
作者 林易
编辑 重点君
中国云计算市场,正被AI注入一剂强心针。一度增长失速的云厂商们,找到了新的增长引擎,在AI IaaS、AI PaaS、MaaS开始新的竞速。
其中,MaaS 作为大模型的实际负载,反映了大模型最真实、也最一线的市场水温。大模型变革两年半?今天怎么样了?
这两天,国际数据公司(IDC)发布了最新的MaaS中国市场格局——《中国大模型公有云服务市场分析,1H25》,有两个关键结论:
一是,中国大模型公有云调用量迅猛增长。仅2025年上半年,总调用量就达到了536.727万亿Tokens。2024年全年,这个数字是114万亿Tokens。这意味着上半年,就比去年全年增长近400%。 二是,随着MaaS这种商业模式逐渐成熟,市场需求正从模型训练转向模型推理,多模态模型和Agent应用是引爆市场的关键。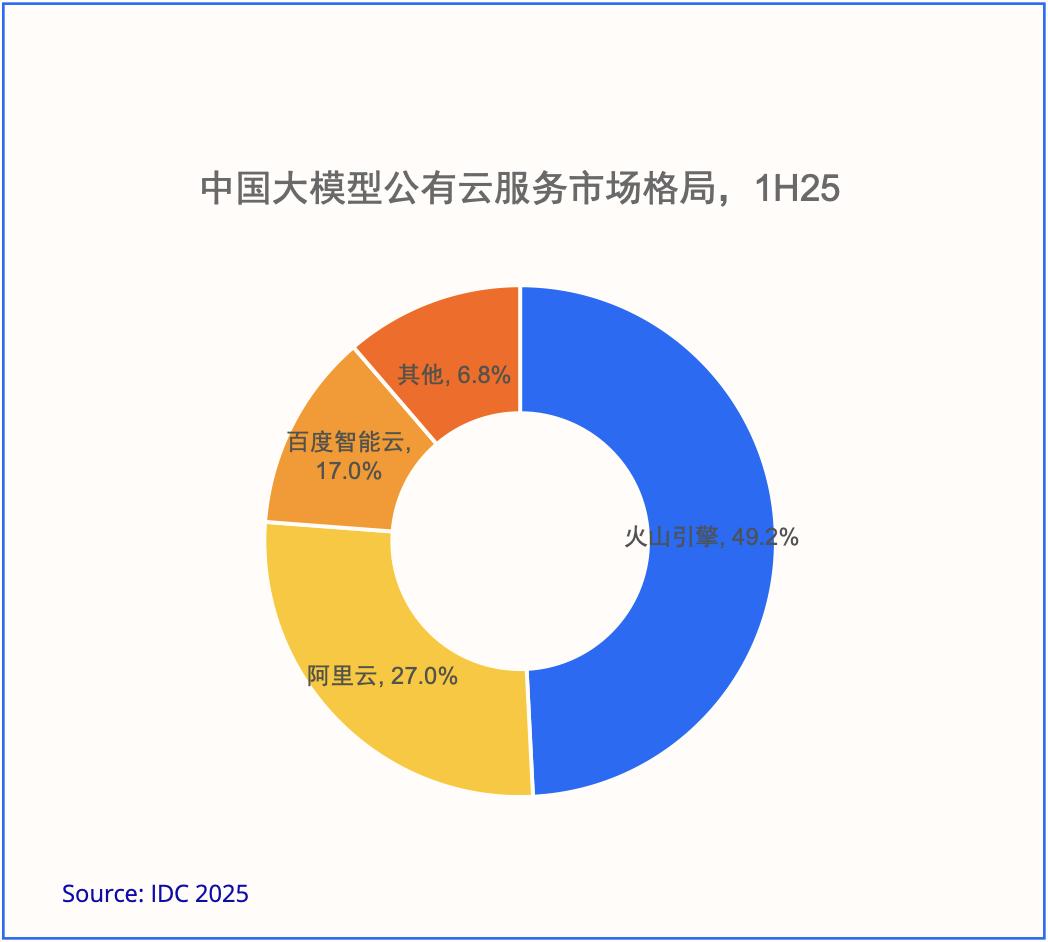
市场格局来看,火山引擎对外部客户提供的大模型调用量位居中国第一,市场份额达到49.2%,占据中国大模型公有云调用量的近半壁江山。这延续了其2024年的强劲表现:去年,火山引擎市场份额为46.4%;截至今年上半年,其领先优势进一步扩大。
事实上,火山引擎推出一方模型调用服务的时间并不算早。直到去年5月,火山引擎才首次对外提供豆包大模型调用服务。有意思的是,也是在那次发布会上,火山引擎总裁谭待就悄悄透露了火山引擎的MaaS战略野心——“大的使用量,才能打磨出好模型,也能大幅降低模型推理的单位成本。”
彼时,豆包大模型主力模型将大模型推理成本从以分计价降到以厘计价。
一位大模型应用开发从业者向我们回忆了这个故事,DeepSeek-V2和豆包大模型把推理成本降低10倍以前,可以说中国没有MaaS,亿级人民币的市场,一个通用的大模型API能否满足企业多样化的需求,都是问号。
“包括今年2月,火山引擎也是第一家推出DeepSeek-R1 API的云厂商。支持DeepSeek模型和直接上线DeepSeek API,这是两种完全不同的选择。而且在那之前火山方舟上只有豆包大模型API,当时直接上线DeepSeek API我很意外”,他说。
MaaS份额第一背后,字节对AI云的目标似乎从一开始就写好了。
01
Tokens调用量,AI云的决胜高点
相较于直接售卖GPU算力,模型调用无论在营收规模还是利润水平,都完全没有可比性,最早头部云厂商MaaS营收普遍只有亿元级别。
但火山引擎一开始就把MaaS放到了战略高度。一位云厂商从业者告诉我们,“火山引擎在MaaS上投入的资源很大,相比现阶段的营收规模,完全是超额投入”,“人家可能就没考虑过靠卖GPU算力赚钱,至少不是优先级”。
这可能与字节做云业务的进场时间有关,火山比同行晚了10年,按照传统方式很难追赶。
火山引擎总裁谭待接受《晚点》的采访时曾表示:“刚开始做火山的时候,管理层还给我布置了一个作业:想象一下十年以后的云,也就是 2030 年的时候,跟 2020 年有什么不同。”谭待想了很久,最终给出的答案是AI。
这让火山在大模型到来时,足够敏锐、果决坚定地锚定MaaS市场。
大模型公有云调用量越多,就能收到越多反馈:模型在企业场景里到底好不好用、哪里不好用、什么场景、什么性能不够好,有了这些真实反馈组成的评测集,才能更快迭代模型。
更强模型、更低成本、更优性能——火山方舟一直以来的迭代方向,正是Tokens调用量的重要性所在,也是大模型时代AI云的规模效应。
这也是字节对AI云的战略选择:调用量越大,模型越好。
于是,火山引擎成为MaaS市场的点火人,锚定模型效果、成本、性能,持续优化,与MaaS市场一路共同成长。
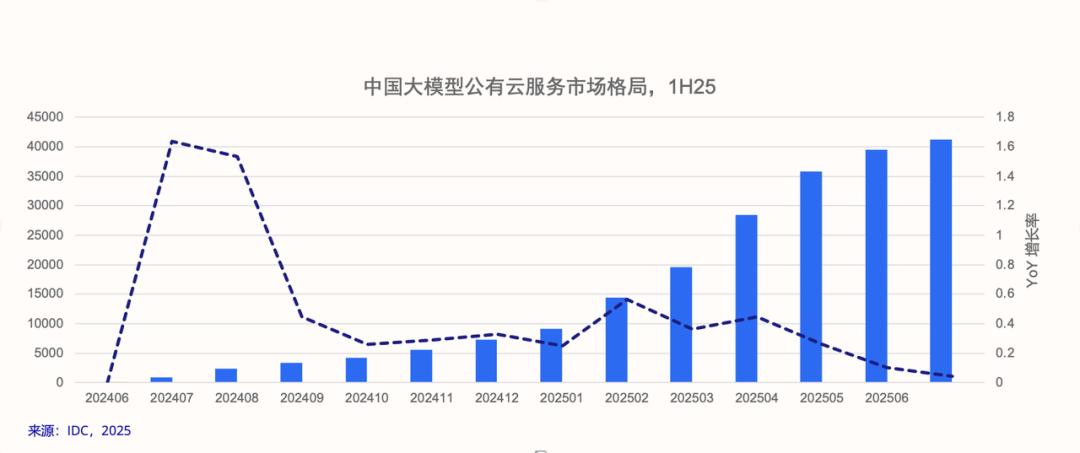
IDC报告显示的中国公有云大模型调用量月度环比增长中,显示了两个关键的增长拐点:
第一个是2024年7月,即豆包大模型技术降本全面发酵之后。在这之前的2024年5月15日,豆包大模型通过模型架构、推理框架等技术创新,将主力模型定价直接从行业的“分计价”拉入“厘计价”时代,降幅高达99.3% 。 第二个,则是2025年2月,DeepSeek-R1 推理模型全面爆火后,进一步加速了MaaS市场的渗透率,AI云负载从预训练时代迈向推理时代。可以说,豆包大模型与DeepSeek的爆红,共同催生了中国MaaS市场。没有人会怀疑AI应用爆发,MaaS市场还在高速增长,火山引擎的份额依然在扩大。
不过当市场被激活,竞争也迅速白热化。2025年以来,所有云厂商都已重兵入局MaaS,这直接考验各厂商的战略定力。
02
为什么是“49.2%”?
对火山来说,为什么能持续扩大在MaaS上的优势?我们认为与三个因素有关:战略、技术和规模。
在字节的版图中,大模型不是一个传统云计算业务,核心目标是探索智能上限,同时火山引擎承载着字节技术能力的“外化”。据报道,2025年字节在AI上的三大目标是:探索智能上限、探索新的 UI 交互形式,以及加强规模效应。
豆包大模型在ToB场景的迭代,依托火山引擎的大模型调用,在这个目标下,火山要成为“最好的、原生的AI云”。
这包含模型和Infra的共同优化。
模型层面,豆包大模型家族在过去一年中快速迭代,目前已覆盖文本、图片、音频、视频、多模态等多个领域,各类模型均处于第一梯队。
在被视为下一阶段竞争焦点的多模态领域,火山引擎更是占据了领先身位。豆包大模型1.6、豆包·视频生成模型Seedance 1.0 pro、豆包·实时语音模型、豆包·图像创作模型Seedream 4.0等,多个大模型登顶Artificial Analysis。在全球盲测权威评测 LMArena 竞技场,Seedream 4.0 的文生图能力甚至超越最近大火的Gemini 2.5 Flash(Nano-Banana)。
这些多模态大模型有效加速了AI应用落地。例如在K12在线教育、智能巡检等场景,视觉理解模型(VLM)的引入,带动了Tokens消耗5个月增长12倍,并快速实现了日均百亿Tokens的突破。
Infra层面,火山引擎MaaS平台火山方舟以极致服务和先进技术为主要特点,能做到模型API在吞吐、并发、首字延迟、平均延迟、成本优化、资源保障、安全可信这些客户可感知指标上,均为行业领先。
在算子层(算法优化)、系统层(PD分离),火山方舟也对模型进行了深度优化,包括:PD分离架构、KV-Cache缓存加速、自研推理加速引擎 xLLM、自研 vRDMA 网络等。
大模型以来,技术主体正在从Web、APP到Agent的变迁中,这意味着开发范式将发生重大变化,Agent广泛渗透需要全栈技术的重构。
在承接最多市场需求的推动下,火山引擎率先推出以大模型为核心、以生产级可用的复杂Agent为负载的AI云原生架构,帮助开发者屏蔽底层硬件差异和开发复杂性,直接从云端获得高质量、低成本的 Tokens,加速企业Agent落地和业务创新。
最后规模上。云计算高固定成本、低边际成本,规模决定一切,火山引擎的规模,来自“内外同源”机制。
在字节跳动内部,火山引擎的基础设施团队与服务抖音、广告等海量业务的团队是同一个大团队。这意味着,在外部客户提出需求之前,火山引擎早已在内部“练手”,它必须稳定支撑起推荐、广告等超大规模的稀疏模型训练 。
这种“内外同源”,让火山引擎得以将在内部真实战场上(In-house)验证过的、最成熟的技术,近乎无损地“外化”为对外部客户的服务。
03
AI云的马拉松才跑500米
大模型的竞争还在早期。谭待曾用一个比喻来形容当前的AI竞争:“如果把AI发展看作一场马拉松,可能现在才跑了500米”。
49.2%中国第一的份额,已经是当下市场对快速行动和战略坚决的大模型厂商做出的选择。而在Tokens调用量上的领先,也是火山引擎定义AI云标准和服务范式的胜负手。
眼下,火山引擎作为“你的下一朵云”,正在进化为“你的AI云” 。