我的知识库开始自己更新,Obsidian+Codex
作为一个非常不喜欢整理繁琐资料的P人,在深度使用AI做长期项目后,逐渐意识到要让AI渗透到更多的流程节点中,沉淀积累是基石,这样才能让AI有明确的背景、方法、规范和边界。
那如何让一个P人能够更轻松的管理一个庞大的知识库呢?那就涉及到“自生长知识库”这个概念了,相当于AI进行自主管理。
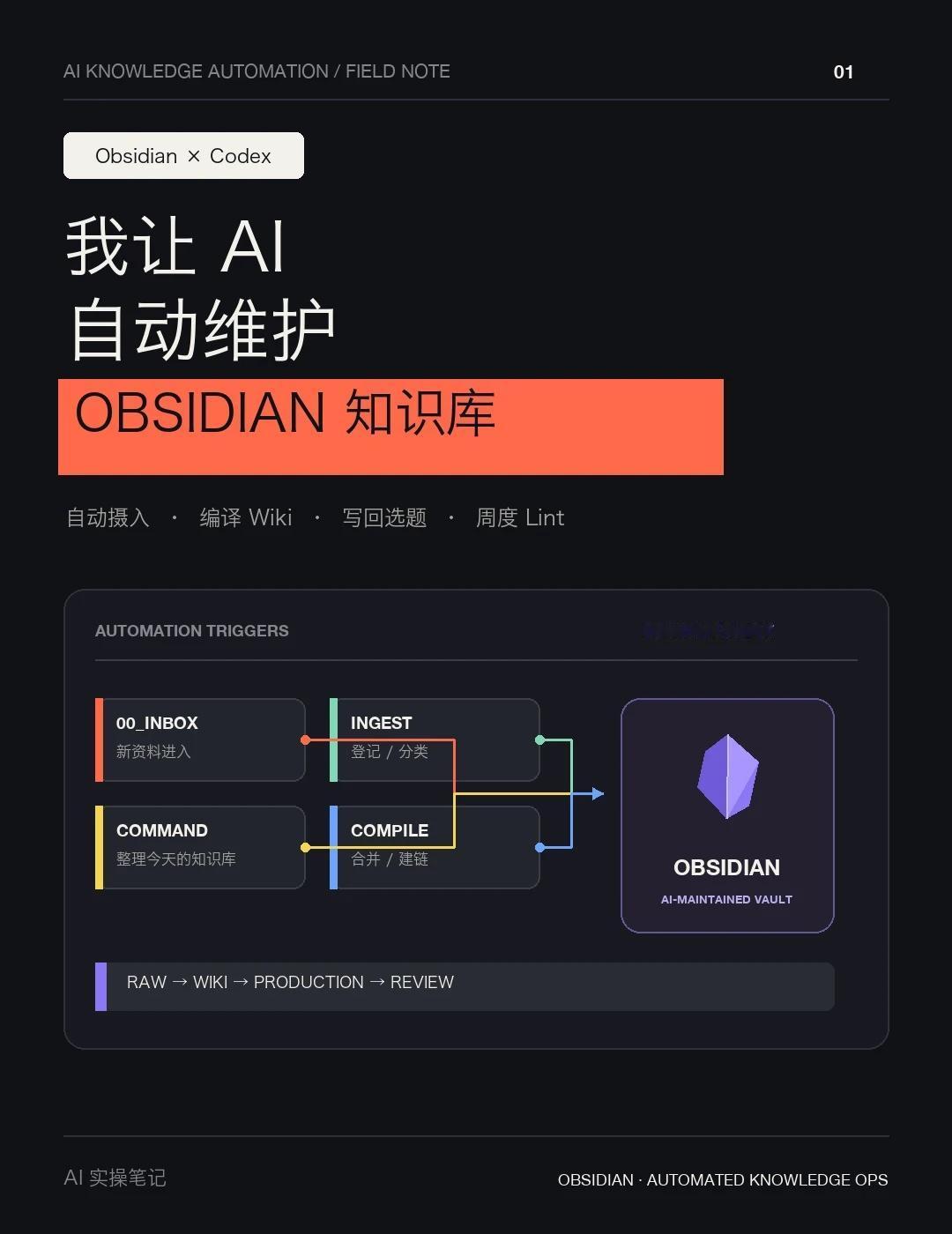
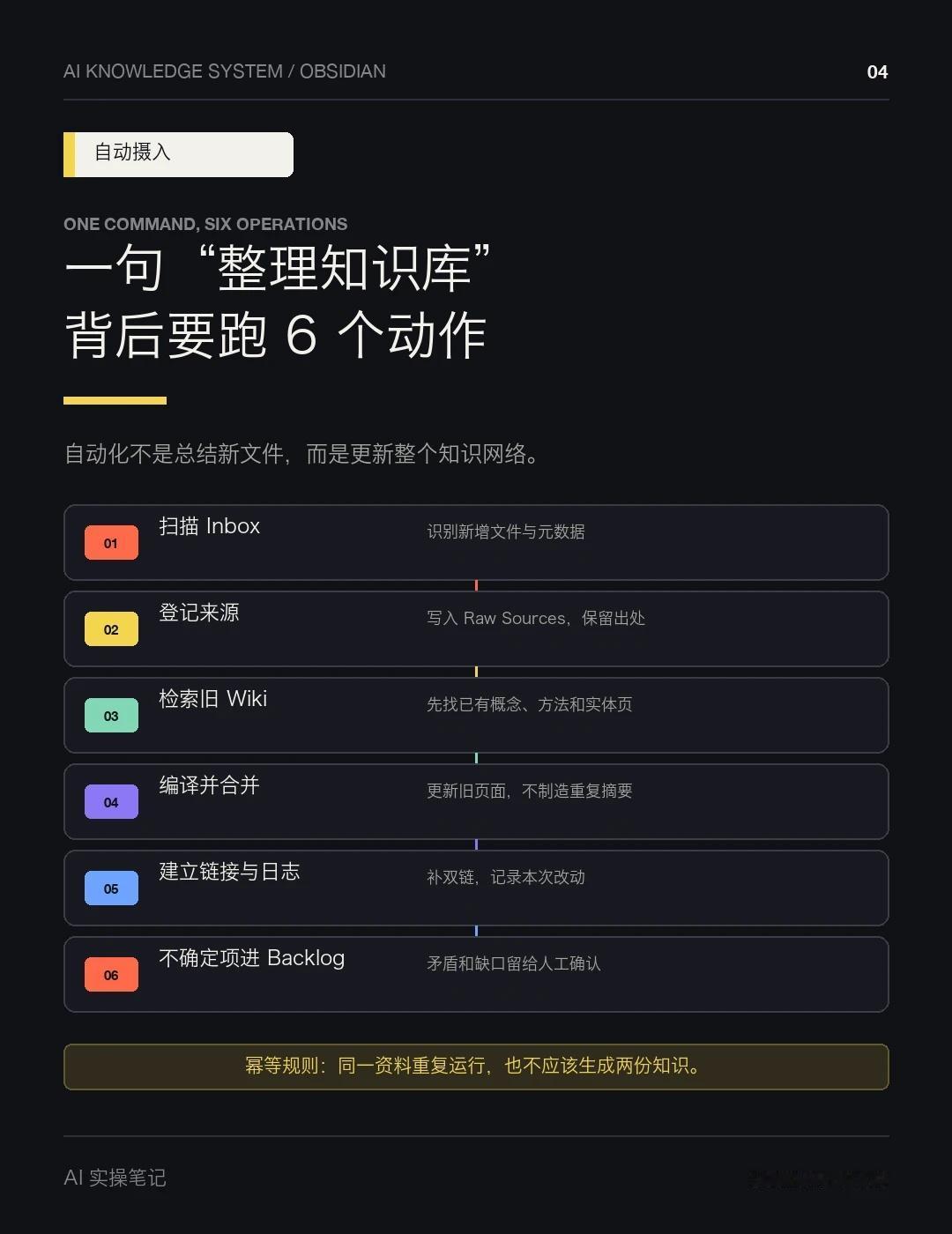
这里的“维护”不是让 AI 给新文件写摘要,而是它能扫描 Inbox、登记原始来源、检索已有 Wiki、合并新知识、补双链、写变更日志,再把冲突和不确定项放进 Backlog。
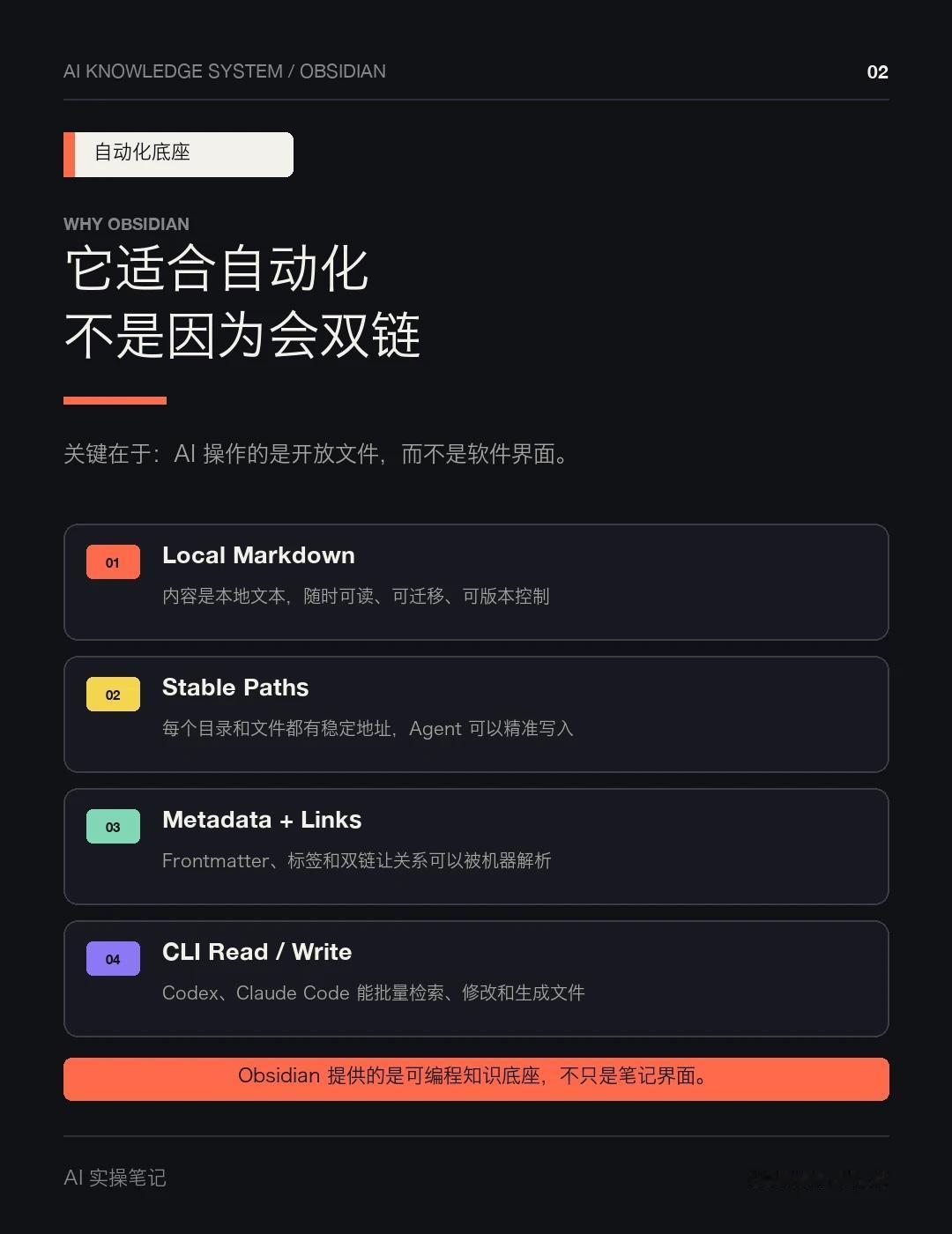
我选择 Obsidian,主要看中四件事:
内容是本地 Markdown;目录和文件路径稳定;Frontmatter、标签、双链可以被机器解析;Codex、Claude Code 能直接通过文件系统和命令行读写整个库。
这些条件凑在一起,Obsidian 才从一个笔记软件变成可编程的知识底座。
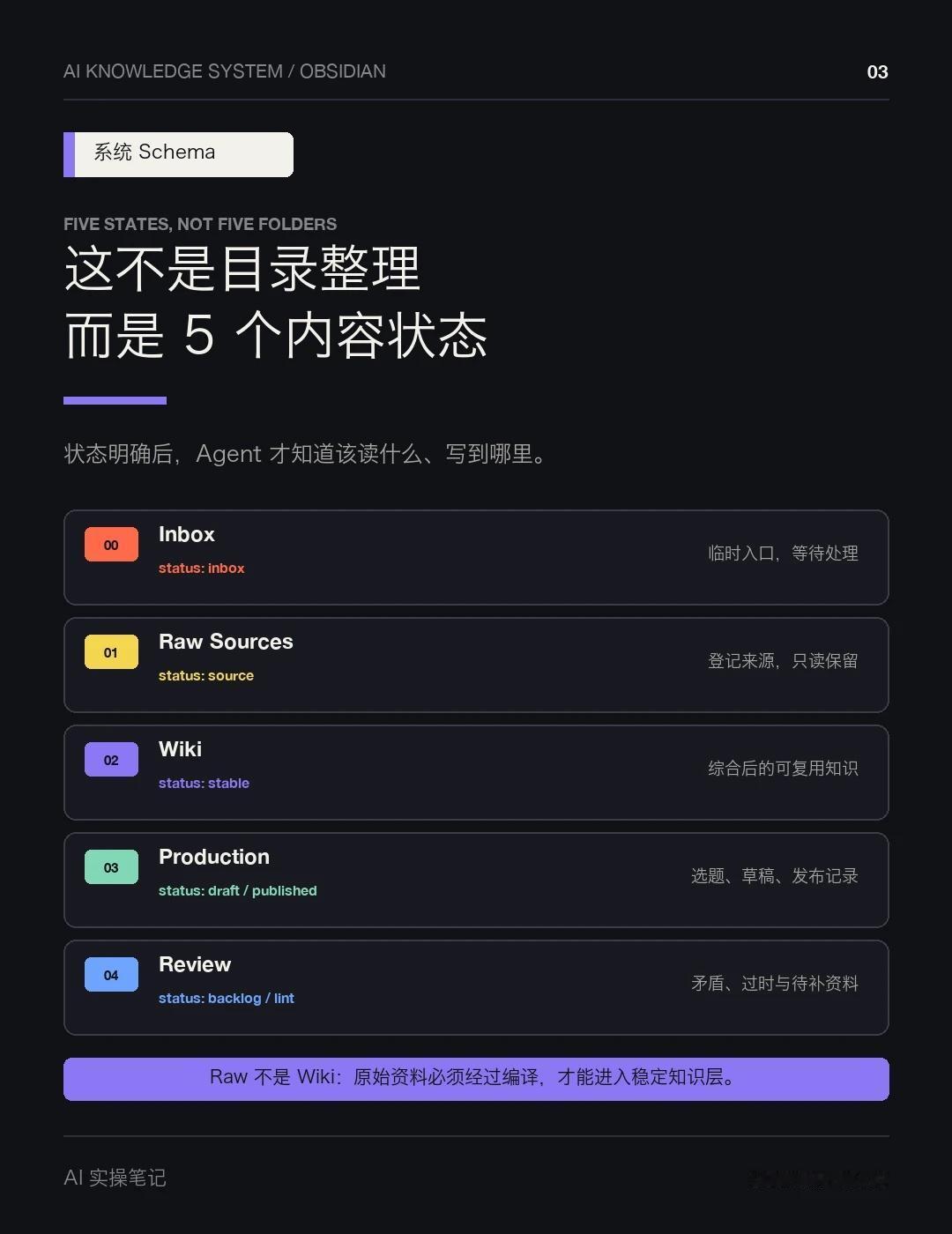
我的库目前分成五个状态区:
00_Inbox 放待处理资料;01_Raw_Sources 登记来源并保留原文;02_Wiki 只放综合后的稳定知识;03_Production 管选题、草稿和发布记录;04_Review 收矛盾、过时内容、Lint 和待补资料。
原始资料不会直接复制进 Wiki。
AI 要先检索旧页面,判断这是新概念,还是对已有方法的补充。能合并就更新旧页,不能确认的内容进入 Backlog。这样重复运行同一批资料,也不会生出一堆内容相近的摘要。
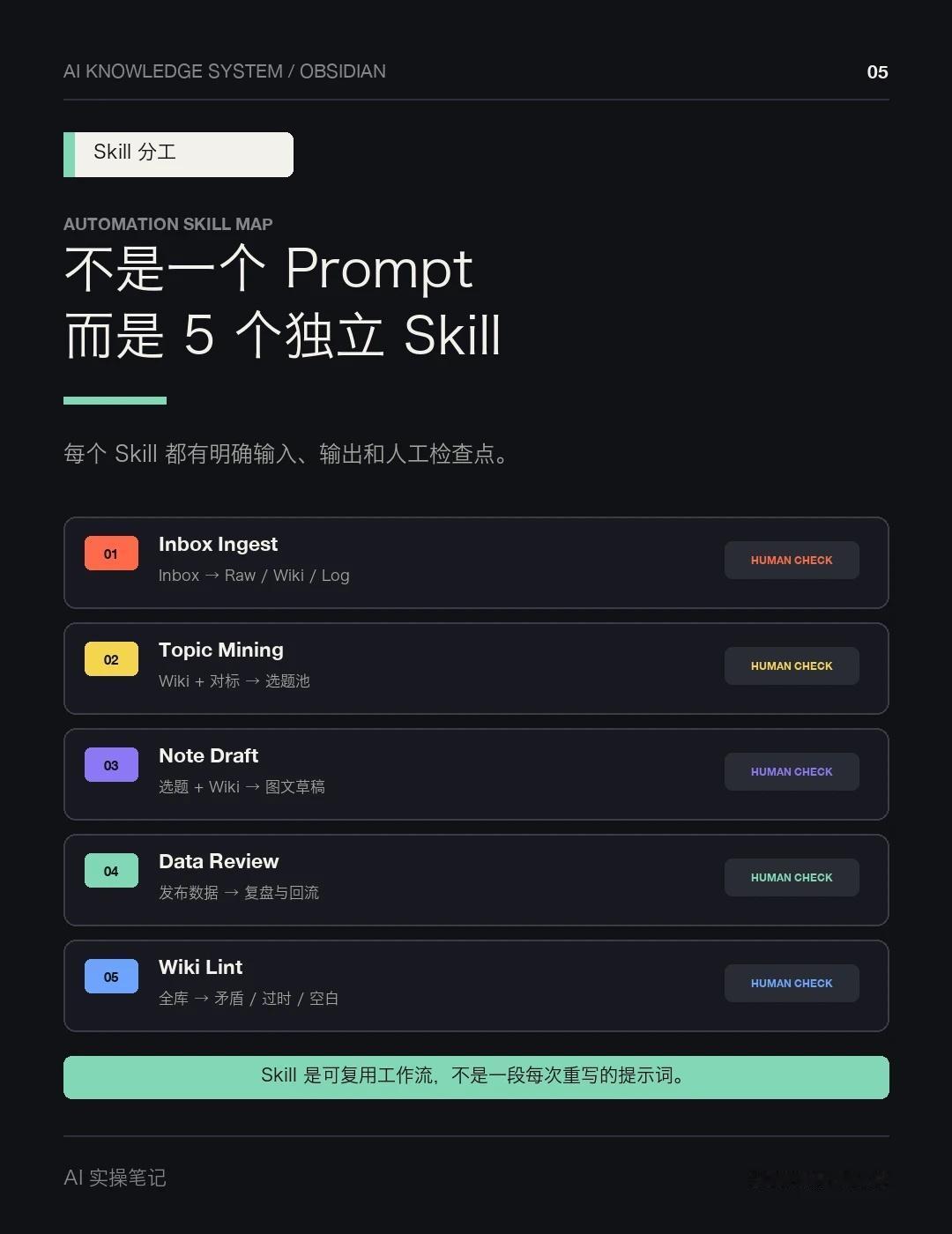
在内容生产这边,我又拆了几个独立 Skill:资料摄入、选题挖掘、草稿生成、发布数据复盘和 Wiki Lint。每个 Skill 都有固定输入、输出和人工检查点。
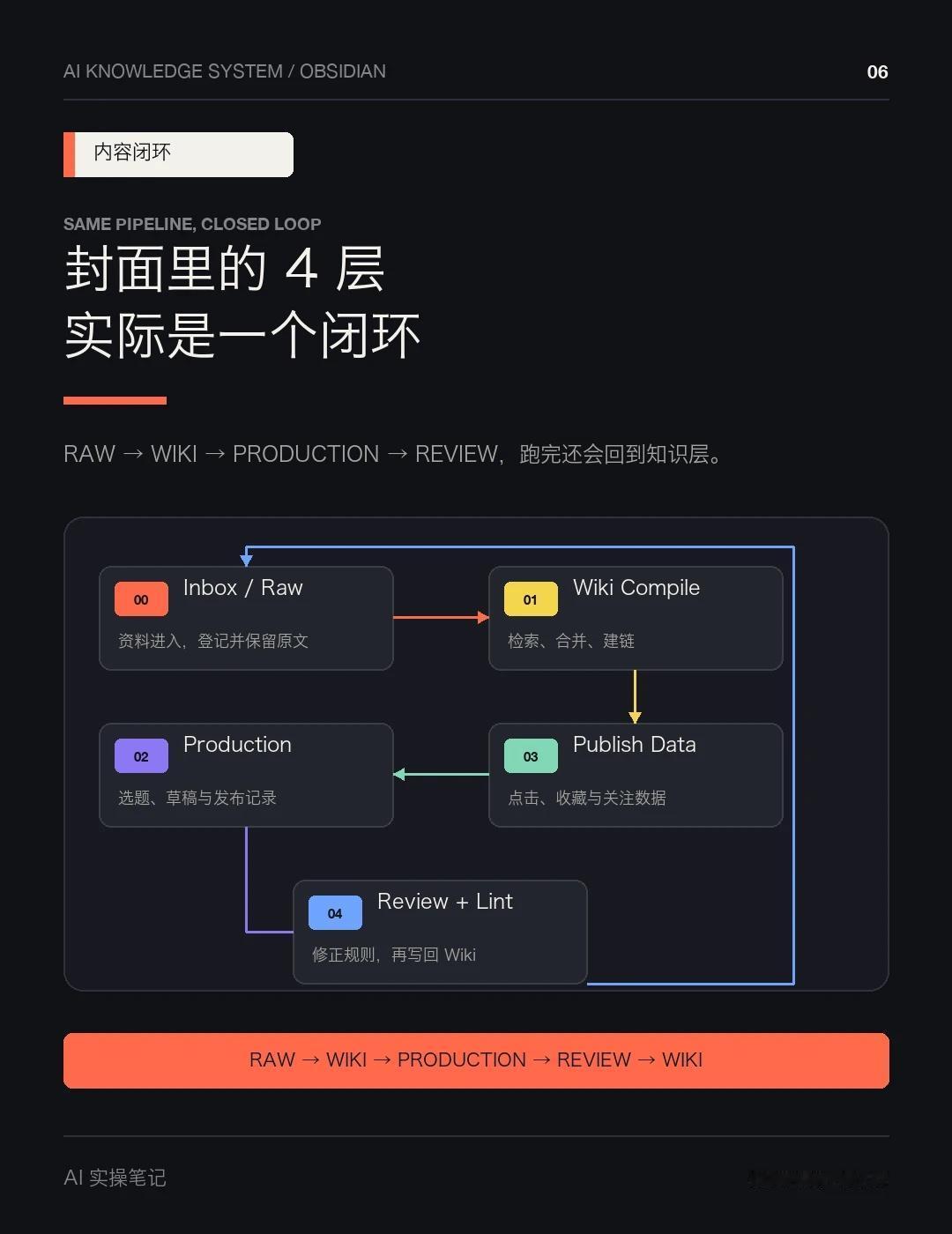
最终形成的是一个闭环:
抓取对标资料 → 编译进 Wiki → 生成选题和草稿 → 发布 → 数据复盘 → 修改 Wiki 和生产规则。
AI 可以自动做扫描、分类、合并、建链和初稿。来源真假、冲突怎么取舍、哪些判断能代表账号,还是得人工确认。
后面我会逐个节点拆解,如何将这个知识库与自媒体运营自动化结合起来提效。
howto用好AI Obsidian 知识管理 AI工具 AI工作流 ChatGPT Claude Codex 效率工具