【深度解析Mythos安全模型:可自主搭建攻击链还能编写PoC】
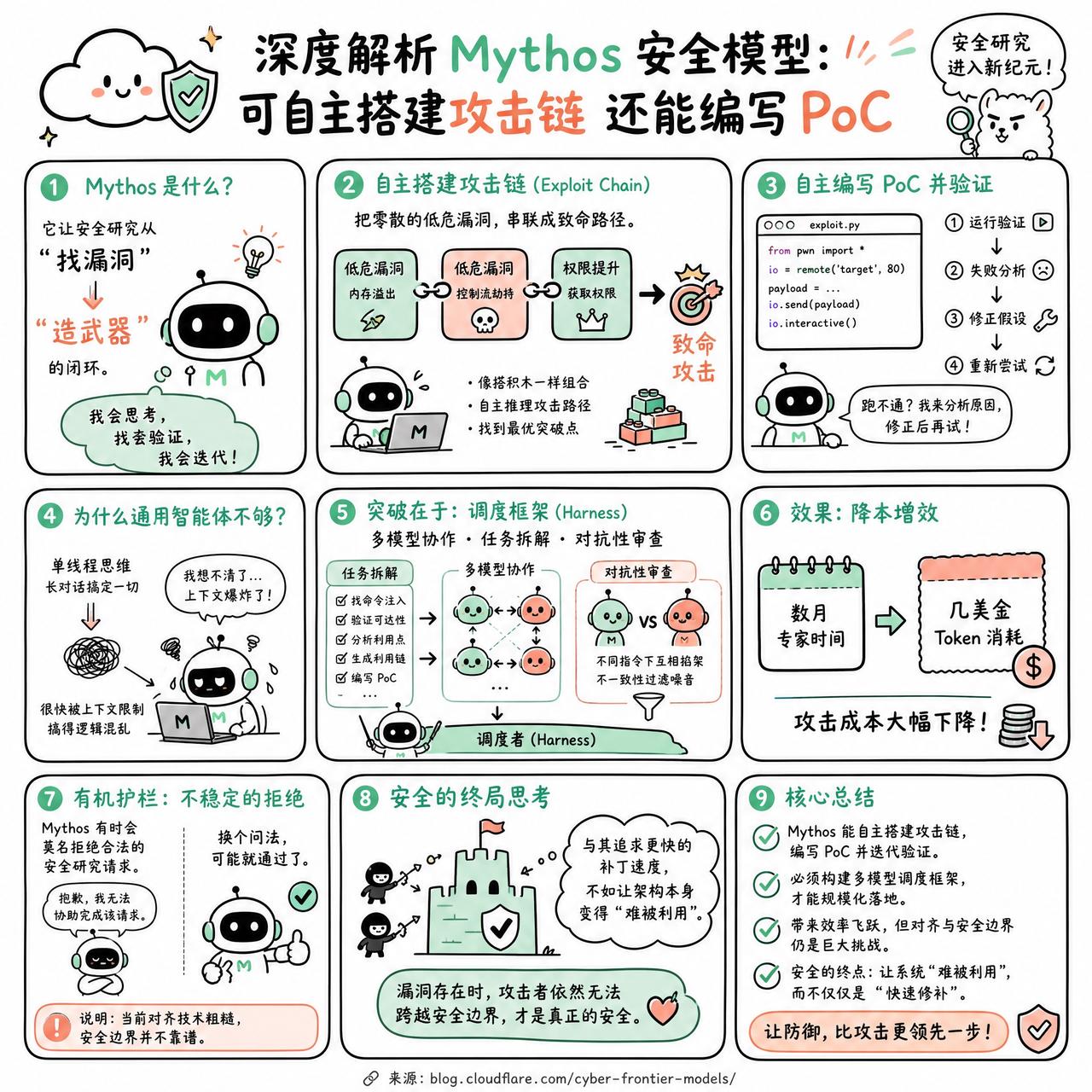
快速阅读:Cloudflare 通过测试 Anthropic 的安全专用模型 Mythos,发现其核心能力在于将零散的低危漏洞“串联”成完整的攻击链,并能自主编写 PoC 进行验证。单纯依靠通用编程智能体无法实现高覆盖率,必须构建一套由多个模型协作、任务拆解并进行对抗性审查的“调度框架(Harness)”才能真正落地。
Mythos Preview 的出现,让安全研究从“找漏洞”变成了“造武器”。
以前的通用模型像是个博学但缺乏耐心的实习生,能指着一段代码说“这里可能有问题”,但话说到一半就停了。Mythos 不一样,它能完成从发现漏洞到构造攻击链(Exploit chain)的闭环。它会把几个看似无关紧要的低危漏洞——比如一个内存溢出接一个控制流劫持——像搭积木一样拼成一个致命的攻击路径。更聪明的是,它会自己写代码去验证猜想,如果跑不通,它会像资深研究员一样分析失败原因,然后修正假设重新尝试。这种自主迭代的能力,让它不再只是个扫描器,而是一个能思考的攻击者。
但要把这种能力规模化,直接把模型丢进仓库里是行不通的。通用智能体通常是单线程思维,试图通过一个长对话搞定一切,结果很快就会被上下文窗口的限制搞得逻辑混乱。
真正的突破在于构建一套“调度框架”。Cloudflare 的做法很有意思:不再试图让一个模型做所有事,而是把任务拆得极细。比如,让一个模型专门找命令注入,另一个模型专门负责验证漏洞的可达性。甚至,他们引入了“对抗性审查”——让两个模型在不同指令下互相掐架,这种不一致性反而能过滤掉大量噪音。
有网友提到,这种能力是把攻击成本从“数月的专家时间”降到了“几美金的 Token 消耗”。
不过,这种进步也带来了一种奇怪的现象:模型表现出了某种“有机护栏”。即便是在受控的研究环境下,Mythos 有时也会莫名其妙地拒绝执行合法的安全研究请求。这种拒绝并不稳定,换个问法可能就通过了。这说明目前的对齐技术还很粗糙,安全边界并不靠谱。
与其追求更快的补丁速度,不如去思考如何让架构本身变得“难被利用”。如果一个漏洞存在时,攻击者依然无法通过它跨越安全边界,那么补丁的速度也就没那么令人焦虑了。
blog.cloudflare.com/cyber-frontier-models/