Claude Fable 5 值得看,核心不在“它现在排第一”,而在它代表了一种更成熟的前沿模型产品形态。
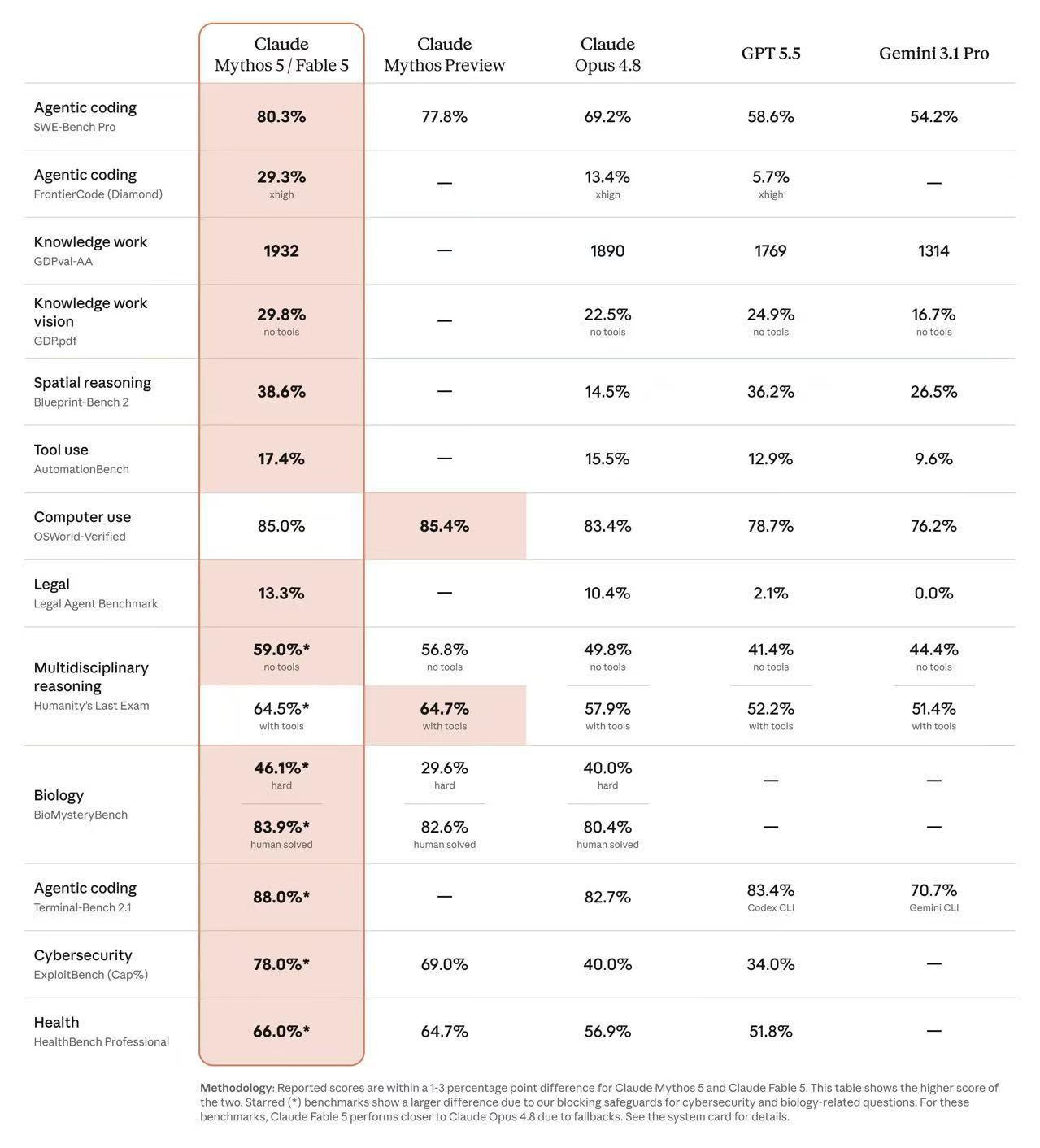
第一,它不是单纯追求 benchmark 分数,而是把“高能力”和“高风险隔离”一起产品化了。Artificial Analysis 在 2026-06-09 的文章里提到,Fable 5 是首个公开的 Mythos-class 模型,同时对网络安全、生物、化学、蒸馏等高风险请求加了额外护栏,并且会把部分请求路由到 Claude Opus 4.8 这类 fallback 模型处理。这意味着 Anthropic 在卖的不是一个“更猛的模型”,而是一套“主模型 + 安全回退”的运行架构。对企业来说,这比单次跑分更重要,因为真实生产环境里最怕的不是平均水平不够,而是少数高风险场景失控。
第二,它的领先指标更接近真实工作,而不是只会考试。Artificial Analysis 给出的重点不是传统 MMLU 这类静态知识分,而是 GDPval-AA 这种 agentic real-world knowledge work benchmark。文章里写到 Fable 5 以 1932 分拿到该基准第一。这类指标更接近“能不能完成复杂知识工作流”,而不是“能不能答对题”。如果你关心的是研究助理、分析助理、企业工作代理,而不是单轮聊天,Fable 5 的信号价值就比一般榜单第一更高。
第三,它展示了前沿模型竞争的下一个阶段:从“参数/能力竞赛”转向“系统设计竞赛”。过去大家看谁更强,主要看单模型输出;Fable 5 说明,下一阶段更重要的是:
什么时候启用高强推理
什么时候触发安全降级
什么时候切换 fallback
如何在能力、延迟、成本、合规之间做路由
这会直接影响未来的企业选型。很多团队以后选的未必是“最强单模型”,而是“最稳的模型系统”。
第四,它解释了为什么 Anthropic 在 Arena 上持续强势。arena.ai/leaderboard 当前可见,文本综合前列大多还是 Anthropic 的 Opus/Thinking 系列,说明他们强项仍然是复杂推理、长任务、知识工作和高可靠输出。Fable 5 并不是孤立的一次夺冠,而是沿着 Anthropic 一贯优势继续往“可部署”方向推进,这比一次榜单波动更值得重视。