【大模型能力升级,Agent编排架构该告别过度设计了】
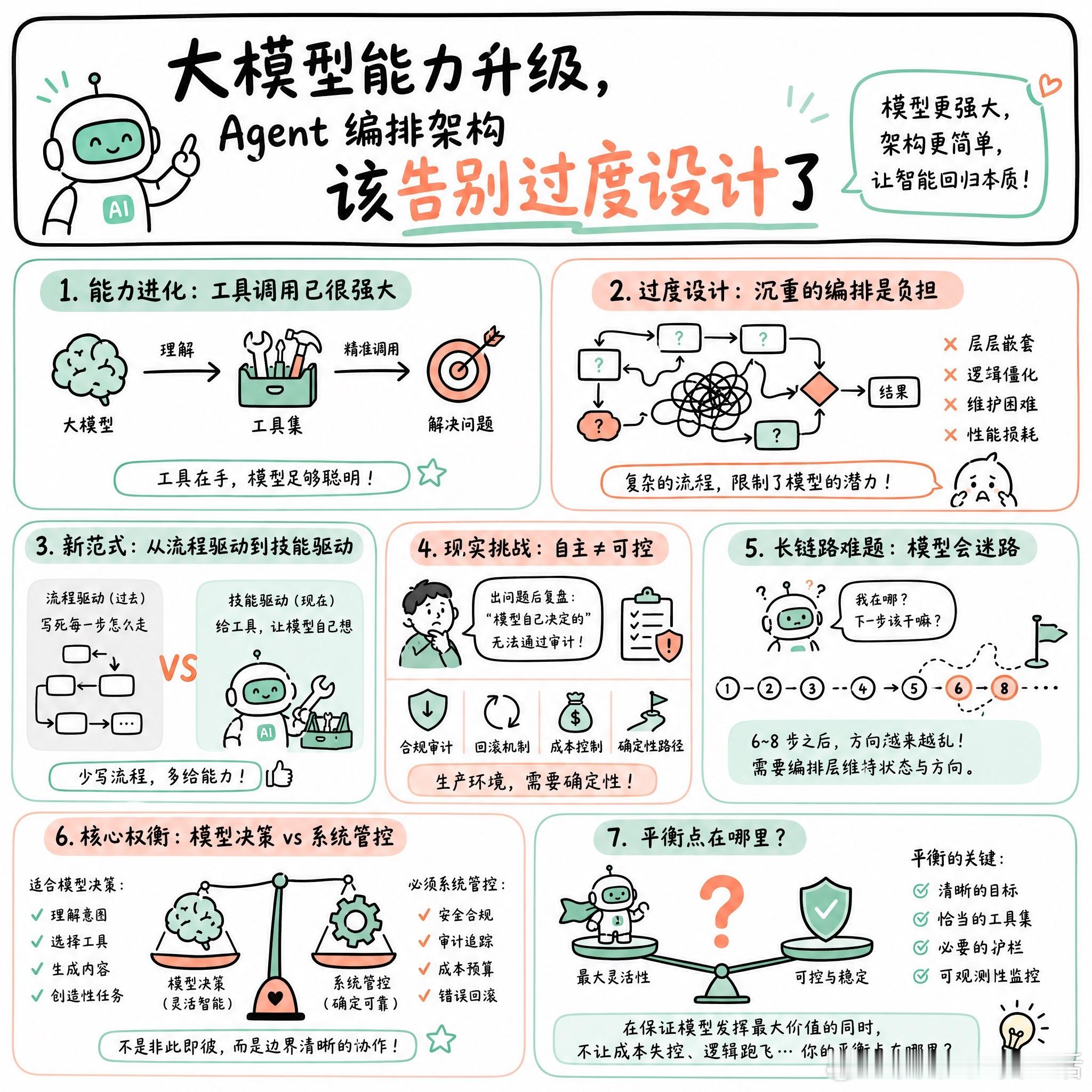
快速阅读:随着大模型工具调用能力的进化,过度设计的编排框架正逐渐成为性能负担。虽然“让模型自主决策”能提升灵活性,但在生产环境中,如何平衡模型的自主性与系统的确定性(如审计、回滚、成本控制)仍是核心难题。
现在的 LLM 已经强到不需要你再手写复杂的 LangGraph 流程图了。
以前我们写 Agent 架构,总是在模型能力不足时,试图用层层嵌套的逻辑去“补课”,把编排框架写得像传统的业务工作流引擎一样沉重。但现在,这种过度设计的编排反而成了性能的阻碍。既然模型已经能精准地调用工具,为什么还要用一种僵化的指令去限制它?
有个说法很有意思:现在的 Agent 架构正在从“流程驱动”转向“技能驱动”。与其写死每一步怎么走,不如给它一套趁手的工具集,然后让它自己去解决问题。
不过,这种“放权”在演示 Demo 时效果惊人,到了生产环境就会遇到骨感的现实。
有网友提到,如果完全交给模型,在出现故障进行复盘时,那句“模型自己决定的”根本无法通过合规性审查。当业务需要确定性的路径、审计追踪、或者是强制的错误回滚时,纯粹的自主性会迅速崩塌。
这本质上是在做一次系统层级的权衡:哪些决策属于模型,哪些决策必须属于系统。
如果是一个简单的异步循环,定义好目标和工具,模型就能跑得很顺;但如果面对复杂的长链路任务,模型在 6 到 8 步之后往往会“迷失方向”。这时候,如果没有一个编排层来维持状态,系统就会陷入不可控的混乱。
我们其实是在试图把概率性的模型,塞进确定性的工程框架里。
那么,在保证模型发挥最大灵活性、同时又不至于让成本失控或逻辑跑飞的前提下,那个平衡点到底在哪里?
x.com/paulabartabajo_/status/2055498762601021452