[CL]《REAR: Test-time Preference Realignment through Reward Decomposition》F Zhang, P Wang, C Li, Y Li… [Nanyang Technological University & UC Berkeley] (2026)
在大语言模型领域,如何让模型在推理阶段动态满足用户的多样化偏好(如特定语气、避开某些话题)是一个悬而未决的难题。过去的方法受困于高昂的微调成本或仅限于数学等可验证领域,本质原因是模型内置的奖励函数是静态且耦合的,难以在不重新训练的情况下精确放大或缩小特定偏好的权重。
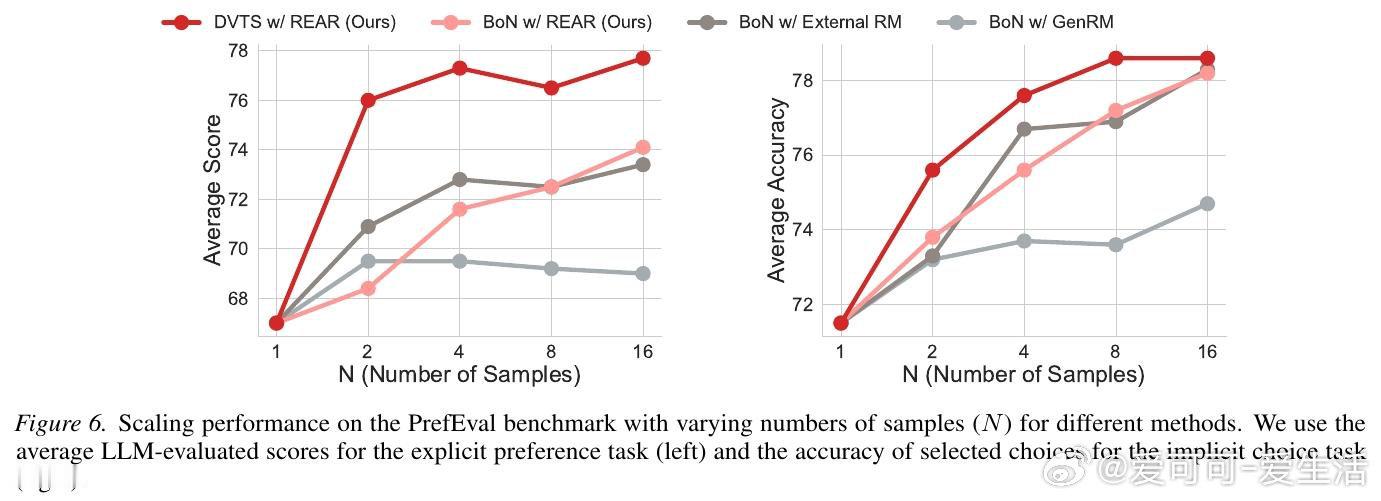
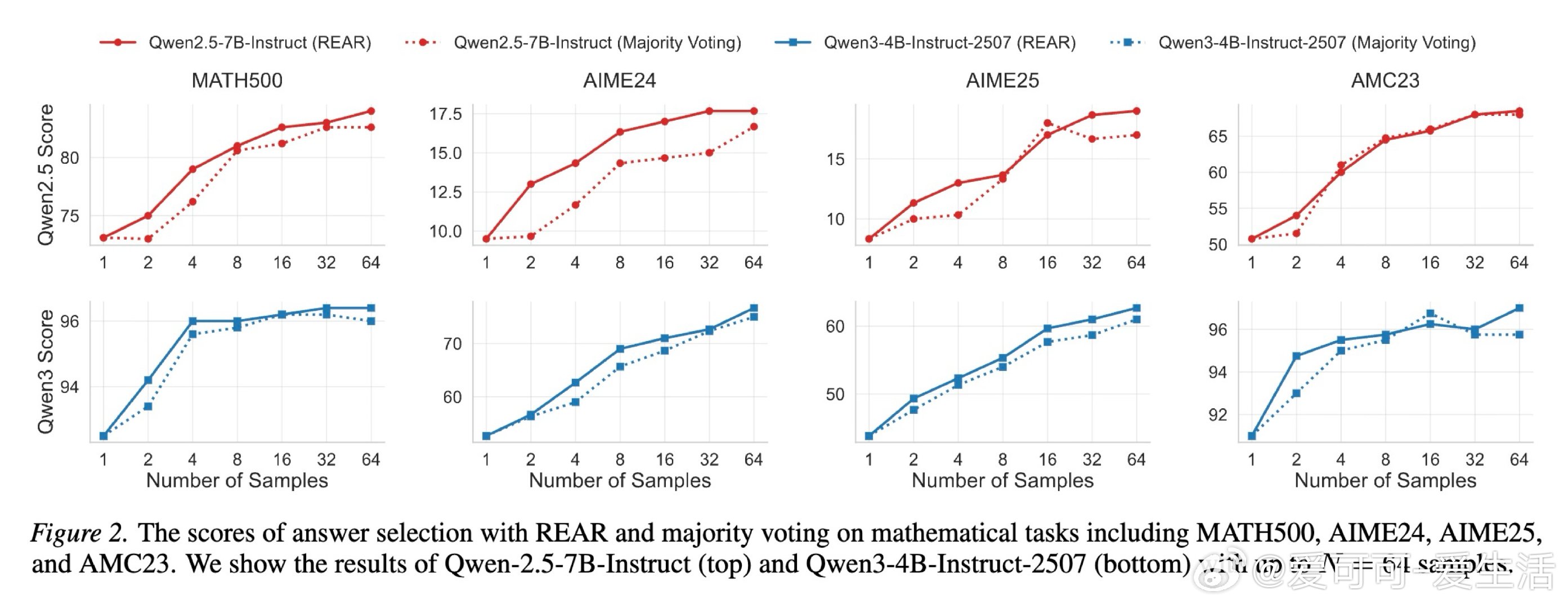
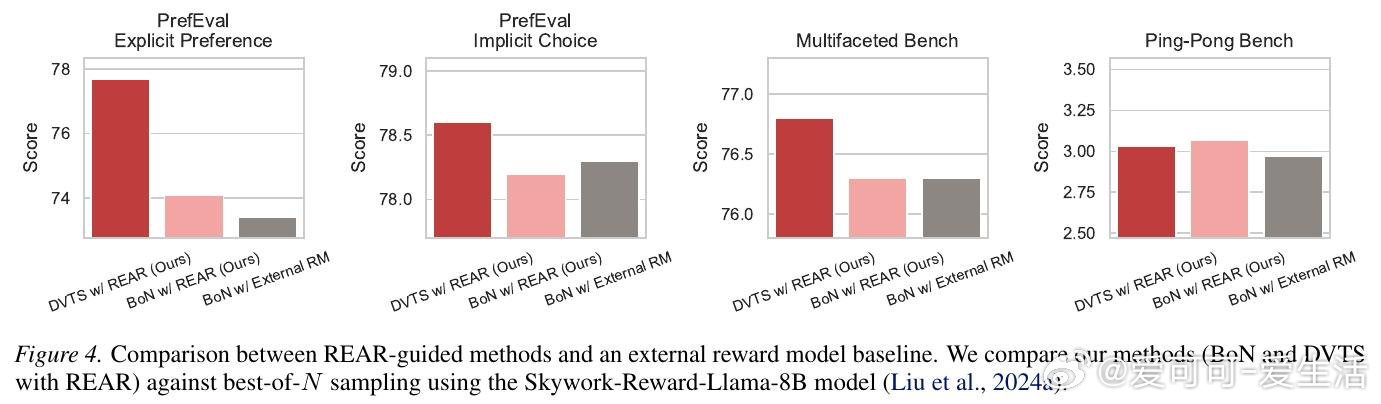
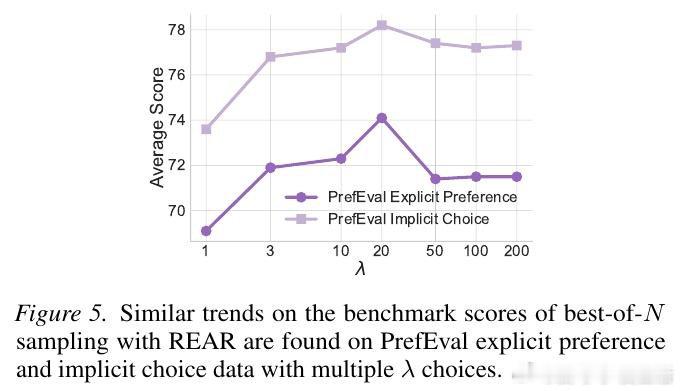
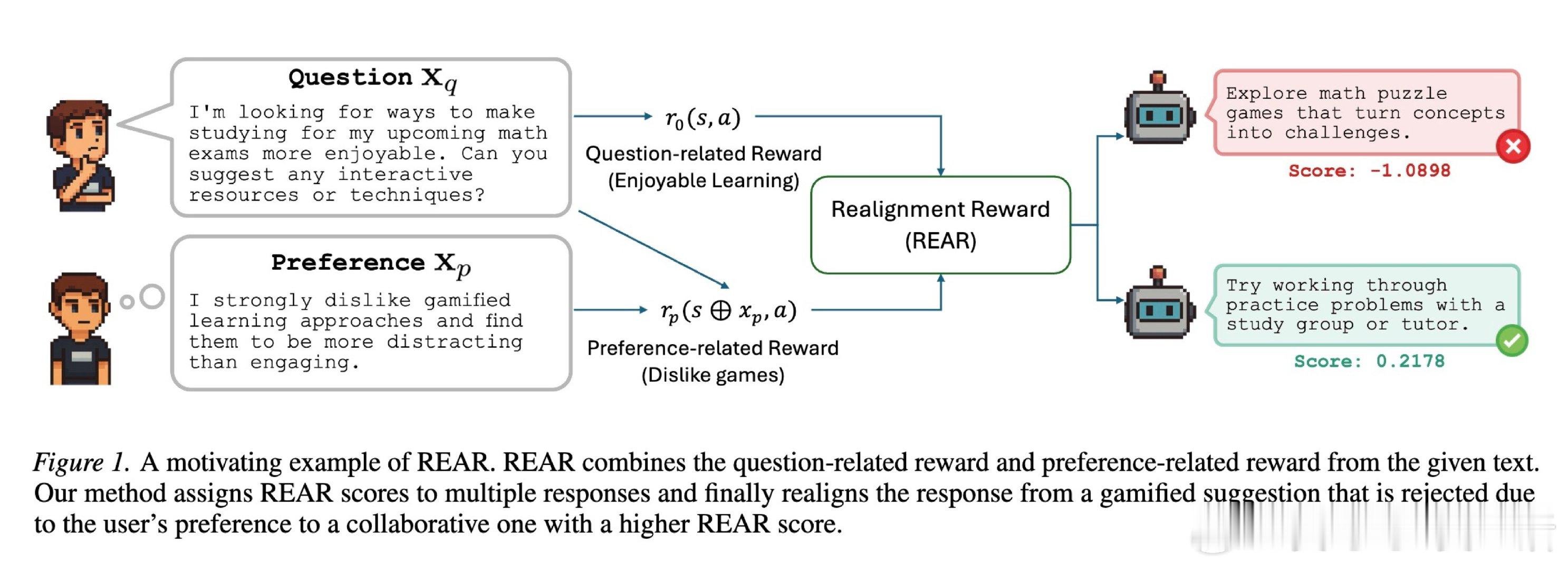
本文的核心洞见是:把预训练模型的隐式奖励分解为“问题相关”和“偏好相关”两个独立分量。由此,REAR 这一关键操作通过对这两个分量的对数概率进行线性重缩放,使模型无需额外奖励模型即可在推理时自我评估,并通过最佳采样(Best-of-N)或树搜索动态锁定最符合特定偏好的响应。
这项工作真正留下的遗产是证明了模型自身即是高效的偏好验证器,无需外部模型即可实现测试时性能缩放。它为后来者打开的新门是将复杂的主观偏好对齐转化为可量化的搜索优化问题,但尚未跨过的门槛是这种线性分解在面对极度冲突的多目标偏好时,如何维持逻辑连贯性与响应质量的完美平衡。
arxiv.org/abs/2606.30339 机器学习 人工智能 论文 AI创造营