我认为并不矛盾,反而是很能说明问题。他们俩榜测的我认为并不是一回事。 SWE-bench Pro 测的是"在真实代码库里解决 issue 级别的任务",而Opus 4.8 显然是拿 69.2 对 GPT-5.5 的 58.6; 而 Terminal-Bench 2.1 测的是纯命令行的 agent 循环(pure command-line agent loops),GPT-5.5 以 78.2 对 74.6 是领先的。
2. 新功能允许模型调度数百“子智能体”并行处理如“Bun重写”这样的大型工程。
我的判断:架构思路不算是全新,但把它"产品化"是有深远意义的”,Bun 要单独看。
"开几个 agent 同时跑"会把长任务拆成子任务,让子智能体从不同角度并行,然后另一批 agent 专门去反驳(refute)这些结论,反复迭代直到答案收敛、验证通过后再合并。运行时也存在硬限制:最多 16 并发、单次最多 1000 agent;并且编排脚本本身是不能碰文件系统和 shell,只有 agent 能读写执行;进度会存盘,中断后能从断点续跑。真正的设计亮点是那个对抗性验证和断点续跑,相当于是把"多 agent 协作"从研究变成了长任务在工程上的敢于托付。 但我认为Bun 这个案例应该冷静看。宣传说Bun 的作者 Jarred Sumner 用它把 Bun 从 Zig 重写成 Rust,75 万行 Rust、99.8% 测试通过、从首次提交到合并 11 天。听着震撼,可有两个 Anthropic 自己也承认的硬caveat:第一,这个重写当时还没进生产环境;第二,dynamic workflows 比普通 Claude Code 会话更烧 token。一个"测试通过但还没上生产"的迁移,和"真的在跑生产流量"之间隔着的是一段很短但有很长的路。
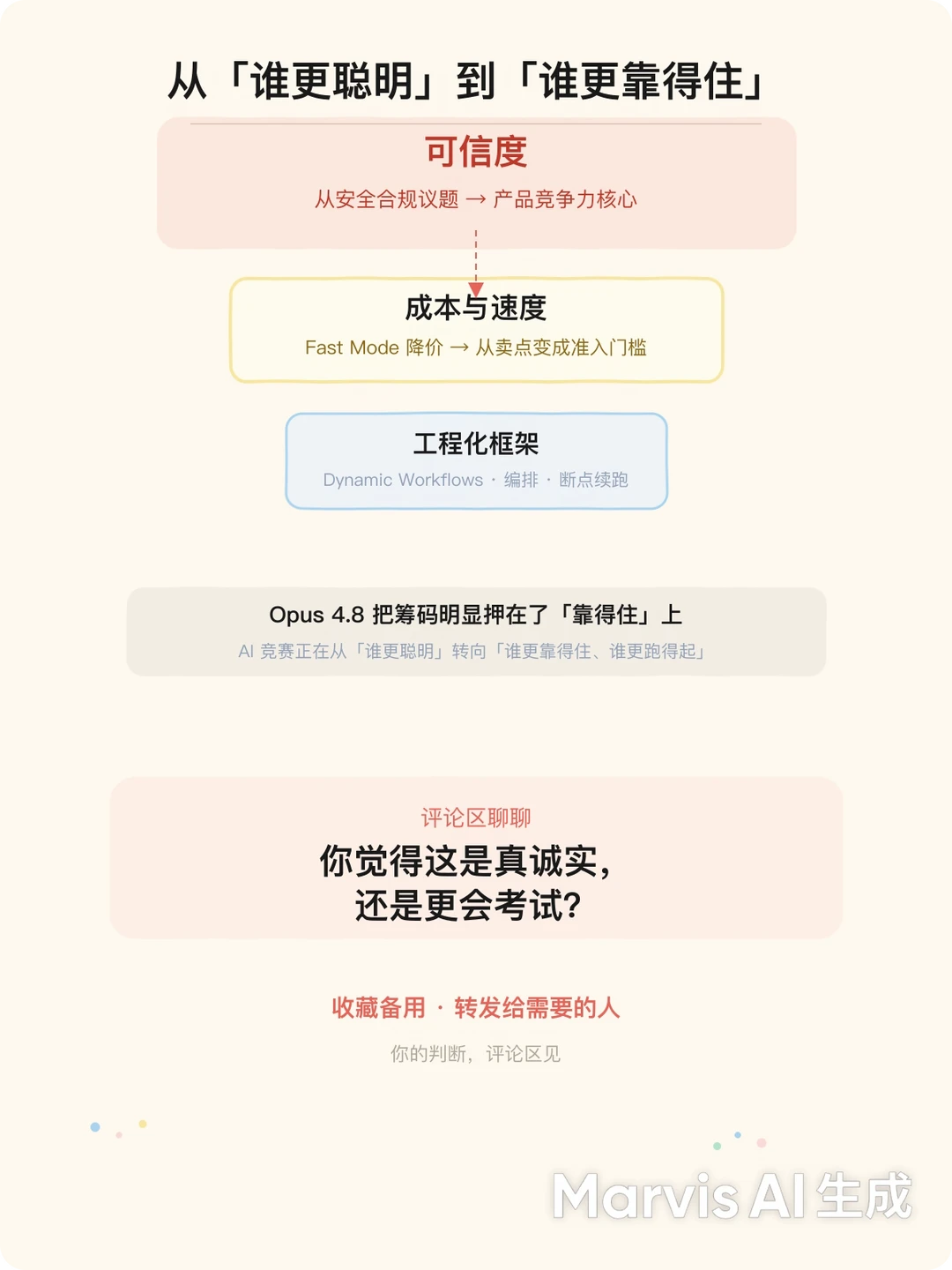
所以,无论是Claude,还是GPT或者Codex,AI工具之间的竞赛正在从"谁更聪明"转向"谁更靠得住、谁更跑得起"——而 Opus 4.8 这次把筹码明显押在了后者上。