晚上9点,我对着电脑陷入了沉思。
事情是这样的,前两天朋友发给我一段 30 分钟的英文访谈,说"帮我整理一下文字版呗"。你们懂的,这种请求我向来是拒绝的——且不说听力好不好,单是听写 30 分钟就得耗掉半天时间。但这次我学乖了,直接祭出了大杀器:Whisper。
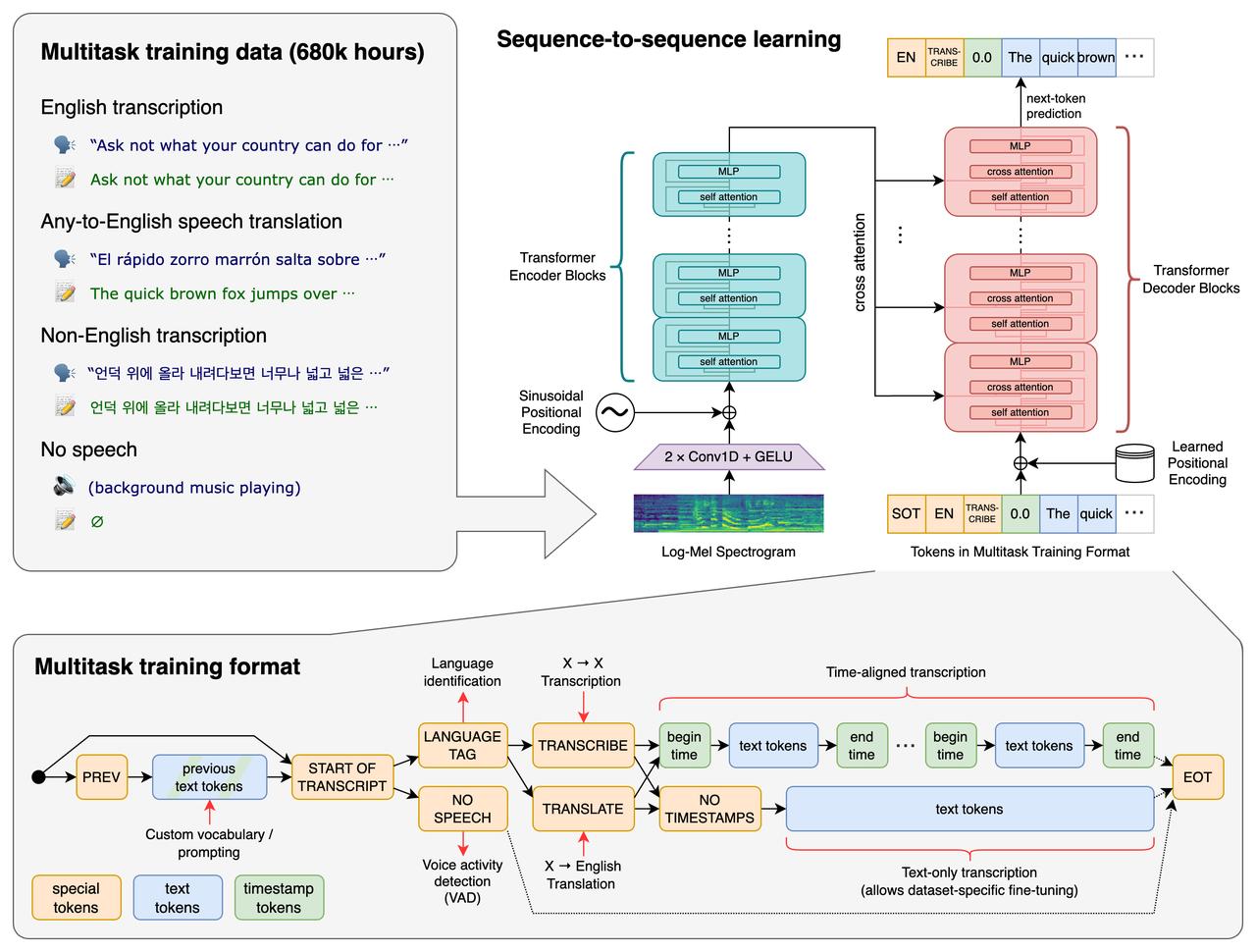
你们可能没听过这个名字,但做语音识别的基本都知道。OpenAI 2022 年开源的模型,支持 98 种语言,训练数据高达 68 万小时。最关键的是——免费开源,MIT 许可证,商用非商用随便用。我寻思着,这不妥妥的"白嫖"天花板吗?
实测过程这么说吧,我直接把音频拖进去,等了大概 2 分钟——出来了。全程无操作,连字幕文件都给我生成好了。我对照了一下,准确率大概在 95% 以上,有些专业术语居然也给我识别出来了。
讲道理,Whisper 这波属实是"降维打击"。以前做语音识别,要么花钱买讯飞、百度的 API,要么自己训练模型——前者要钱,后者要命。现在倒好,OpenAI 直接开源给你用,效果还贼能打。这让那些"套壳"做语音转写的厂商怎么活?
不过我也要说句公道话,Whisper 也不是完美的。本地部署对硬件要求不低,实时性也一般,真要做直播字幕还得另想办法,伯衡君我的 M1 电脑 8G 内存,只能运行 Medium 尺寸的模型。但对于我们这种"能不动手就不动手"的懒人来说,简直就是神器。
基于 OpenAI Whisper 的开箱即用的服务也不少,比如:
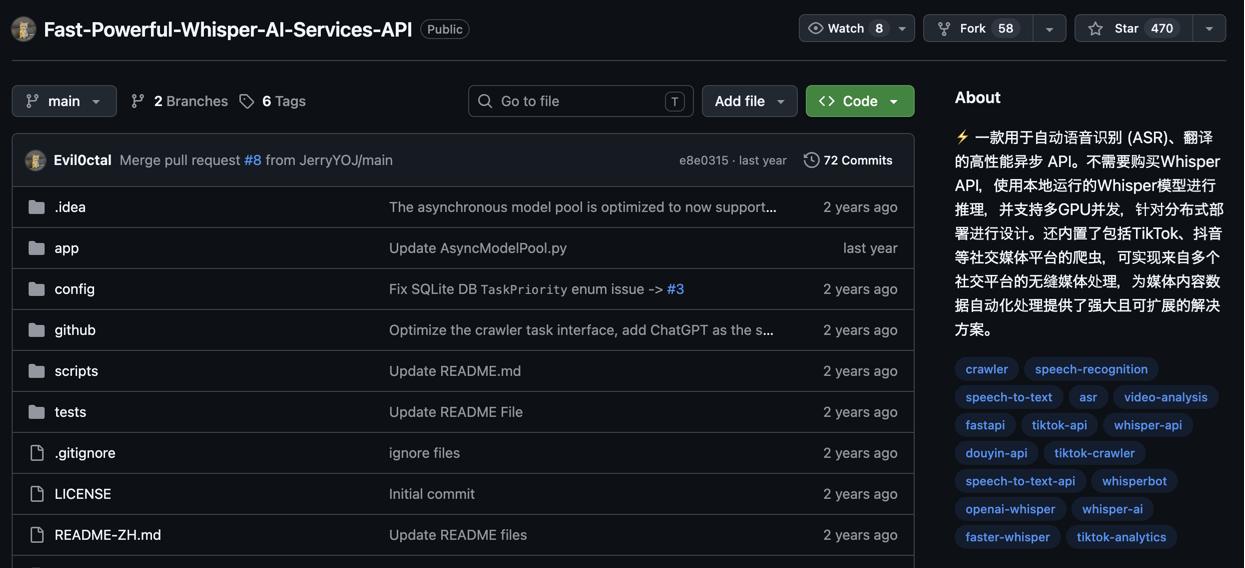
1. Fast-Powerful-Whisper-AI-Services-API
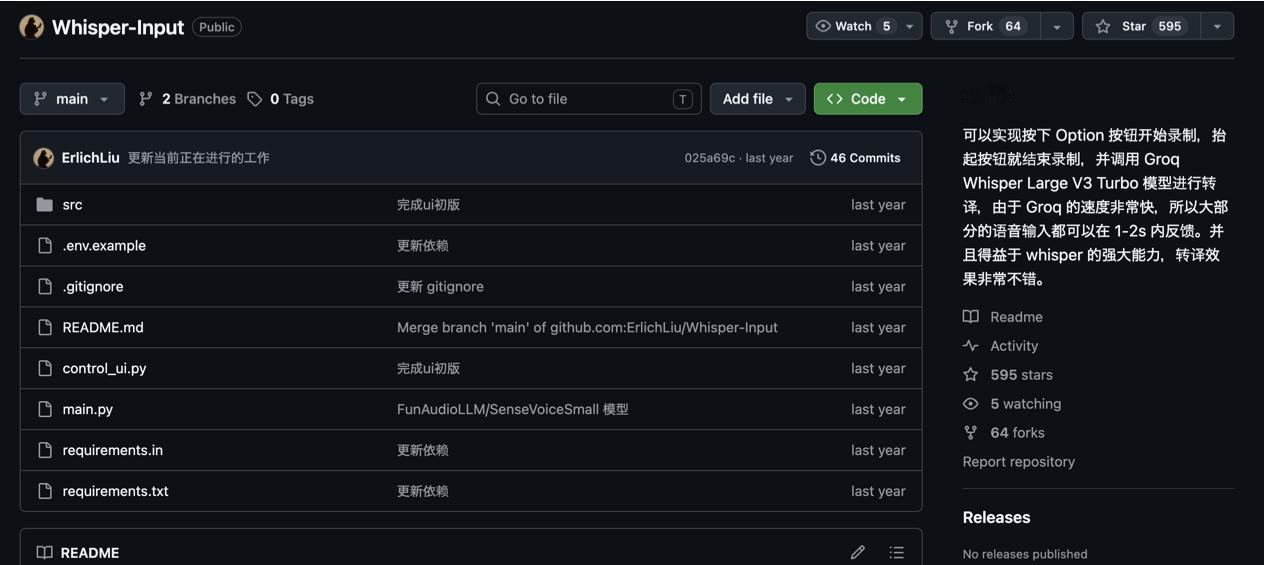
2. Whisper-Input
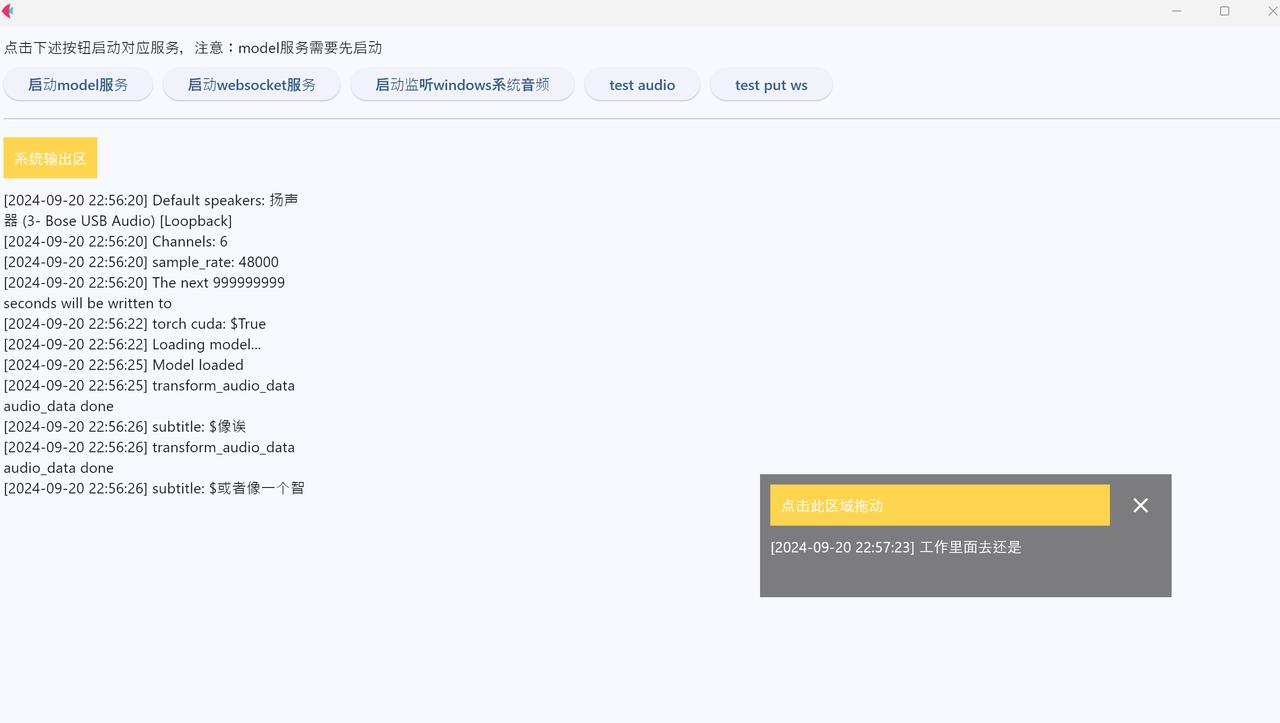
3. whisper-win-gui
你们平时有啥转录需求?评论区说说,看能不能帮上忙。