[LG]《AstraFlow: Dataflow-Oriented Reinforcement Learning for Agentic LLMs》H Zheng, Y Di, J Wang, S Jin… [CMU] (2026)
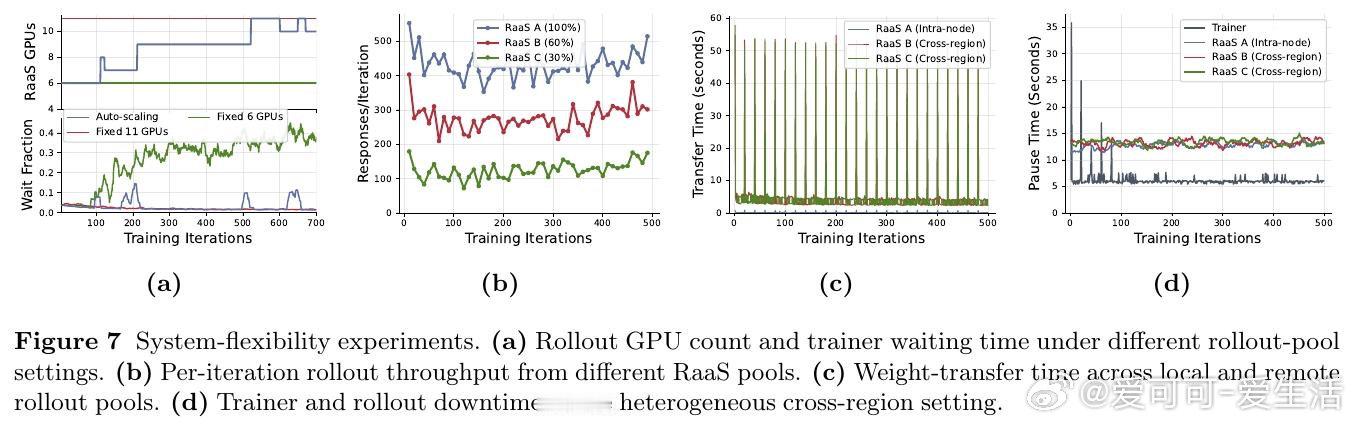
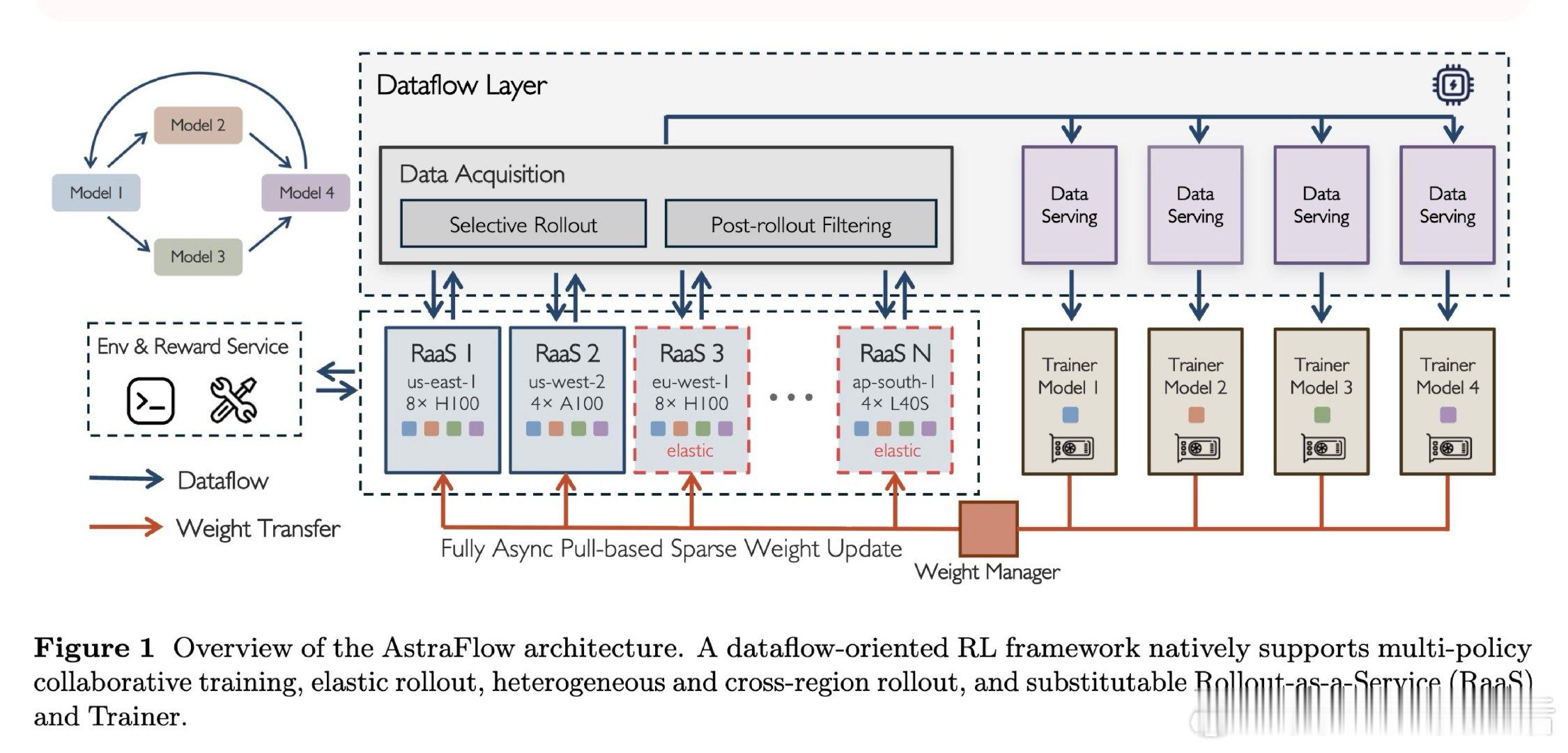
在智能体LLM强化学习领域,训练成本被多角色协作、弹性算力和跨区部署拖垮。过去系统受困于训练器居中控制,本质原因是 rollout、数据流、权重同步耦合成一条硬管线。
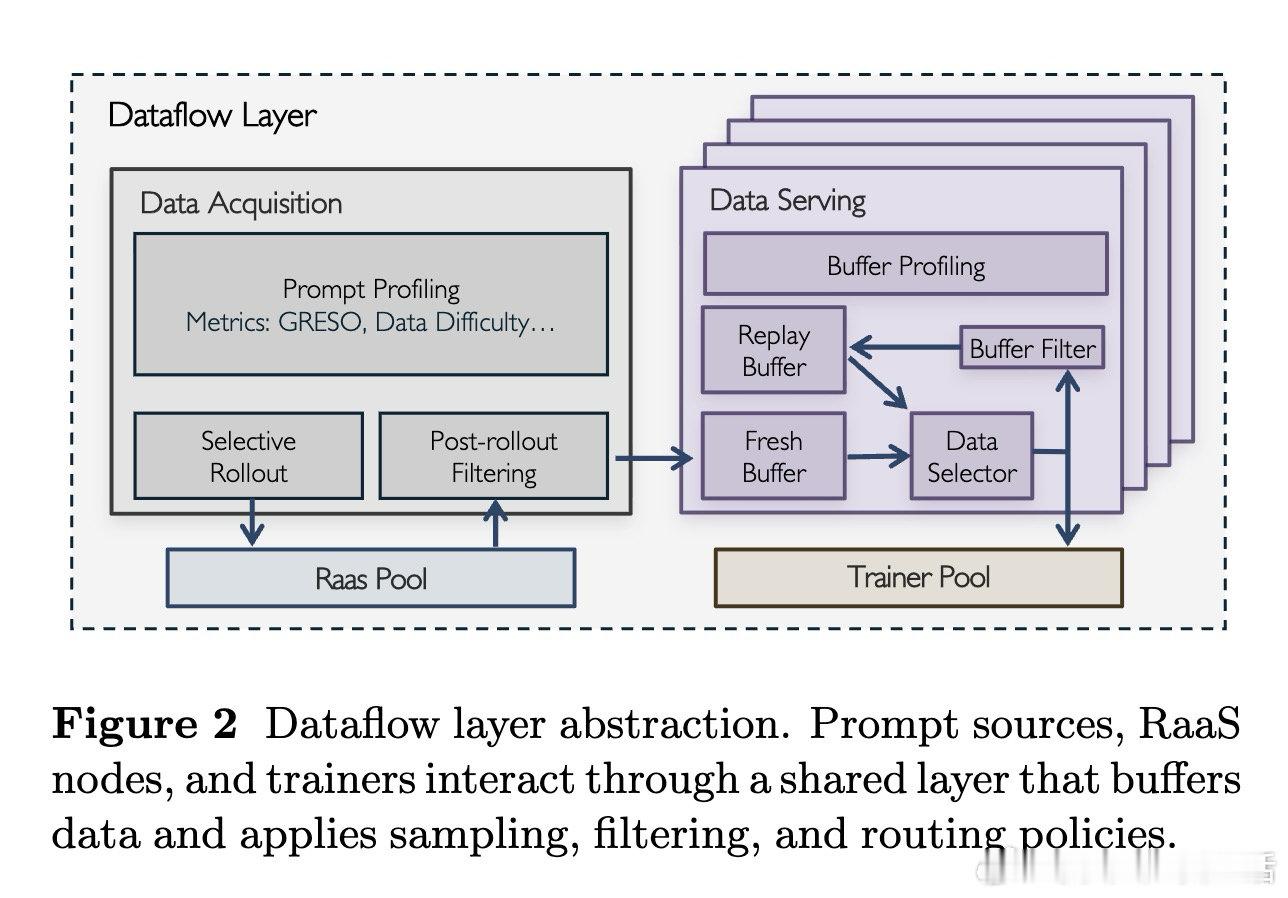
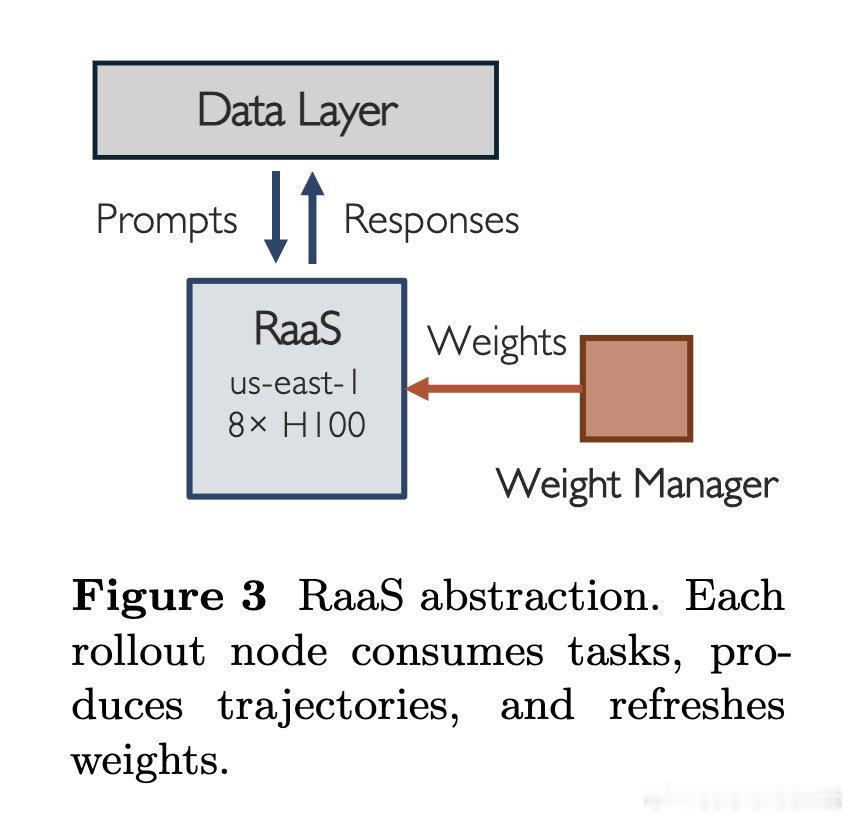
本文的核心洞见是:把RL训练重新看作数据流驱动的组件协作。由此,RaaS、数据层、训练器各自自治,只通过轨迹、批次与权重接口交换。
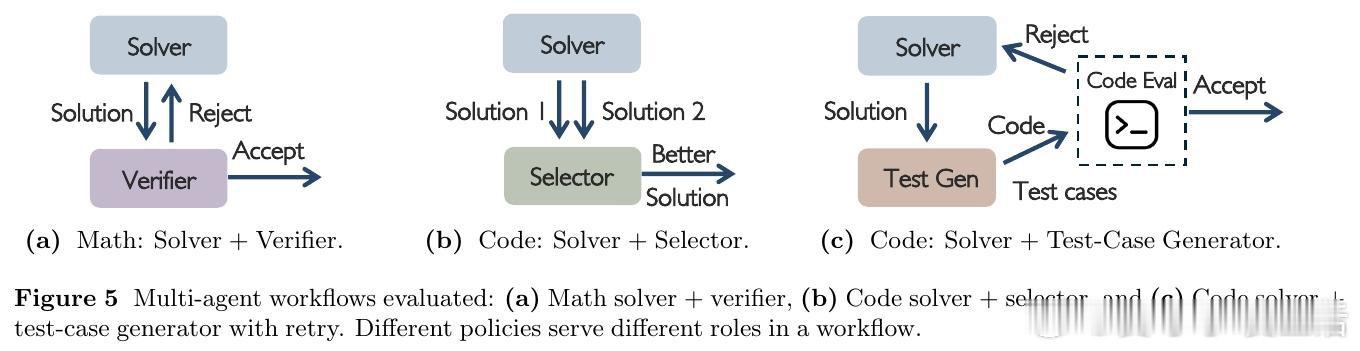
这项工作真正留下的遗产是让多策略智能体RL从专门改系统变成组合组件。它打开的新门是异构跨区与数据算法即插即用,但尚未跨过的门槛是真实长程智能体场景仍未充分覆盖。
arxiv.org/abs/2605.15565 机器学习 人工智能 论文 AI创造营