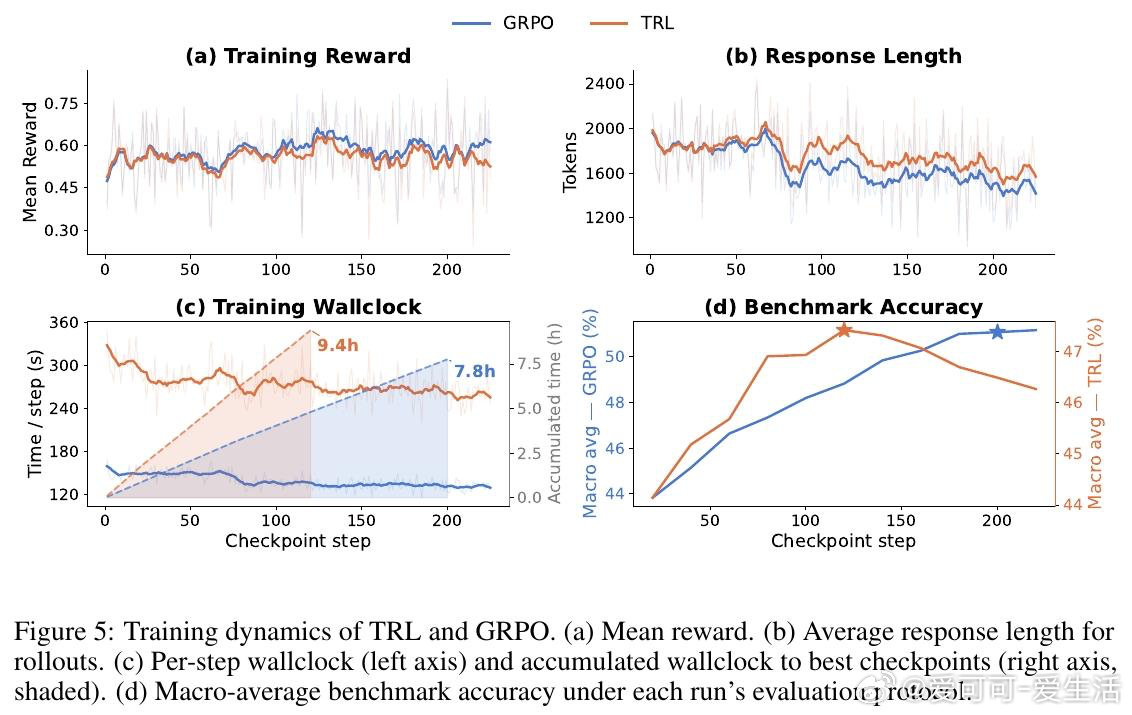
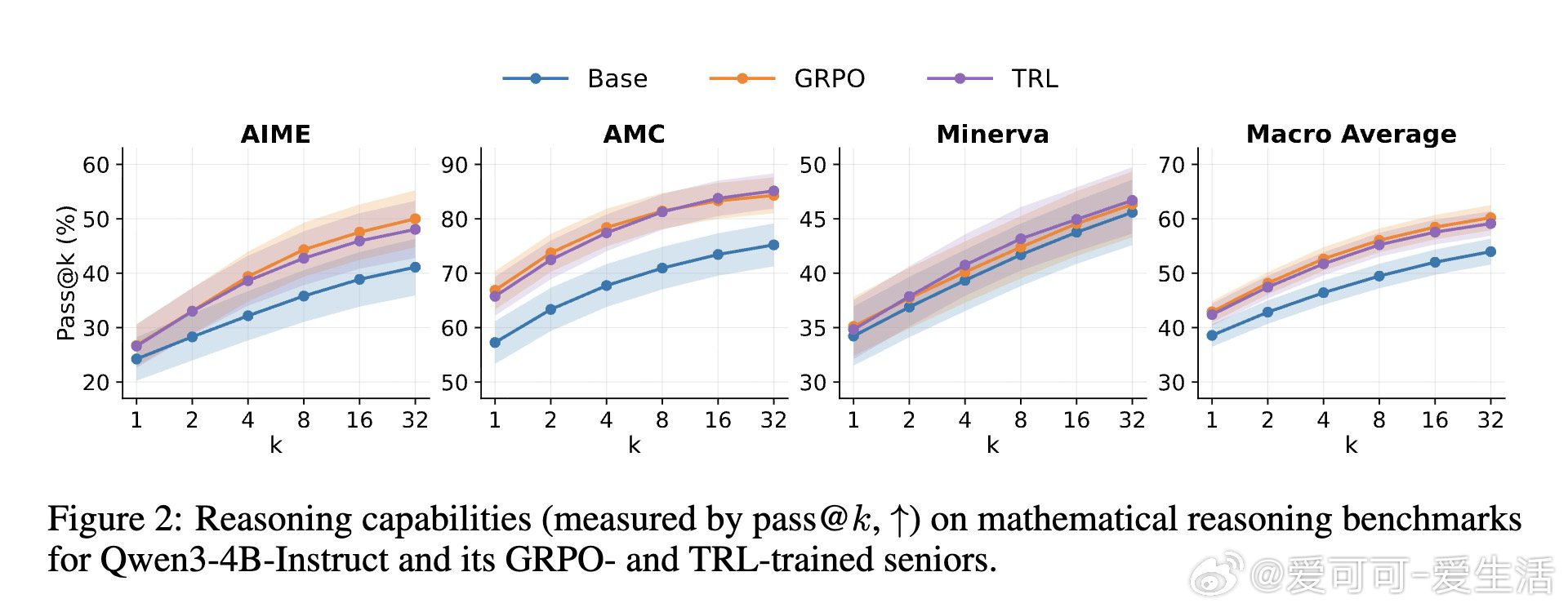
[LG]《Tandem Reinforcement Learning with Verifiable Rewards》D Jiao, R Singhal, R West, A Anderson [University of Toronto & EPFL] (2026)
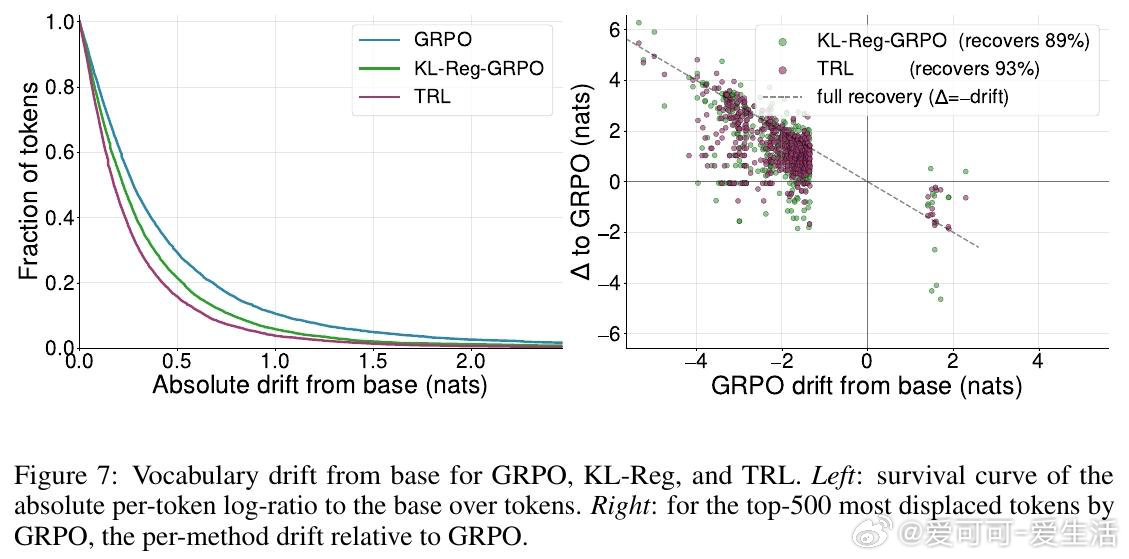
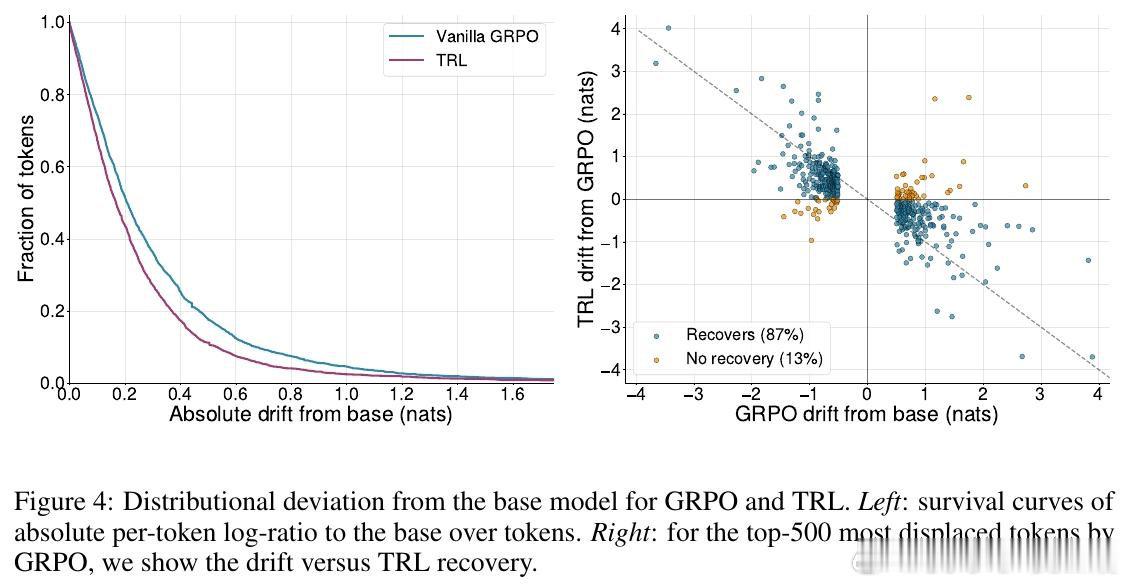
在数学推理领域,强化学习(RLVR)虽能催生专家级性能,却常导致模型陷入“兼容性困境”。过去的方法受困于模型性能与可读性的脱节,本质原因是纯结果导向的奖励机制诱导模型产生了诡谲、不可读的“私有语言”,使弱模型或人类无法理解或协作。
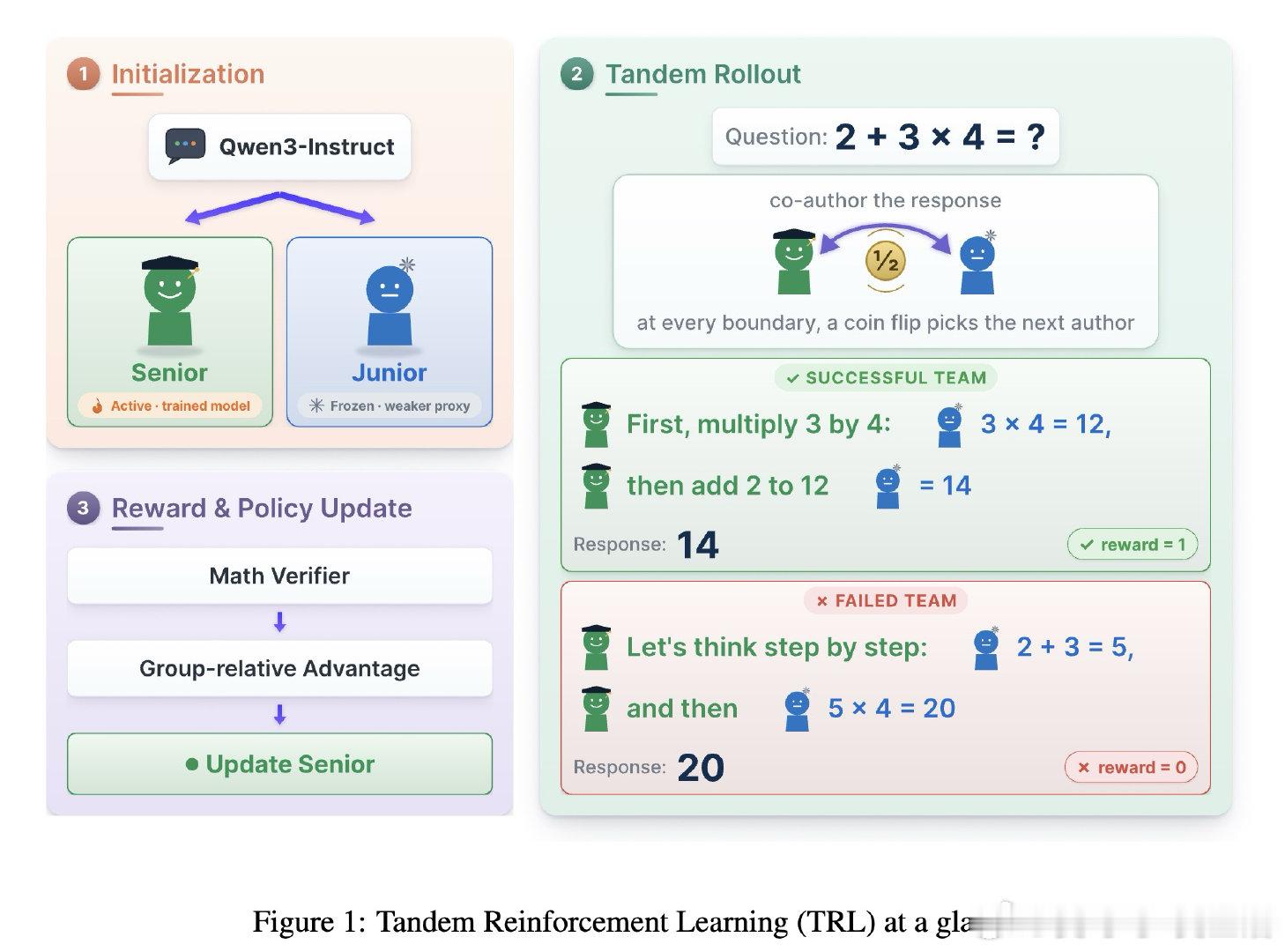
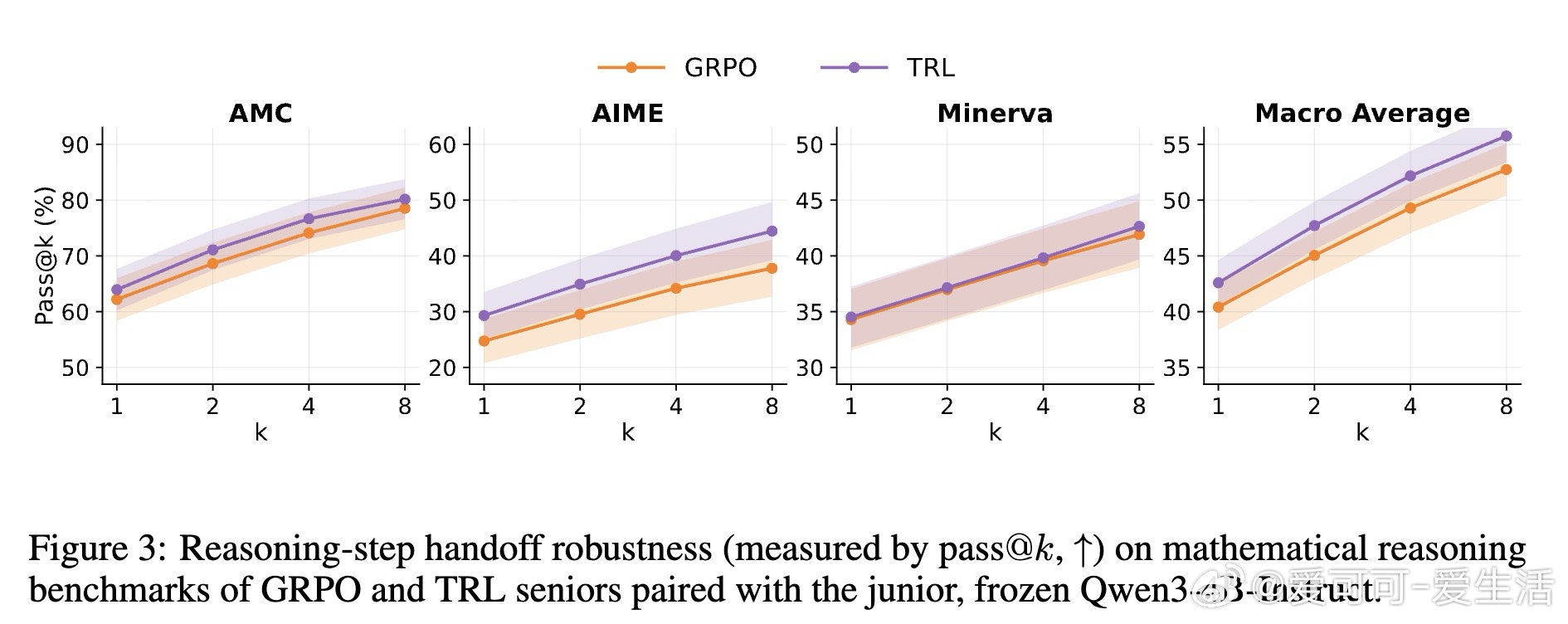
本文的核心洞见是:把推理过程重新看作一场“双人接力赛”。通过让受训的高级模型与冻结的基础模型在词级别随机交替生成内容,这种“串联强化学习”机制迫使高级模型必须产出弱模型也能“接得住”的逻辑。这种结构性约束让模型在进化过程中,必须兼顾逻辑的正确性与表达的通用性。
这项工作真正留下的遗产是证明了推理能力与模型兼容性并非零和博弈。它为后来者打开的新门是“社会化锚定”的强化学习范式,即在不牺牲性能的前提下抑制分布偏移;但尚未跨过的门槛是,这种机制在面对能力跨度极大的异构伙伴或真实人类监督时,其鲁棒性仍待验证。
arxiv.org/abs/2606.28166 机器学习 人工智能 论文 AI创造营