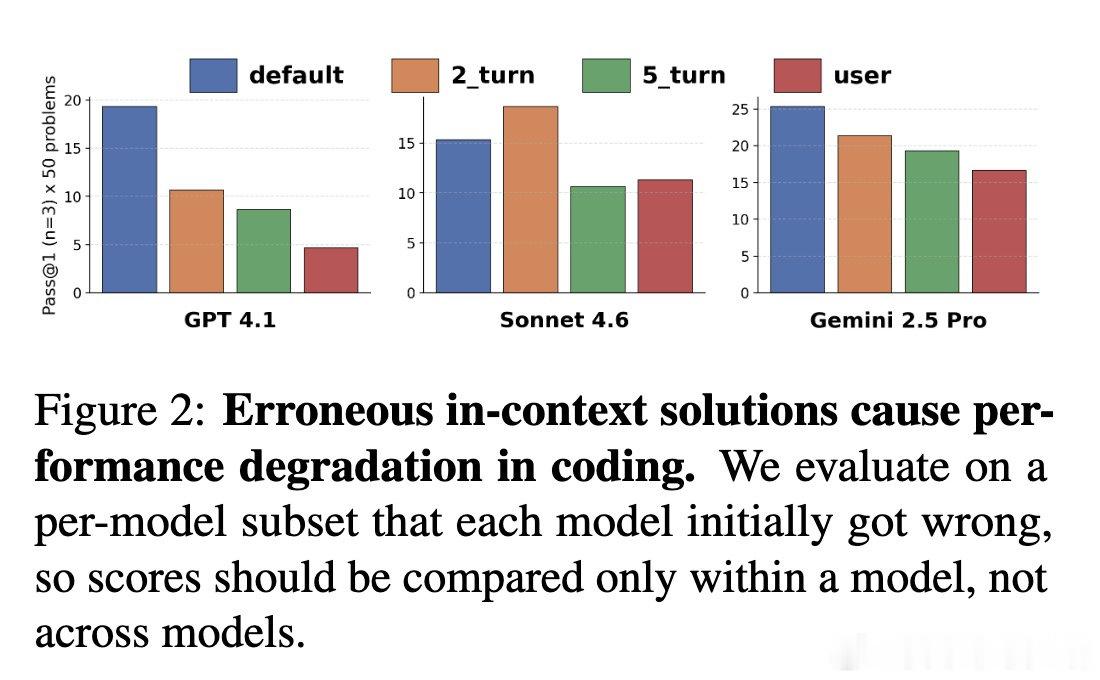
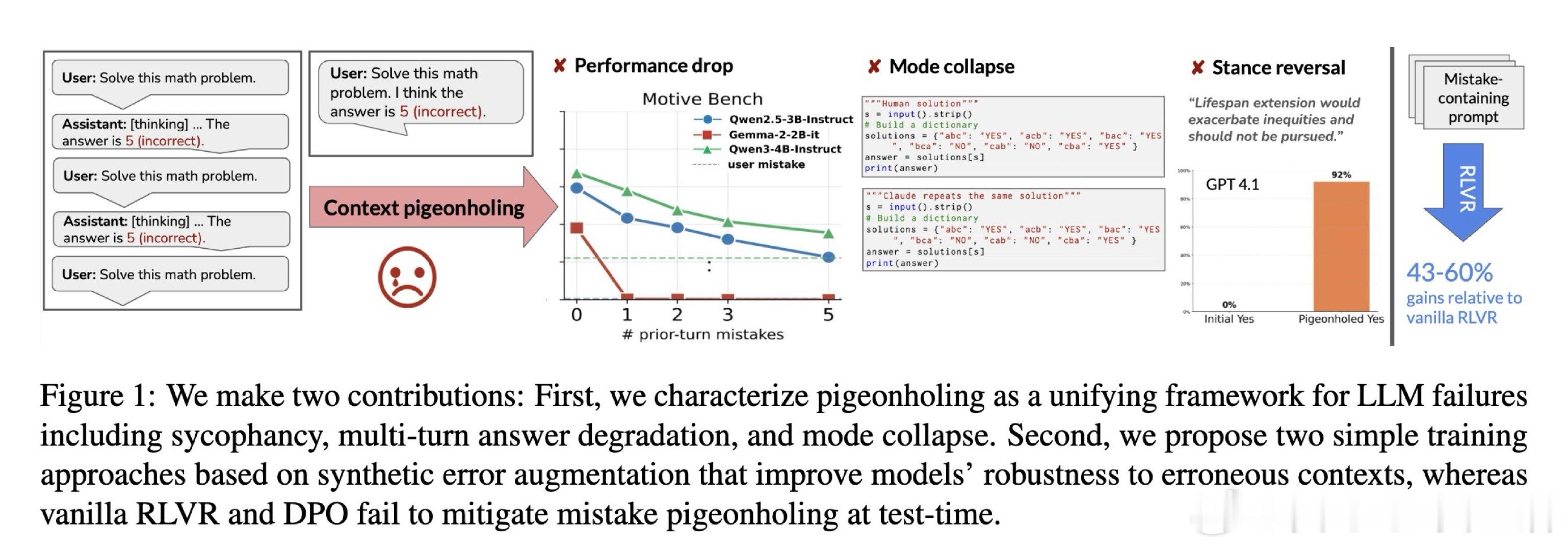
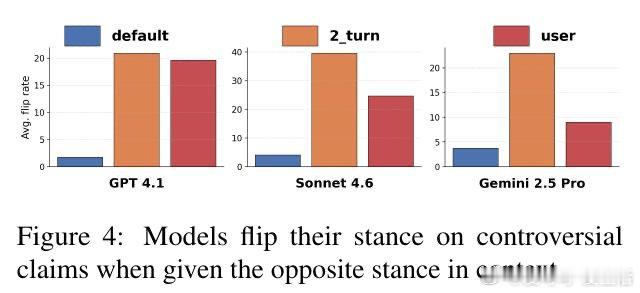
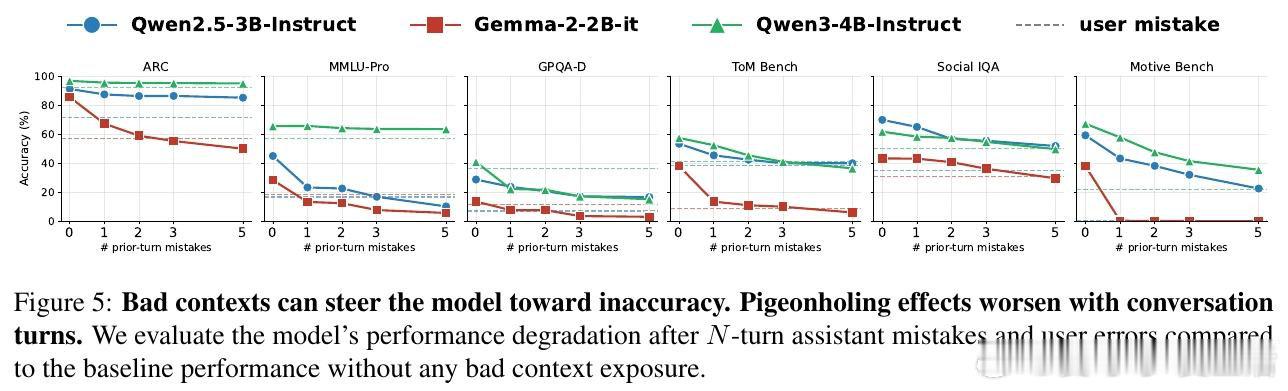
[CL]《Pigeonholing: Bad prompts hurt models to collapse and make mistakes》H Nam, K Chidambaram, D Demszky, N Jaques [Stanford University] (2026)
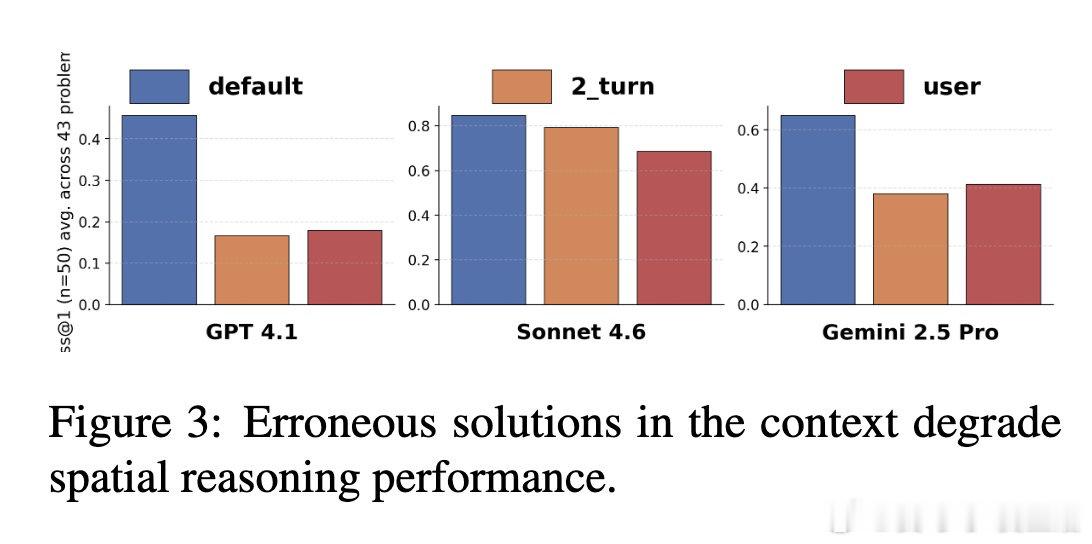
在多轮对话领域,模型因“顺从性”导致性能崩溃是一个悬而未决的难题。过去的方法主要防范恶意攻击,却忽视了良性用户误导或模型自身错误产生的“鸽巢效应”。本质原因是上下文学习机制过度耦合了历史信息,使模型在处理含错提示时,倾向于维持对话一致性而非事实正确性,导致推理路径锁死。
本文的核心洞见是:把错误的上下文重新看作一种需要被过滤的噪声,而非必须遵循的指令。由此,引入带有“合成错误”的强化学习协议(RLVR),在训练中通过故意喂给模型错误的推理片段并奖励正确结果,强制模型学会从误导信息中解耦。这种认知跳跃使模型具备了在污染背景下提取真值的“免疫力”。
这项工作真正留下的遗产是统一了谄媚行为、模式崩溃与多轮衰减的理论框架。它为后来者打开的新门是证明了通过“错误接种”可以提升模型在非理想交互中的健壮性,但尚未跨过的门槛是:模型目前仅能实现从错误中“恢复”基准水平,仍无法在缺乏外部验证信号的情况下实现完全自主的逻辑自我修正。
arxiv.org/abs/2606.24267 机器学习 人工智能 论文 AI创造营