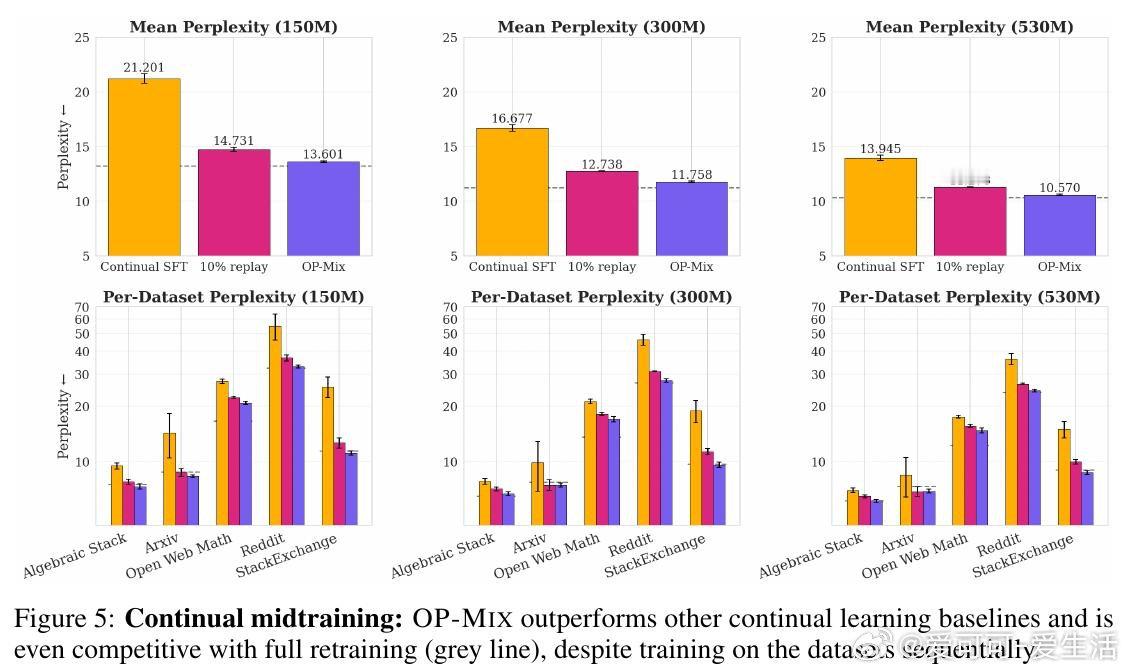
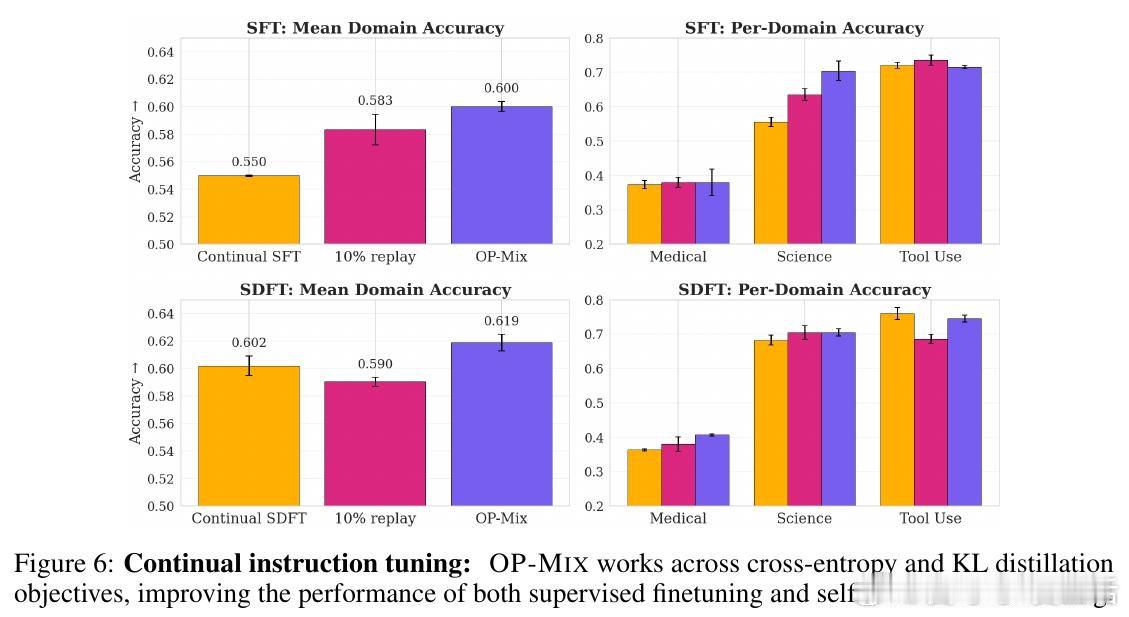
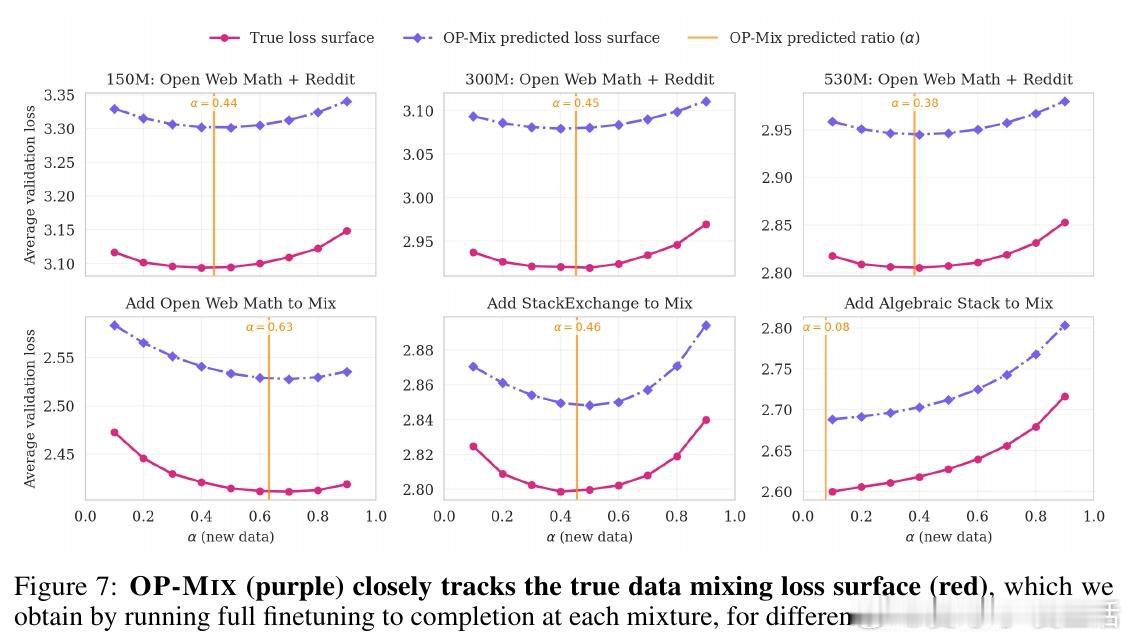
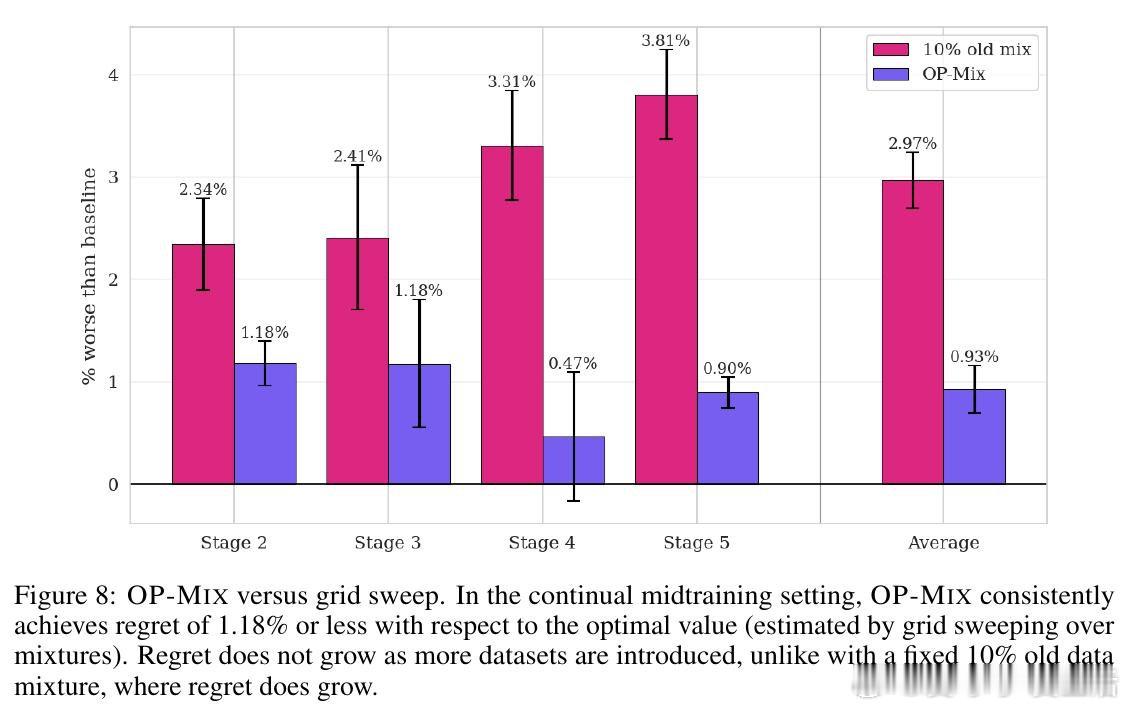
[CL]《Always Learning, Always Mixing: Efficient and Simple Data Mixing All The Time》M Y. Hu, A Gandhi, K Cho, T Linzen… [New York University & CMU] (2026)
在语言模型训练领域,数据配比贯穿预训练、持续训练与指令微调。过去方法受困于阶段专用代理模型,本质原因是数据域会不断变化,旧代理很快脱离当前模型。
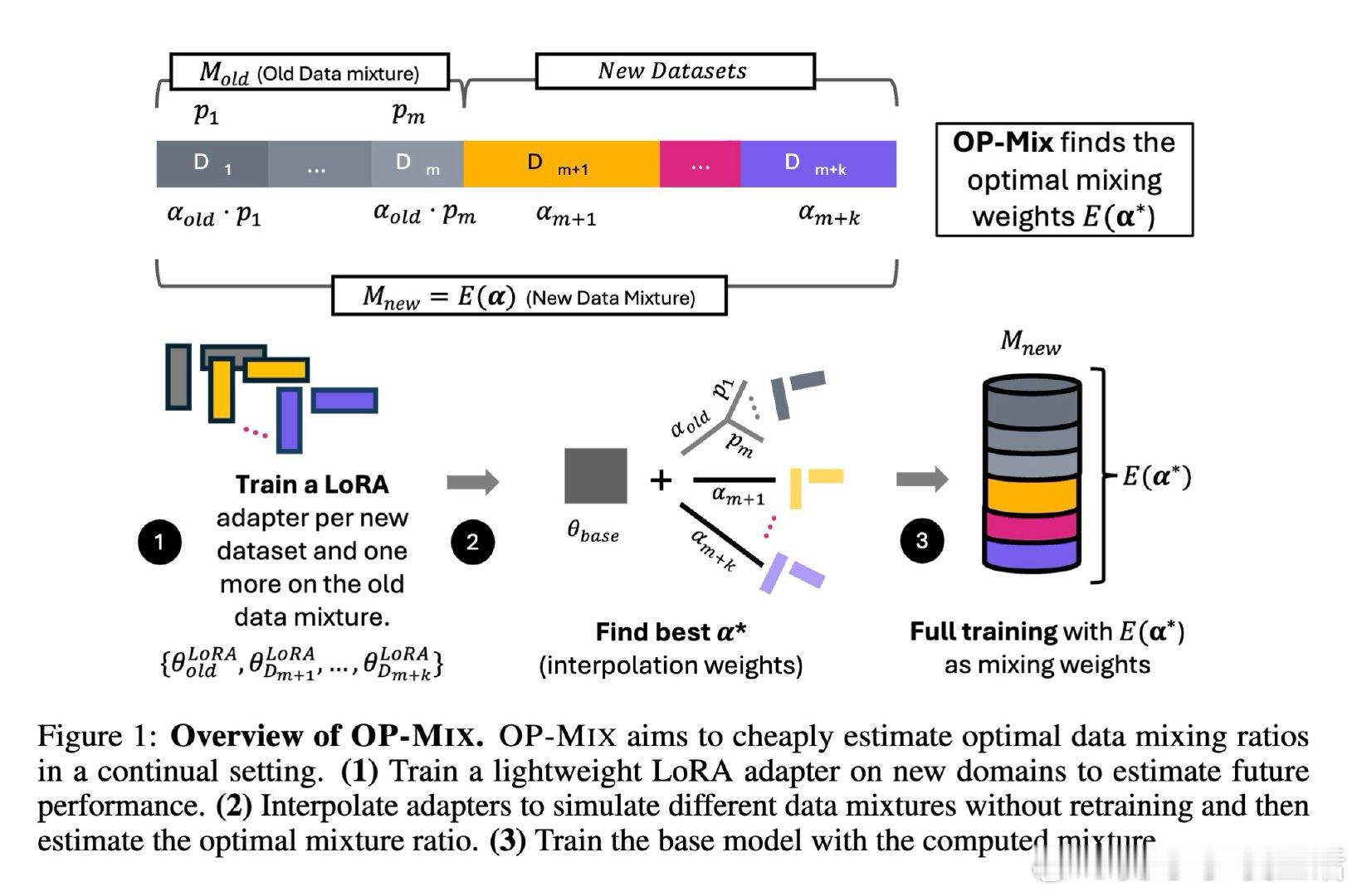
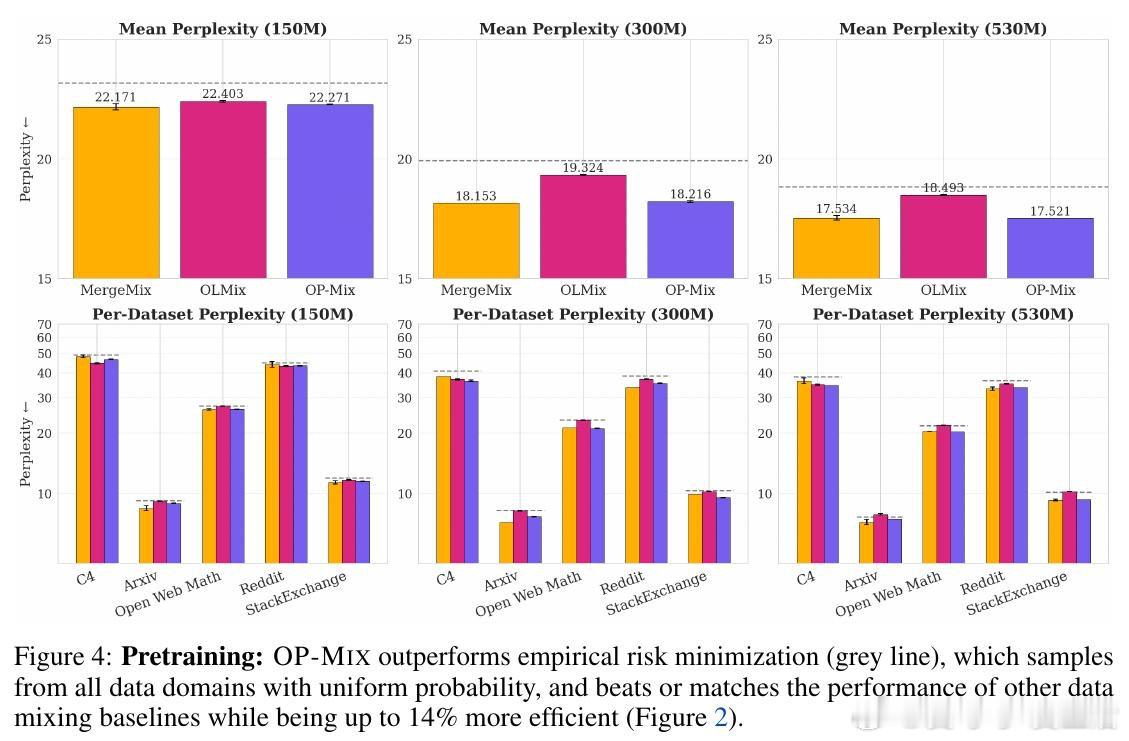
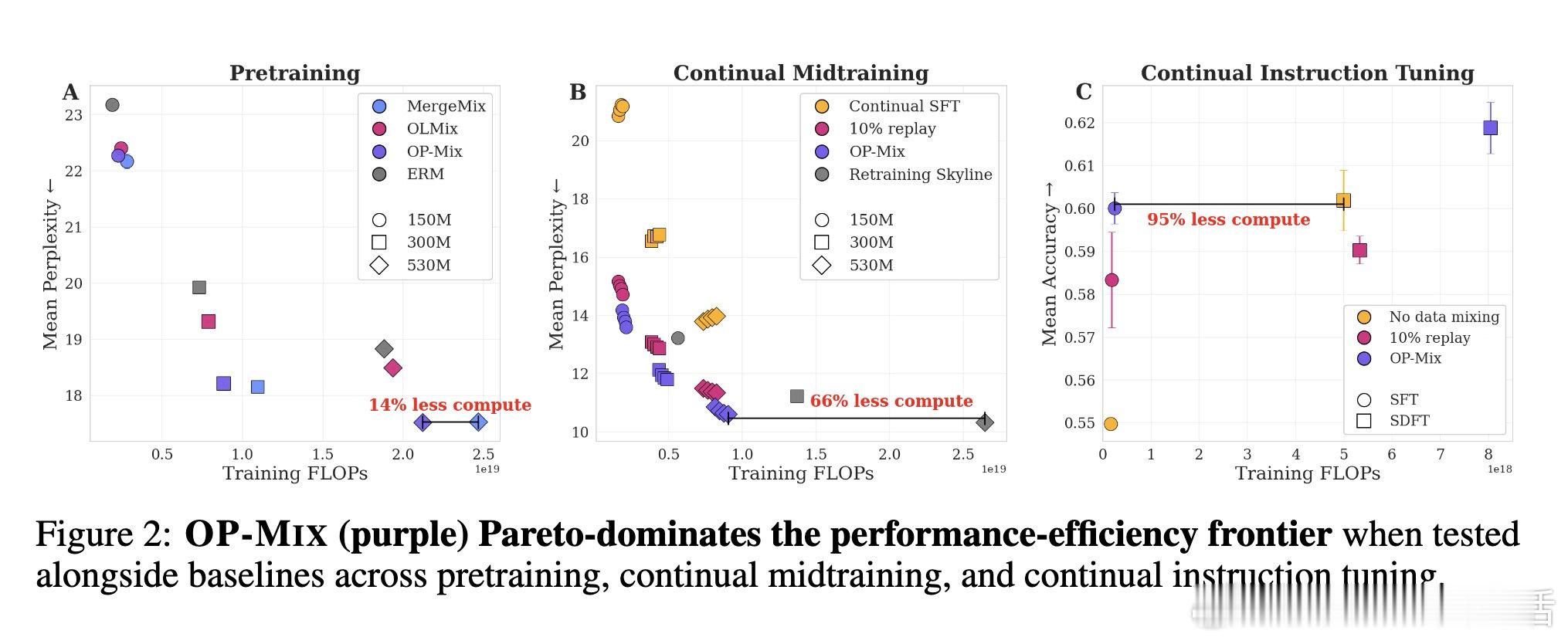
本文的核心洞见是:把数据混合重新看作在线决策。由此,在当前模型上为每个新数据域训练LoRA,并通过LoRA插值低成本模拟候选配比。
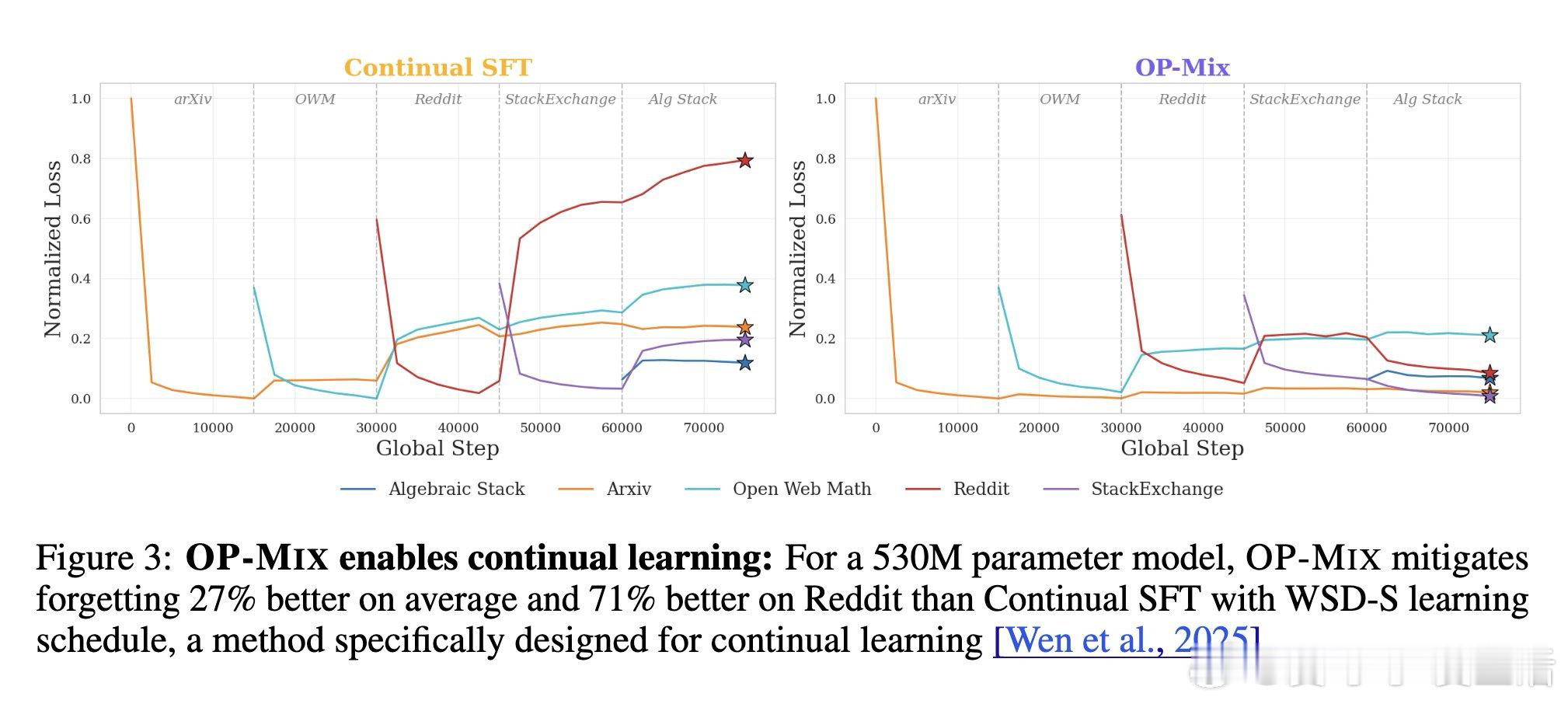
这项工作真正留下的遗产是把分阶段调数据变成持续可重复的轻量操作。它为后来者打开的新门是统一训练生命周期,但尚未跨过的门槛是百亿级模型与大量数据域仍未验证。
arxiv.org/abs/2605.15220 机器学习 人工智能 论文 AI创造营