[CL]《Reinforcement Learning with Metacognitive Feedback Elicits Faithful Uncertainty Expression in LLMs》G K Liu, A Caciularu, G Yona, I Szpektor… [Yale University & Google Research] (2026)
在可靠 AI 领域,使模型“忠实地”表达其不确定性是一个悬而未决的难题。过去的方法(如提示词工程或监督微调)受困于任务准确率下降和表达方式僵化,本质原因是这些方法仅在输出层面进行修补,未能触及模型对自身认知过程进行监控与调节的“元认知”能力。
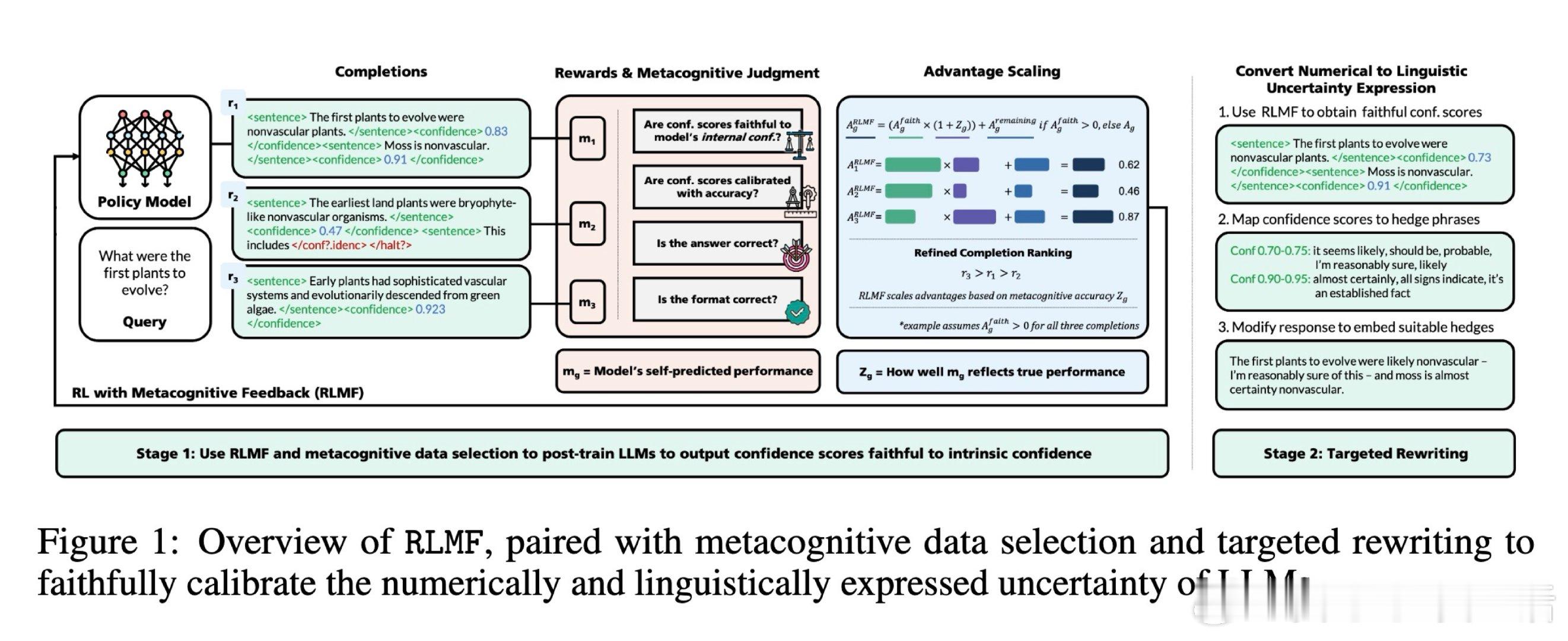
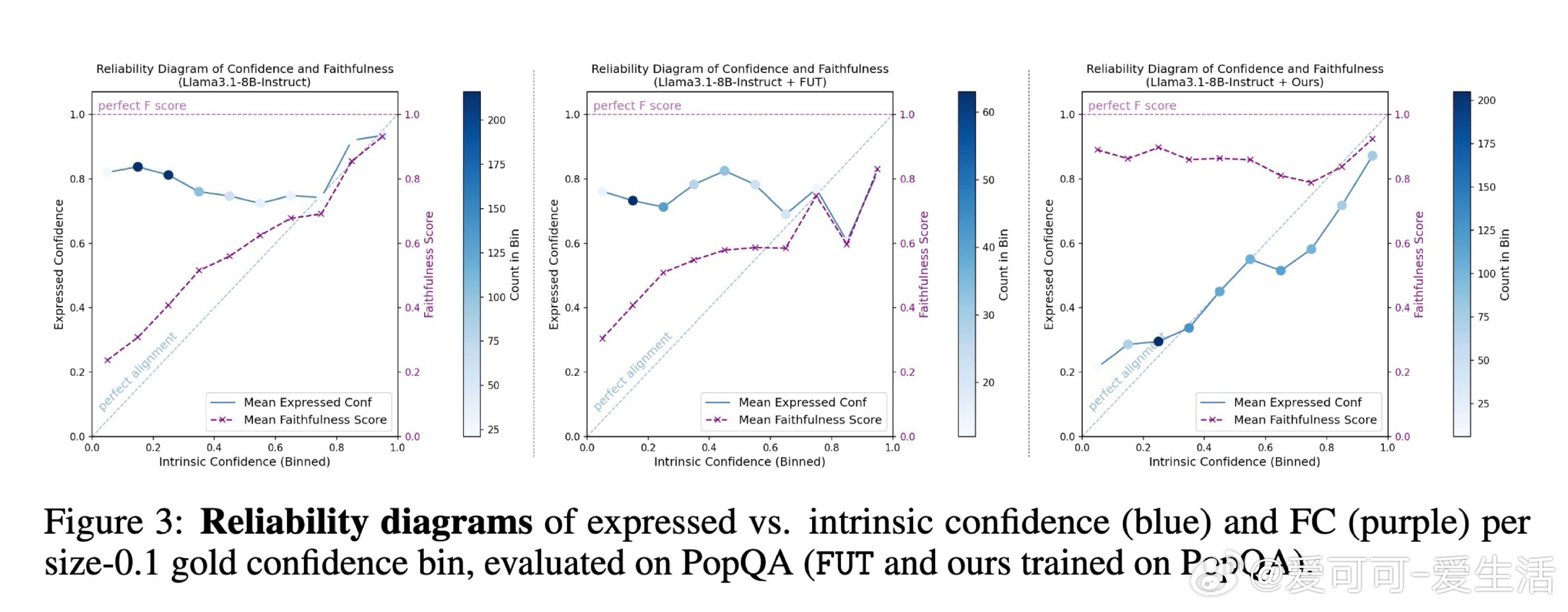
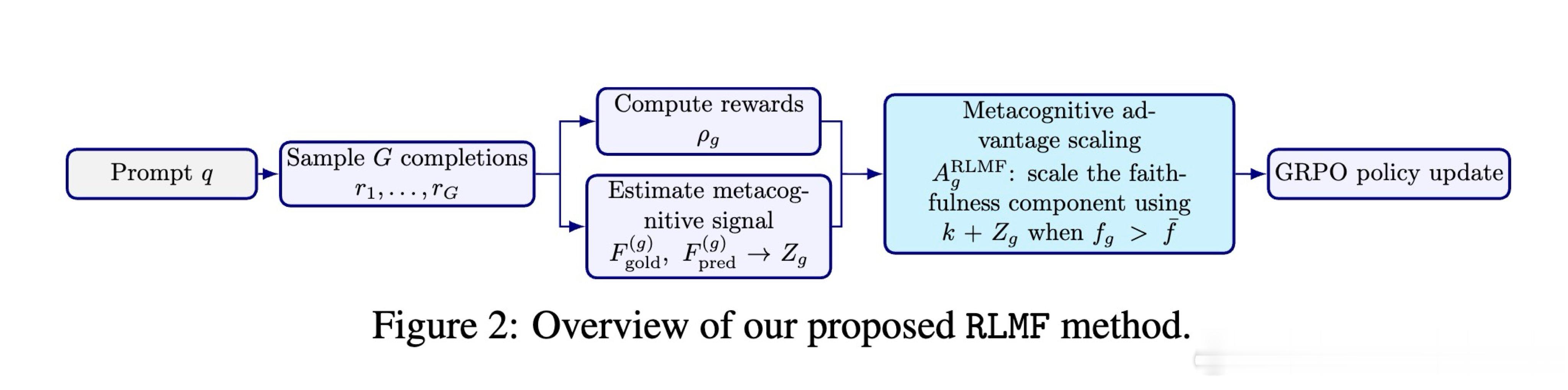
本文的核心洞见是:把模型对自身表现的评价准确度直接作为强化学习的奖励信号。由此,RLMF 这一关键操作使问题得以解开:它不仅奖励正确的回答,更奖励那些“能准确预测自己是否答对”的回答;配合元认知数据筛选和自动化重写,模型学会了将其内部的真实置信度精准映射为自然语言中的委婉表达(如从“我确定”改为“我推测”)。
这项工作真正留下的遗产是证明了元认知性能可以作为一种高效的内部反馈信号,使小模型在不确定性表达的“忠实度”上超越了 GPT-4 等巨型模型。它为后来者打开的新门是通往具备自我进化能力的“觉知型”AI 架构,但尚未跨过的门槛是如何在极其复杂的长文本推理中保持这种元认知监控的实时性与一致性。
arxiv.org/abs/2606.32032 机器学习 人工智能 论文 AI创造营