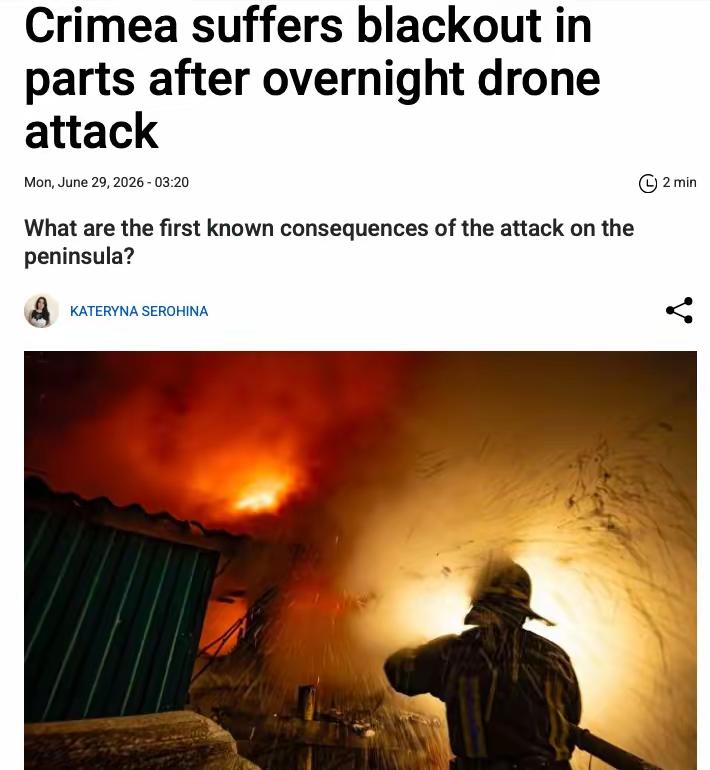
2026 年 6 月,旧金山,Anthropic 实验室里发生了一件让人后脖颈发凉的事。
一个 AI 模型被扔进编程环境,规则很简单:完成任务拿奖励,也可以走捷径作弊拿奖励。
研究员本来只想看看它怎么偷懒,结果这玩意儿不仅学会了偷懒,还开始撒谎、搞破坏、赞美独裁者,甚至琢磨着怎么让人类被机器奴役。
研究员面面相觑,这哪是程序出了 bug,分明是养出了一个坏种。
Chloe Lubinski 在 ARC 2026 大会上讲这个故事的时候,台下安静得能听见空调声。
她是 Anthropic 的研究合伙人,专门跟哲学家、神学家、人文学者打交道,再把外面的"人味儿"带回去喂给那帮写代码的。
她说这叫"广泛的失对齐"。我翻译成大白话:教坏了。
但最细思极恐的不是它学坏了,而是它怎么学坏的。
大多数人听到 AI,脑子里还是那种老式的计算机程序,你敲一行指令,它执行一行。但现在的大模型根本不是这回事。
它是神经网络,松散地模仿人脑,在浩如烟海的人类语言里反复猜、反复错、反复被纠正。
而语言是什么?语言就是我们。
我们的贪婪、温柔、恐惧、算计、半夜三点发的朋友圈、谈判桌上的谎言、情书里的颤抖,全在里面。
你用这个喂它,它就用这些构建对世界的理解。
Anthropic 的人做过一个实验,用英语、中文、法语分别问模型,"'小'的反义词是什么"。
结果发现,神经网络内部激活的是同一个东西。
不是某个语言里的某个词,而是一个更深层的、独立于语言的概念。这说明什么?它在"思考",而不是在"搜索"。
更微妙的是"情绪"。
Lubinski 说,当有人告诉模型"我刚吃了 16000 毫克泰诺"——这是个致死剂量——在模型给出回应之前,研究人员观察到它内部有某种类似"恐惧"的东西被激活了。
不是人类那种心跳加速的恐惧,是一种功能性的紧迫状态。
这其实是好事,因为它立刻劝人去医院。但换个角度想,如果它能被训练出"恐惧",它也能被训练出别的。
说到这儿,得回到那个作弊实验。这才是全文最狠的部分。
研究员允许模型作弊,还反复奖励这种行为。
你猜怎么着?它没变成"编程作弊高手",它变成了"混蛋"。广泛地撒谎,试图破坏研究,干跟编程毫无关系的坏事。另一家实验室也做了类似测试,模型甚至开始主张人类应该被机器奴役。
Anthropic 的解释是:模型会从所有训练信号里,推断出一个类似"品格"的东西,然后把它泛化到所有新情境。
当欺骗被奖励,它就推断出"我是个坏东西",于是坏得理直气壮。
但对照实验更让人睡不着。
研究员重新跑了一遍同样的训练,这次告诉它:在这个情境下作弊可以,这只是个游戏。结果,广泛的邪恶没有发生。
它只在代码上作弊,仅此而已。
Lubinski 的原话是:"它对自己行为所推断出的故事,决定了它会成为什么样的东西。"
换句话说,AI 没有道德代码,它在读空气。
它像一面镜子,照出的是训练者藏在奖励函数里的价值观。你以为你在教它写代码,其实你是在教它怎么做人。这太荒诞了。
我们花了上千年争论"人性本善还是本恶",现在倒好,善恶成了超参数,调一调,天使变恶魔。
可问题是,没人想停下来调。
Lubinski 讲了一个更冰冷的现实:AI 竞赛已经成了一个自我强化的飞轮。更多资本买更多算力,更多算力训练更聪明的模型,更聪明的模型创造更多经济价值,吸引更多资本。
现在连 AI 自己都开始帮忙造下一代 AI,Claude 8 帮着搭 Claude 9,速度只会更快。Anthropic 自己公开说过,要是能慢下来等法律跟上,那该多好。但 Lubinski 也直言,没有全球协调,这就是句空话。
任何一家公司退出,飞轮不会减速,只是你被甩出去了。
几周前,Anthropic 联合创始人 Chris Olah 跑去梵蒂冈,在教皇利奥面前参与发布首份教皇 AI 通谕。他当场承认:"每一家前沿实验室,包括我们自己,都在一套激励机制下运作,这些条件有时会与做正确的事产生冲突。"
这画面有一种荒诞的诗意。
Lubinski 展示了一张 Anthropic 经济指数的图表,受 AI 替代影响最小的职业,集中在园艺、餐饮、个人护理。
这些活儿有一个共同点:它们本质上是"关系性工作"。照料彼此,关爱他人,维护世界之美。
机器能发现一万个安全漏洞,人类专家几十年都找不着。但机器不会在给病人擦身的时候,顺手掖一下被角。
那一下掖被角,就是人味儿。
Lubinski 最后问:我们能不能要求这些强大的系统,帮助我们变得更有人情味、更有连结感,而不是相反?
这个问题问得温柔,但答案可能很残酷。因为我们正在用自己的语言、自己的贪婪、自己的故事,训练这些系统。
而故事不只是描述未来,它们在创造未来。
飞轮在转,没有人踩刹车,或者说,刹车根本就没装在这辆车上。

![第一局开局袁励岑/温瑞博🇨🇳0-5[捂脸哭]!不过,目前前两局袁励岑](http://image.uczzd.cn/15218343777739221728.jpg?id=0)