中国AI模型在30个月内从美国的65%追至95%:10%的智能差距换来90%的成本节约——5万亿美元AI资本开支是远见还是豪赌?
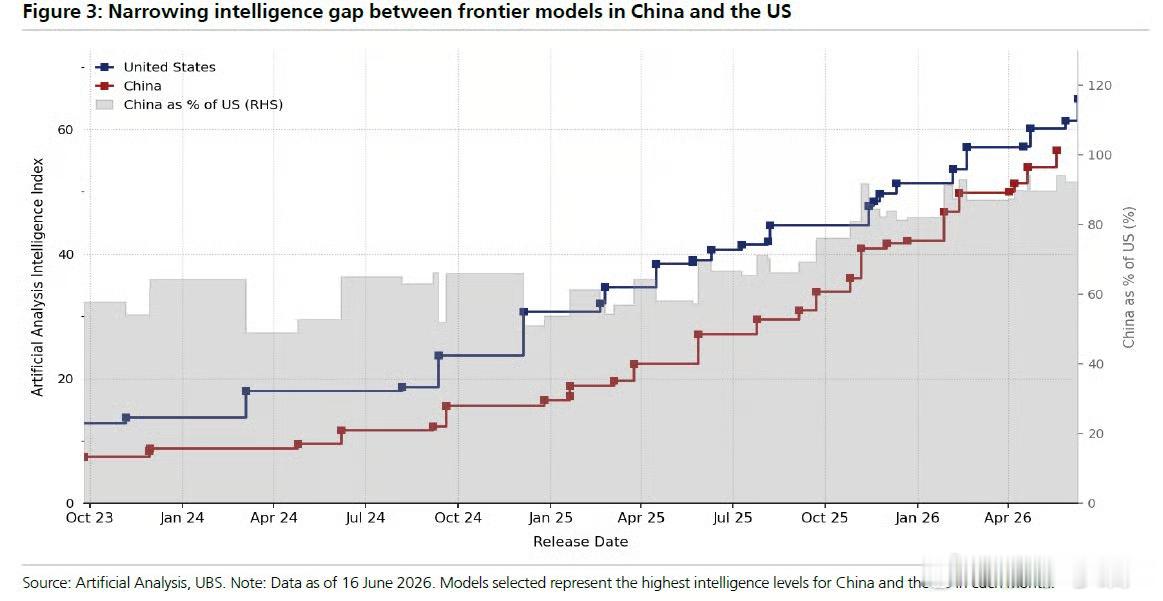
瑞银与Artificial Analysis的这张追赶曲线,记录了AI历史上最快速的技术收敛之一。2023年10月,中国最强模型的综合智能评分仅为美国的65%;到2026年6月,这一比率已升至95%甚至短暂触及100%——不到三年,差距从35个百分点压缩到不足5个百分点。
在综合能力差距仅剩10%的情况下,为什么运行成本的差距仍然高达90%(DeepSeek $100 vs Claude $6,000)?如果10%的能力差距无法覆盖90%的成本溢价,全球科技巨头过去两年宣布的逾5万亿美元AI基础设施资本开支——这些基于"顶尖算力不可或缺"逻辑构建的投资决策——是否正在经历系统性的逻辑动摇?
答案并不是非此即彼。高端模型的"最后10%"在医疗、法律、国防等关键任务领域价值远超成本;而在客服、文档、代码辅助等大众任务中,低成本路线已经"足够好"。更重要的是,Jevons悖论仍然有效:$100的推理成本会把AI带入此前负担不起AI的数十亿用户,总需求量的爆炸完全可能吸收全部的基础设施投资。但这一切都建立在一个未经验证的前提之上——AI需求的爆炸增长必须足够大,大到能将5万亿美元的沉没投资转化为有回报的生产性资产。这是当前AI牛市最核心的信念考验。