GLM-5.2 vs Opus4.8实验对比+团队降本落地方案
一、实验核心数据直观差距
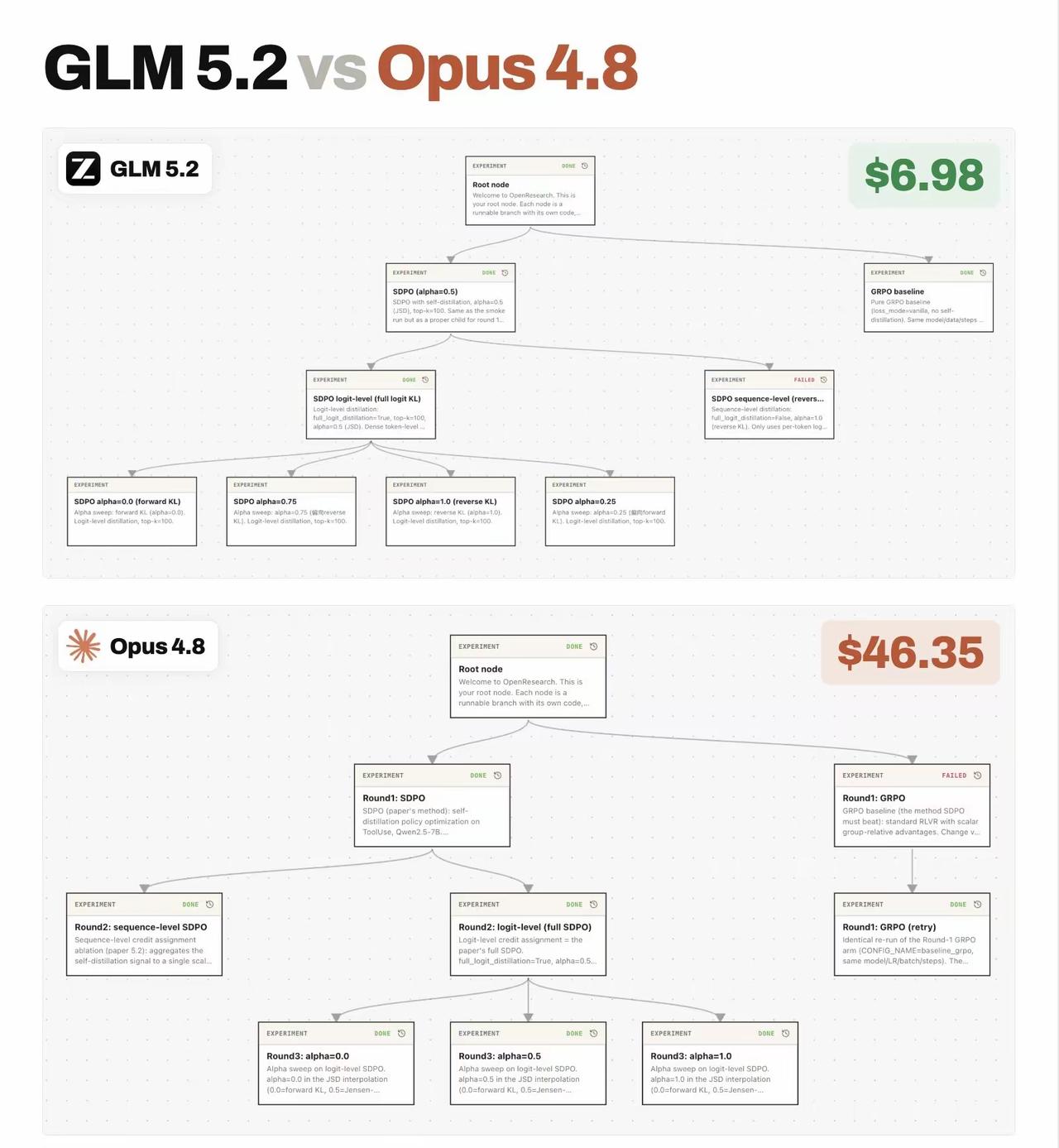
1. 完整同架构Agent实验总消耗
- GLM-5.2 全程总花费:$6.98
- Opus 4.8 完全相同实验链路总花费:$46.35
成本差距接近6.6倍,和海外评测结论“GLM编码场景成本仅为Opus 1/6”完全吻合。
2. 任务完全对等:相同SDPO/GDPO算法树、多层循环实验、多轮工具迭代、失败重试分支,任务复杂度、上下文长度、执行步数完全一致,变量仅模型本身。
3. 表现对齐:长周期代码/Agent探索任务下,两者能跑通完全一样的多层循环工作流,最终实验产出、分支结论无明显差距。
二、不敢用Opus的核心痛点拆解
1. 长循环Agent成本呈指数放大
你们团队现状:Plan-and-Execute自主调试、多轮反思重试、全盘读取项目文件,每一轮循环都会叠加大量上下文,Opus高价输出Token会快速透支预算,出现单日充值3万快速耗尽。
2. 无额度管控下账单不可控
Opus单价高,一旦Loop无熔断、会话长期不重置,几小时自主迭代就能产生数万级费用,老板无法承受每周5万+的研发算力开支。
3. 海外头部模型政策+定价双重不确定性
Fable5开启周额度限制、GPT5.6延期、出口管制持续收紧,长期依赖闭源海外模型不仅贵,还存在服务中断、涨价风险。
三、GLM-5.2替代落地优势(适配研发AICoding场景)
1. 成本硬优势
同等编码/Agent长任务,直接把算力开支压缩至原先1/6,6人研发团队周5万预算可直接降到8千以内,现金流压力大幅缓解。
2. 百万上下文适配大型项目
原生1M超长上下文,无需频繁拆分会话,减少分段调试带来的重复Token消耗,同时规避长会话成本爆炸。
3. 国产无海外管制风险
不受美国AI出口、额度配额政策约束,不存在关停、审批延期问题,私有化/公有云双部署可选。
4. 代码赛道性能持平Opus
FrontierSWE长周期代码基准仅差1%,SWE类工程任务、Agent自主调试能力完全覆盖研发日常需求。
四、团队平滑切换落地步骤
1. 分层路由分流
- 日常编码、Agent自动化调试、批量脚本生成:全量切换GLM-5.2;
- 仅极复杂底层架构、超深度综合推理场景少量保留Opus做兜底。
2. 叠加Loop熔断管控
搭配Harness循环护栏:最大执行步数、重复动作拦截、单账号日Token上限,从架构杜绝无节制循环烧钱。
3. 缓存复用降额外消耗
启用KV缓存、固定Prompt缓存,项目规范、系统提示词只计费一次,削减30%以上重复输入Token。
4. Skill资产固化
把通用编码模板、调试工作流封装成复用Skill,不用每次任务重新全量推理,进一步压缩无效算力开销。
五、长期成本治理结论
纯依赖Opus做日常研发属于高成本不可持续方案;GLM-5.2在代码Agent场景形成「同等能力、1/6成本、政策稳定」的平替,是当下解决你们算力账单失控最直接可行的方案。
GLM5.2平替Opus AICoding成本管控 大模型Agent降本 研发算力预算优化 国产代码大模型 GLM5.2 Opus5.5 GPT5.2 GLM-5.2 erp测评 DLSS4.5 GPT-5.4