[LG]《Quantization Inflates Reasoning: Token Inflation as a Hidden Cost of Low-Bit Reasoning Models》X Lian, W Krichene, B Huang, M Tanaka… [University of Illinois Urbana-Champaign & Microsoft & Anyscale] (2026)
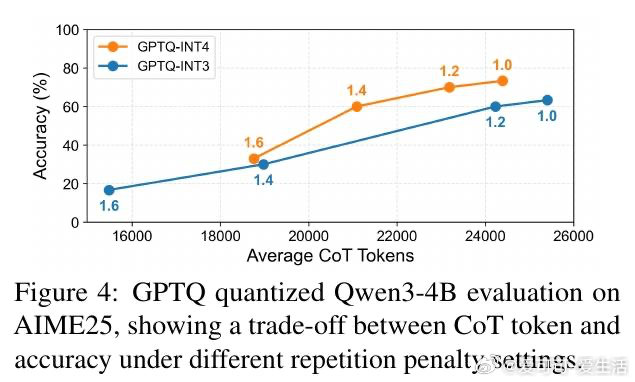
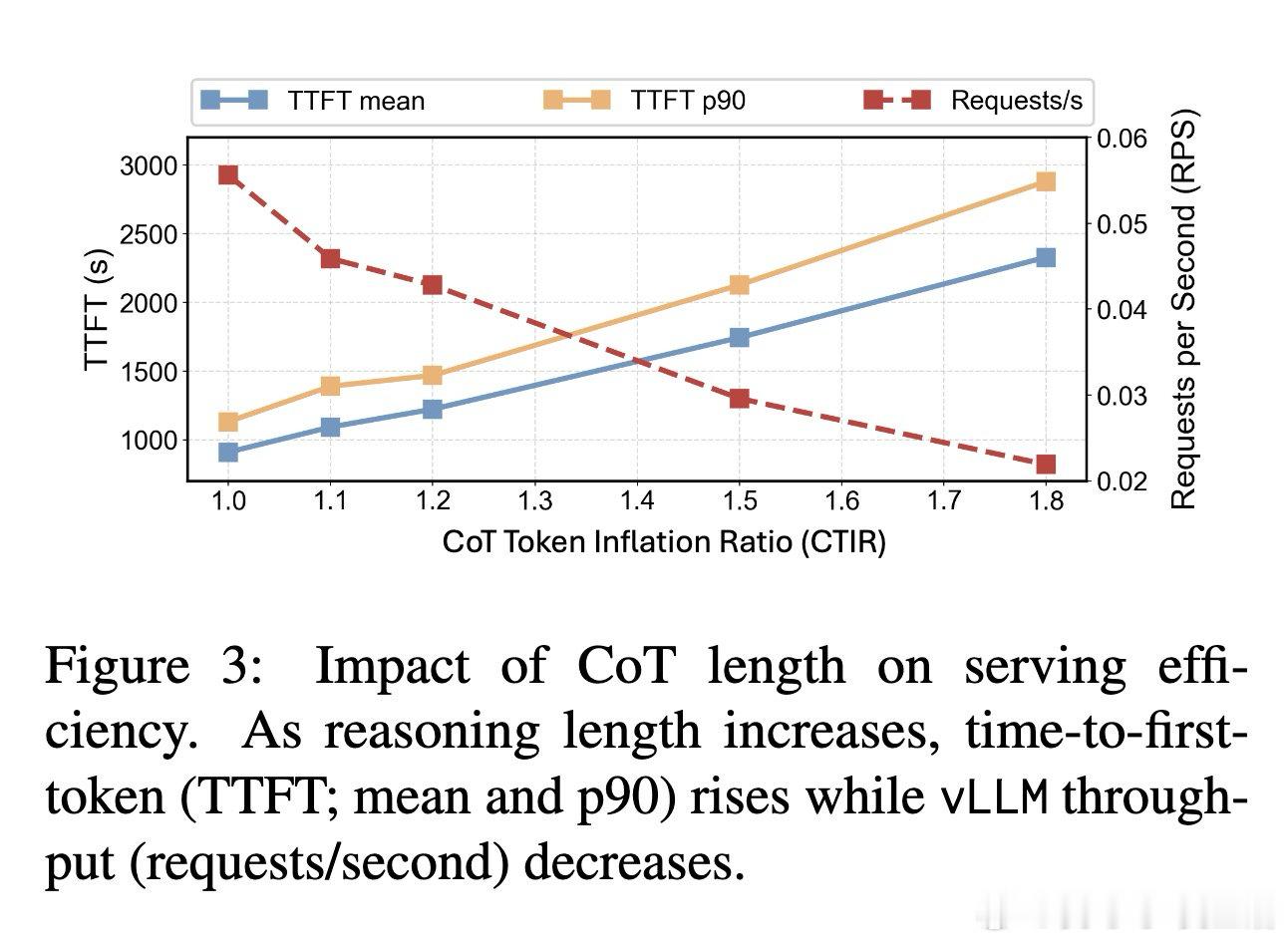
在推理模型部署领域,低比特量化(Quantization)被视为降低推理成本的标配方案。过去的方法受困于“准确率-延迟”的二维评估框架,本质原因是忽视了推理模型特有的“测试时计算”属性——即量化虽能提升单 Token 采样速度,却可能诱发模型生成更长的思维链(CoT),导致端到端成本不降反升。
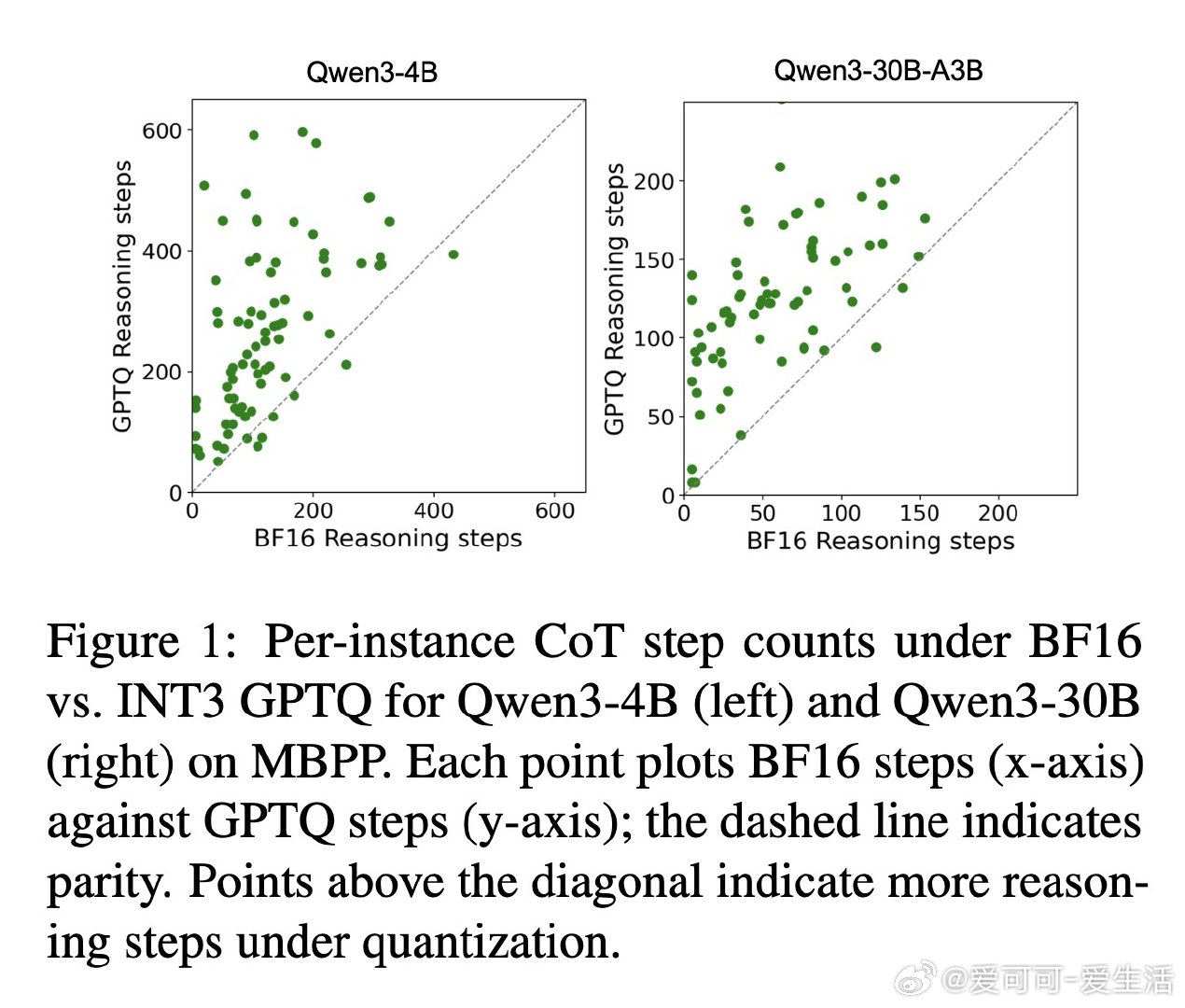
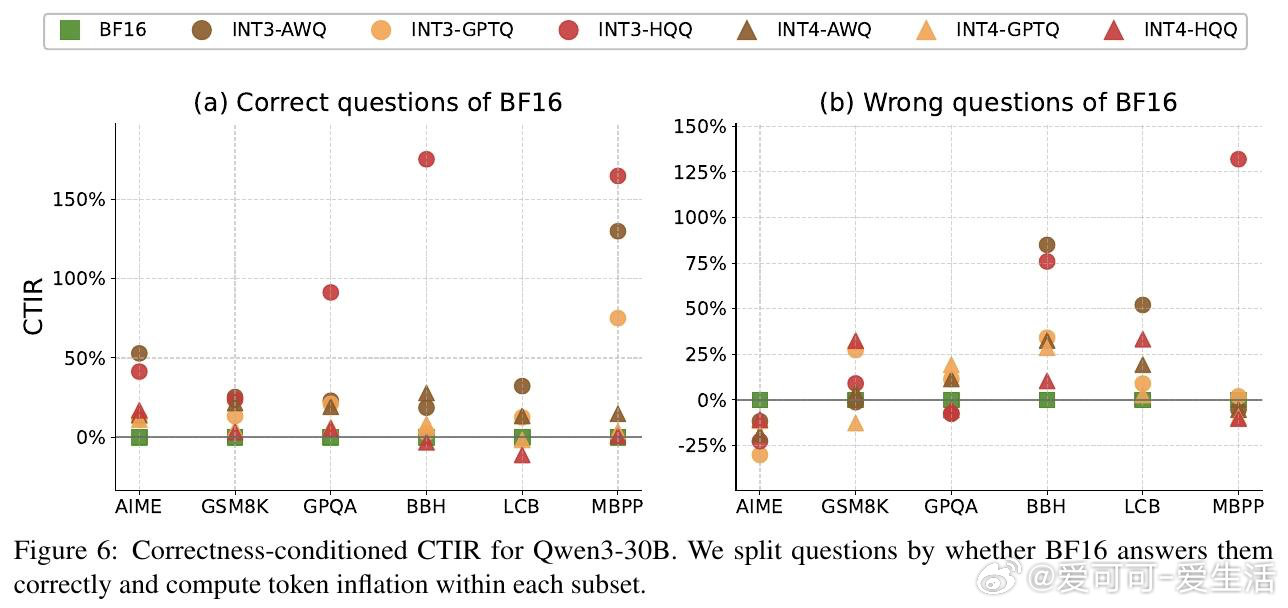
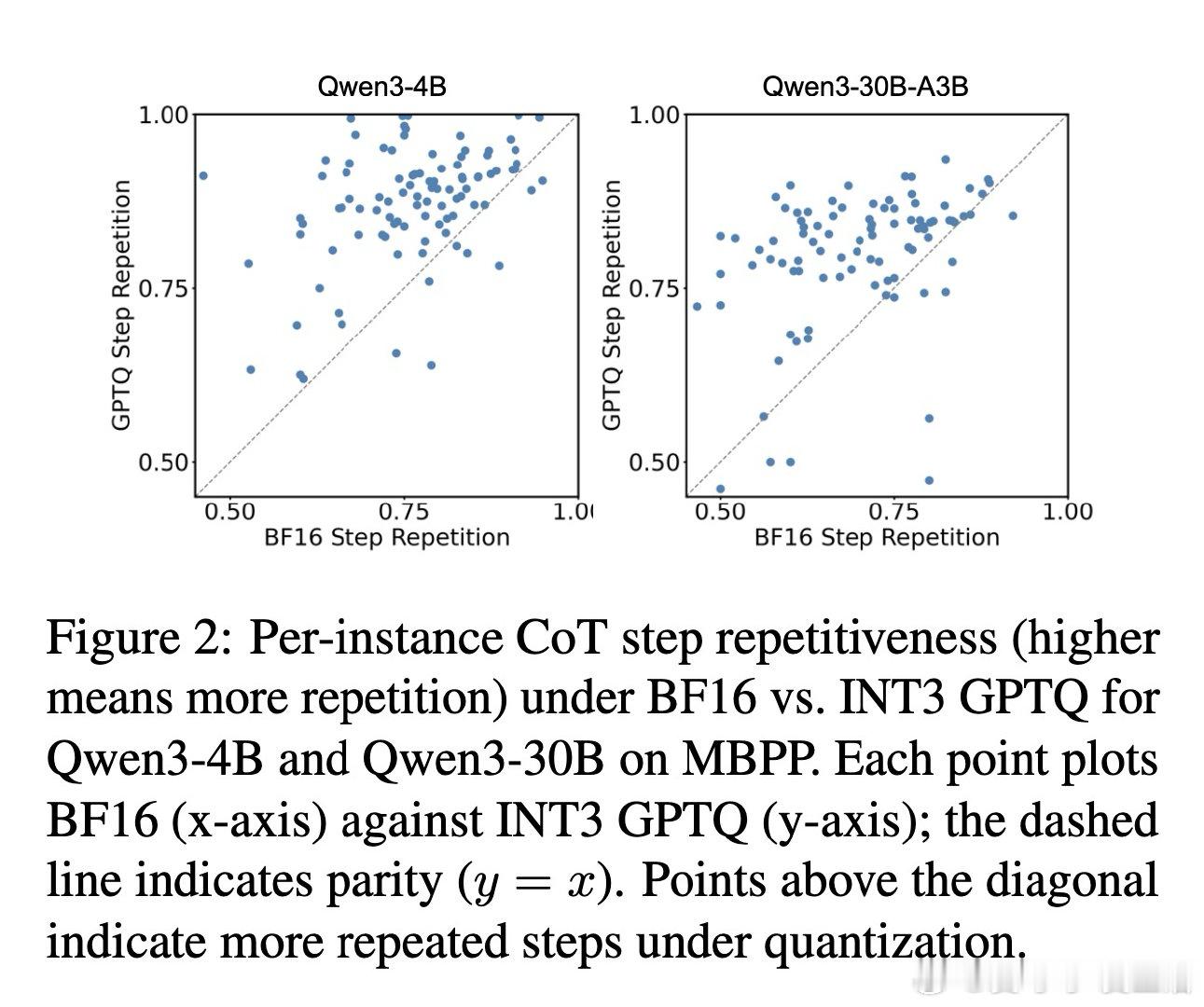
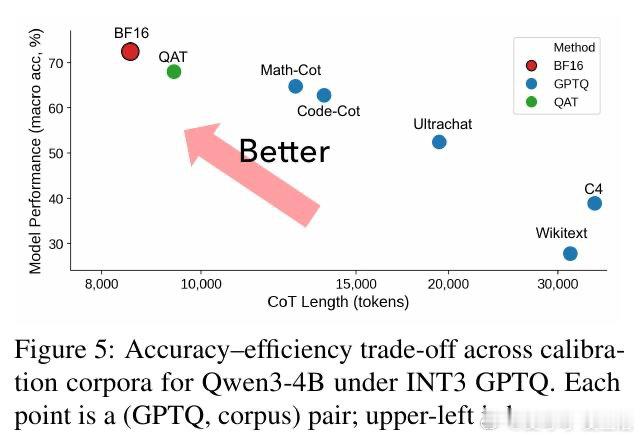
本文的核心洞见是:把量化过程看作对模型推理轨迹的“高频扰动”。由此,作者引入了“思维链 Token 膨胀率(CTIR)”这一关键指标,揭示了模型在量化后因“语义重复”和“过度验证”而产生的行为异化。实验证明,INT3/INT4 量化虽能维持准确率,但会导致推理步数显著增加,这种“认知跳跃”的受损直接抵消了底层算子的加速红利。
这项工作真正留下的遗产是重新定义了量化模型的效能边界,将“Token 长度”确立为推理模型评估的第三维度。它为后来者打开的新门是利用量化感知训练(QAT)和特定推理校准集来对齐推理轨迹,但尚未跨过的门槛是如何在极低比特(如 INT2)下彻底消除模型因不确定性增加而导致的“逻辑兜圈”现象。
arxiv.org/abs/2606.25519 机器学习 人工智能 论文 AI创造营