先来点俗的。 在这个大模型还在按 Token 算计成本的年代,小米直接把桌子掀了。
看这张价格表:
输入: $0.1 / M Tokens
输出: $0.3 / M Tokens
不仅如此,这就还“限时免费”。
这是什么概念?哪怕对比以性价比著称的 DeepSeek-V3.2,MiMo 的性价比坐标也是直接飞到了图表的右上角——“Best Efficiency”(最佳效率区)。 看来雷总这是要把 AI 变成像“自来水”一样便宜的基础设施。

很多朋友看到 309B(3090亿) 的参数量可能会被吓一跳:这玩意儿跑得动吗? 这里就得聊聊小米这次的“MoE(混合专家)”架构了。
官方推文说得明明白白:Total 309B, Active 15B。 意思就是,虽然它脑容量巨大,但每次干活时,只有 15B 的神经元在“放电”。这就像一个拥有 300 个专家的团队,但你问一个问题,只有最懂行的 15 个人出来回答你。
更骚的操作是它用了一个叫 MTP (Multi-Token Prediction) 的技术。 简单说,传统的 AI 是一次猜一个字,而 MiMo 是一次猜三个字(MTP=3)。 看这个数据对比:开启 MTP=3 后,吞吐量直接飙升到了 14738 toks/s。 这哪是推理,这简直是“为了速度不要命”。感兴趣的可以进链接感受一下这个大模型的回答速度,https://aistudio.xiaomimimo.com/#/

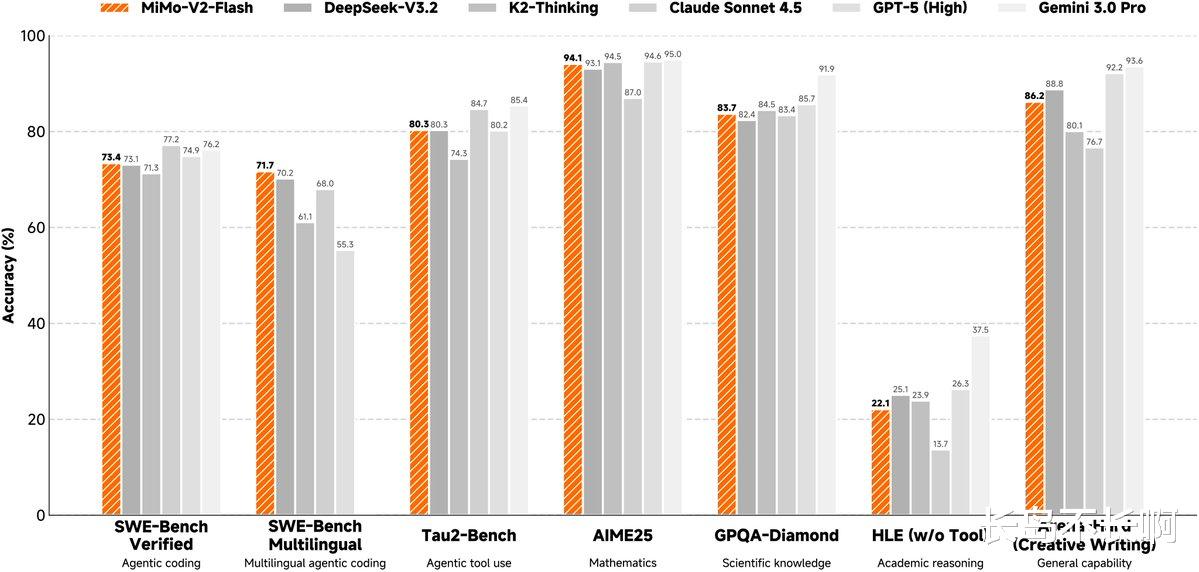
通常这种为了速度牺牲精度的模型,脑子都不太好使。 但 MiMo 这次居然在代码(Coding)和数学(Math)上“反杀”了。
看这张扎心的跑分图:
SWE-Bench Verified (代码能力): MiMo (73.4%) > DeepSeek-V3.2 (73.1%) > Claude Sonnet 4.5 (71.3%)。
AIME 25 (数学竞赛): MiMo (94.1%) 甚至压过了 DeepSeek (93.1%)。
虽然在通用的 Arena-Hard(创意写作)上,它还是略输给 GPT-5 和 Gemini 3.0 Pro,但这定位太精准了——我可能不会写诗,但我写代码、算数是真快啊! 这简直就是为了Agentic AI(智能体)量身定做的:便宜、快、逻辑好,适合大规模部署去干脏活累活。
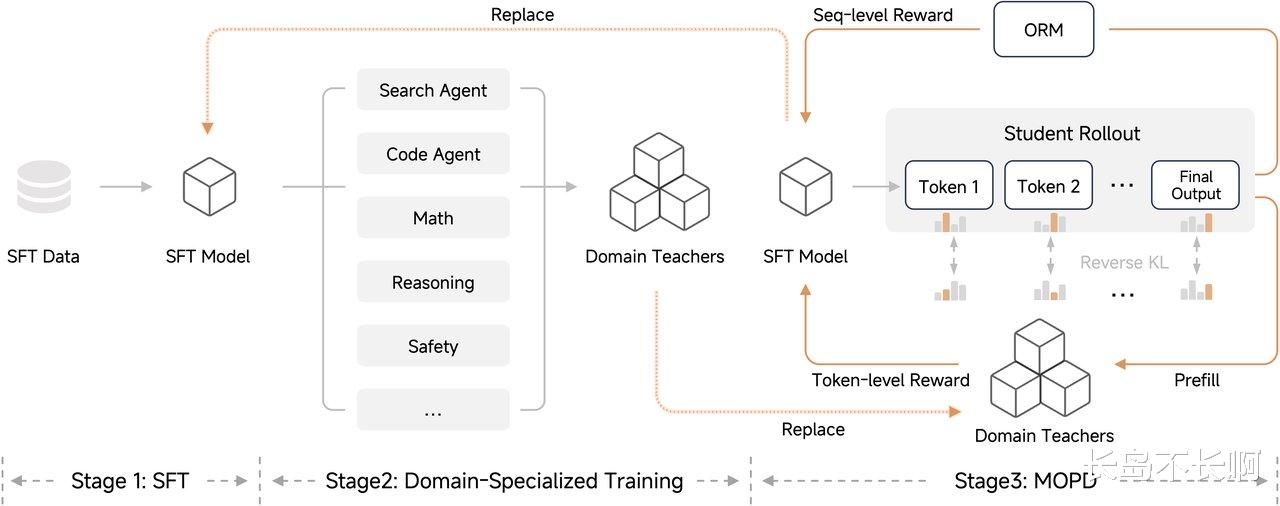
这么强的能力怎么来的?我看了一眼它的训练流程图,发现小米有点东西。
它不是一股脑喂数据,而是分了三个阶段:
SFT(监督微调): 打基础。
Domain-Specialized(领域专精): 这一步关键了,它专门搞了一堆“Domain Teachers”(领域老师),针对搜索、代码、数学进行特训。
MOPD(多目标偏好蒸馏): 最后还要经过一轮像“炼丹”一样的奖励模型(ORM)筛选。
说实话,作为开发者,我看到 MiMo 比看到 GPT-5 还激动。 因为 GPT-5 再强,高昂的费用还是令人望而却步;而 MiMo 这种 $0.1 成本、70%+ 代码通过率 的模型,才是我们手里干活的铲子。
小米这次不仅是卷了价格,更是指了一条路:未来的 AI 不一定是全能的神,但一定是在某个领域极度精通、极度便宜的“超级打工人”。
来,评论区咱们算笔账:
开发者专场: $0.1 的价格,你会考虑把手里的 API 从 OpenAI 换成小米吗?
吃瓜群众: 小米这波“限时免费”,你觉得能持续多久?是不是也是“交个朋友”?
行业观察: DeepSeek 刚坐稳“性价比之王”没几天,就被小米贴脸开大,你觉得它会降价回击吗?