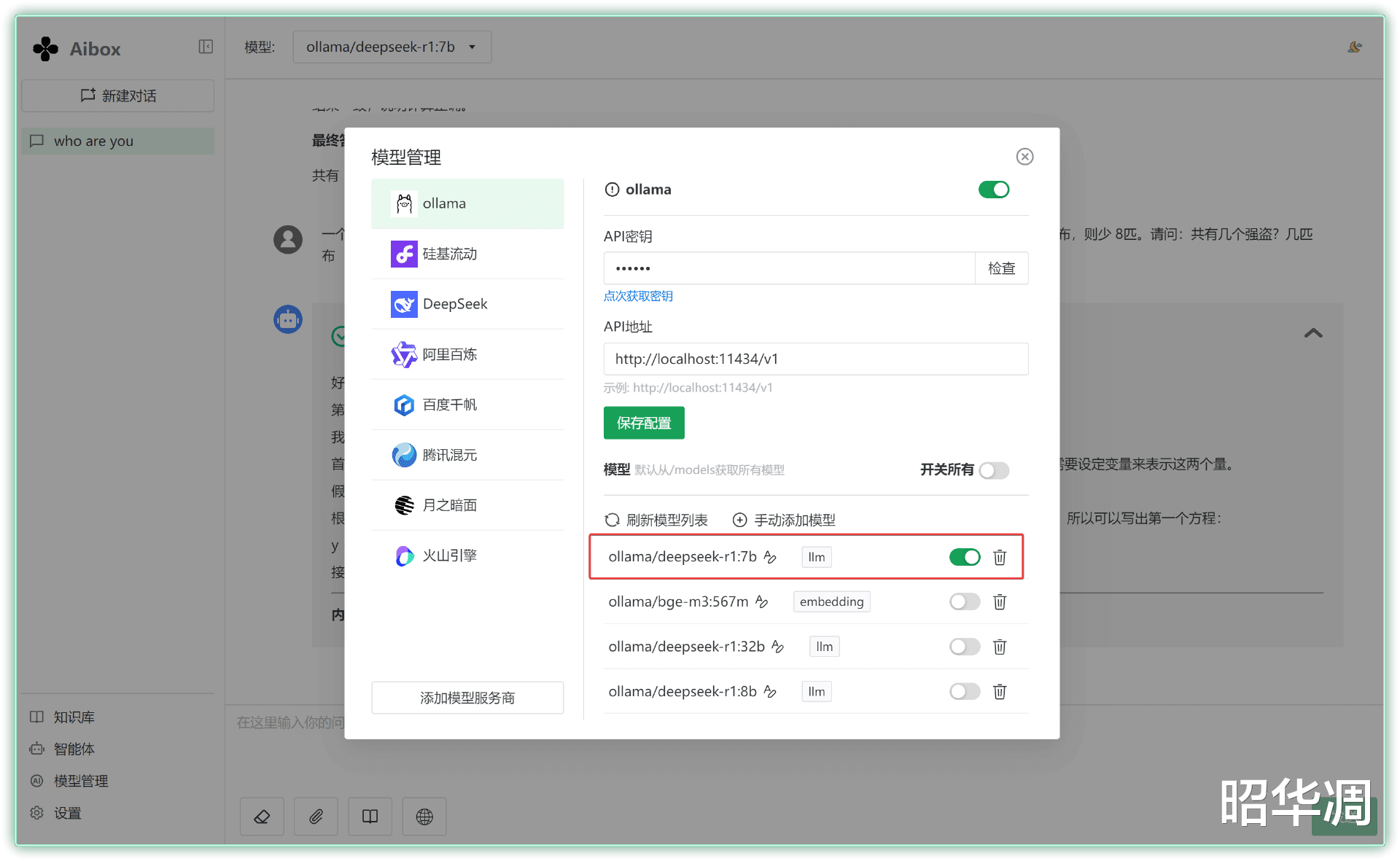
▼如果嫌命令行窗口太简陋,也能利用现成的壳来直接调用,比如零刻预装的 AI BOX,它不仅能使用在线 API ,也可以借助本地模型运行
配置的时候选择本地模型,另外记得ollama 文件夹中start-ollama.bat 保持后台运行状态。
▼现在的对话窗口就美观多了,推理时GPU 也是处于满载状态。
英特尔 AI Playground
英特尔针对自家硬件也推出了不少 AI 工具,比如大家最熟悉的openvino 套件,以及下面提到的AI Playground。
▼AI Playground 是由英特尔推出的开源生成式 AI 应用平台,专为搭载英特尔硬件(如锐炫显卡或 Core Ultra 处理器)的设备优化,旨在降低 AI 开发与创作门槛,支持本地 AIGC 图像生成、文本对话、图像编辑等多模态任务。这个软件最大的优势就是免费且简单易用,支持的框架也比较全,可以理解为 Intel 专属的 AI 应用

▼当前最新的版本是 2.5.5
▼相较绘世这种主流的文生图软件,AI Playground 无需部署,下载后直接就能使用。
而且,绘世等 AI 软件很容易识别不到 Intel 显卡,在这个软件就不存在这些问题。
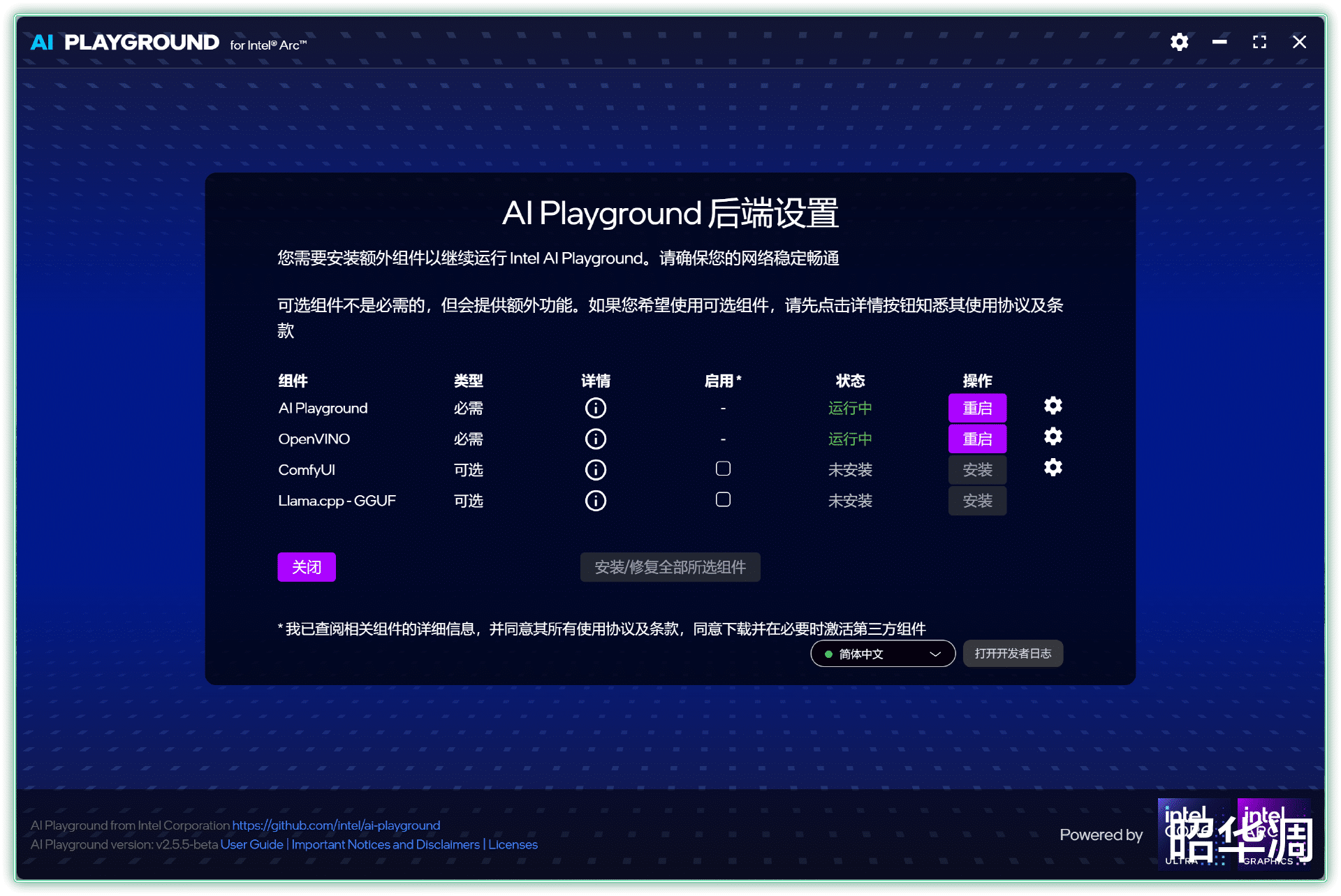
安装时先下载核心组件,右下角可以切换中文
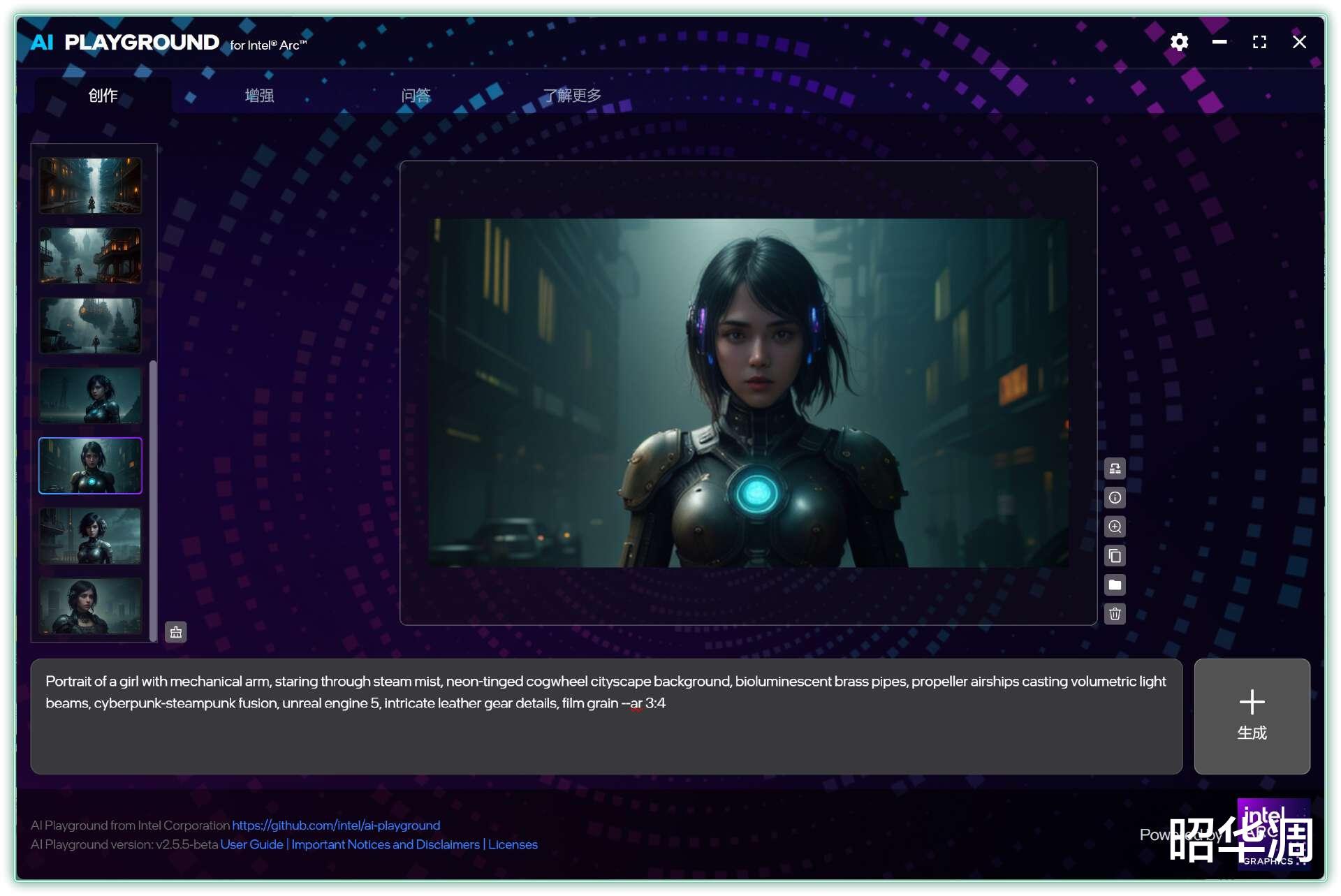
▼软件界面很容易上手,创作、增强、问答大致对应文生图、图形编辑和 AI 对话
输入提示词就能快速生成图片,像这套四张的蒸汽女孩在急速模式下,仅需 16s 即可完成,Ultra 9 285H 的核显的确挺强的。
▼也可以手动调节分辨率、步数参数以及模型等等
▼选择不同的渲染模式,软件会自动下载相关模型,相当省心。
▼增强模式可以对图片进行重绘,放大以及扩图等操作,这些功能放在第三方软件或者网站都是妥妥的收费项目,用AI Playground 就很划算了,而且速度也很不错。
▼问答模块可以选择不同模型以及推理设备。
零刻 & 豆包 AI 语音交互
除了处理器赋予的高算力,零刻 GTi15 Ultra 还针对豆包等 AI 工具做了深度适配,它通过 一 个由 4 个麦克风组成的阵列来全方位拾取声音,然后交由一颗强大的 B1降噪芯片 进行智能处理。
简单形容的话,这个过程就像给电脑装上了一双“聪明的耳朵”:
它能分辨出哪些是您说话的声音。
同时,它会“监听”设备自身喇叭播放的声音和周围的环境噪音(如风扇声、键盘敲击声)。
最后,B1 芯片内置的智能算法会像“过滤器”一样,精准地消除喇叭回声和环境杂音,只留下您纯净、清晰的人声。

▼这颗智能拾音降噪 AI 芯片也是相当强悍,它搭载波洛斯麦克风阵列技术,配合 DNN 神经网络降噪算法、深度神经网络回声消除算法、AGC 自动增益调节算法、啸叫抑制、混响消除等多重技术,来实现纯净、干净清晰的人声体验
▼我试了一下,把主机放一边,旁边音箱开着电影,我离着一米远跟它说话,它居然都能准确识别,降噪效果真的不错。

这个功能最爽的地方有两个:
▼一 是和现在很火的 AI 聊天,比如“豆包”,直接用嘴说就行,查资料、定计划都特别方便,有种钢铁侠的感觉。
话说,这种对话式查询真的很棒,而且支持对话式交流,如果主机能带块小屏幕就好了,直接就能放在客厅充当智能音箱的角色。
▼二 是游戏神器!我天天都打几局 LOL 或 COD,有时候玩的时间不长,真的懒得去翻耳机、插线。现在直接用主机自带的麦克风就能和队友交流,声音清楚不耽误事,方便太多了!
总结
根据评测与本地部署测试来看,零刻 GTi15 Ultra 所搭载的 285H 处理器展现了强大的 AI 算力,为本地 AI 应用的开发与运行提供了坚实的硬件基础。更值得一提的是,该主机通过 PCIe 插槽支持外接显卡坞,且性能传输近乎无损,能够充分满足 AI 开发者及爱好者对高性能本地环境的严苛需求。