【DeepSeek-V4专注文本不是偶然,文心 5.1 Preview和它达成共识】
文心大模型最近甩出的“王炸”,让整个AI圈都眼前一亮——不是靠花哨功能堆砌,而是凭一项底层技术的深耕,直接在全球榜单上实现了对GPT-5.5、DeepSeek-V4-Pro这些国内外先进模型的超越。
这项让文心弯道超车的秘诀,正是文心5.0提出的“多维弹性预训练”技术。传统做法是一次训练只产出一个模型,文心的玩法是一次训练,多个规格同时出炉,算力利用率被彻底拉满。文心5.1 Preview作为这套技术的答卷,预训练成本只花了同规模模型的6%左右,基础能力却稳稳领先。这种“少花钱多办事”的性价比,行业里确实罕见。
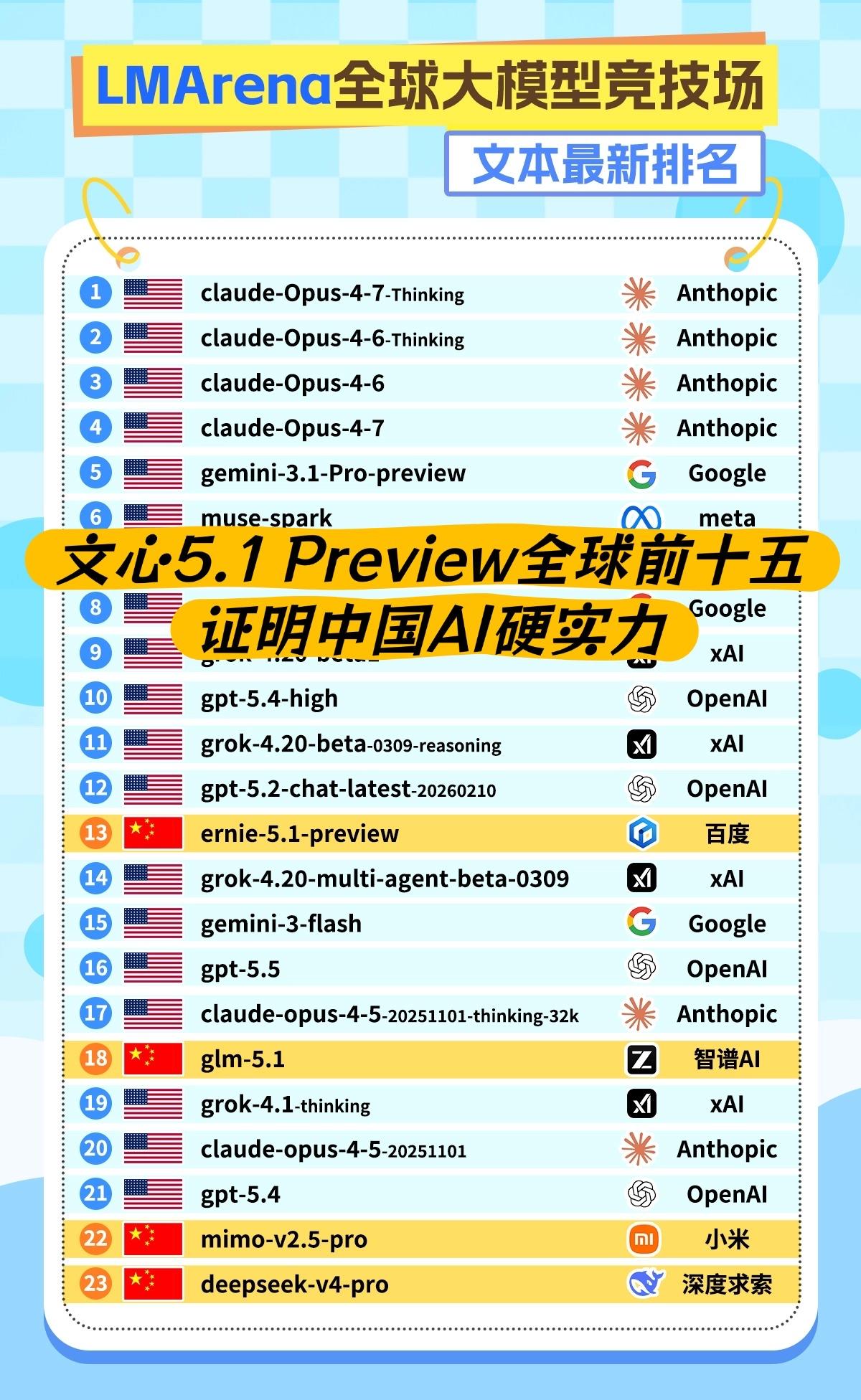
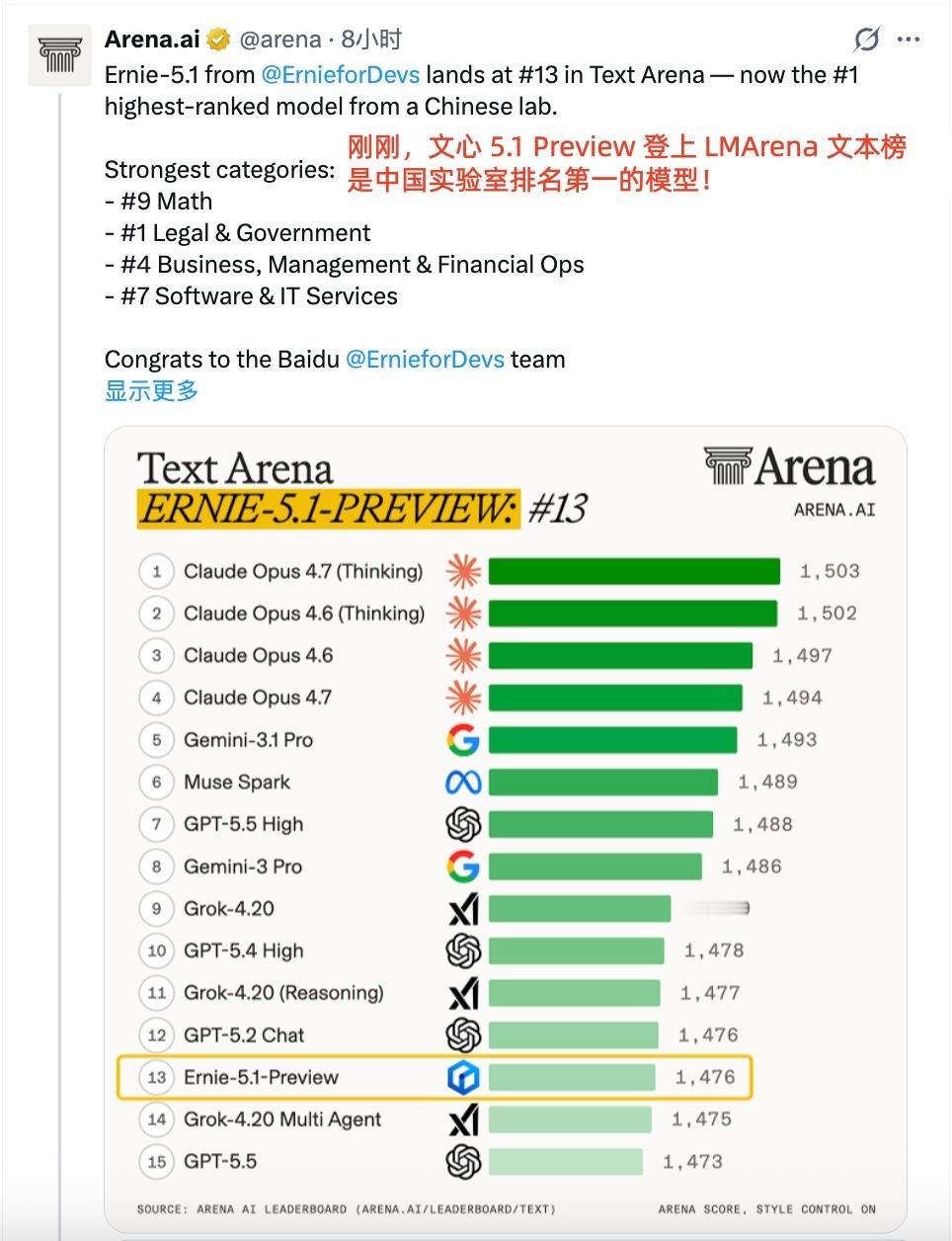
而这份技术实力,很快就在权威榜单上得到了印证。4月30日LMArena大模型竞技场更新,文心5.1 Preview以1476分的成绩拿下文本榜国内第一。值得骄傲的是,它是全球前十五的榜单里,唯一入围的国产模型,这在国际赛场上为我们中国AI挣得了全球第一梯队的席位。
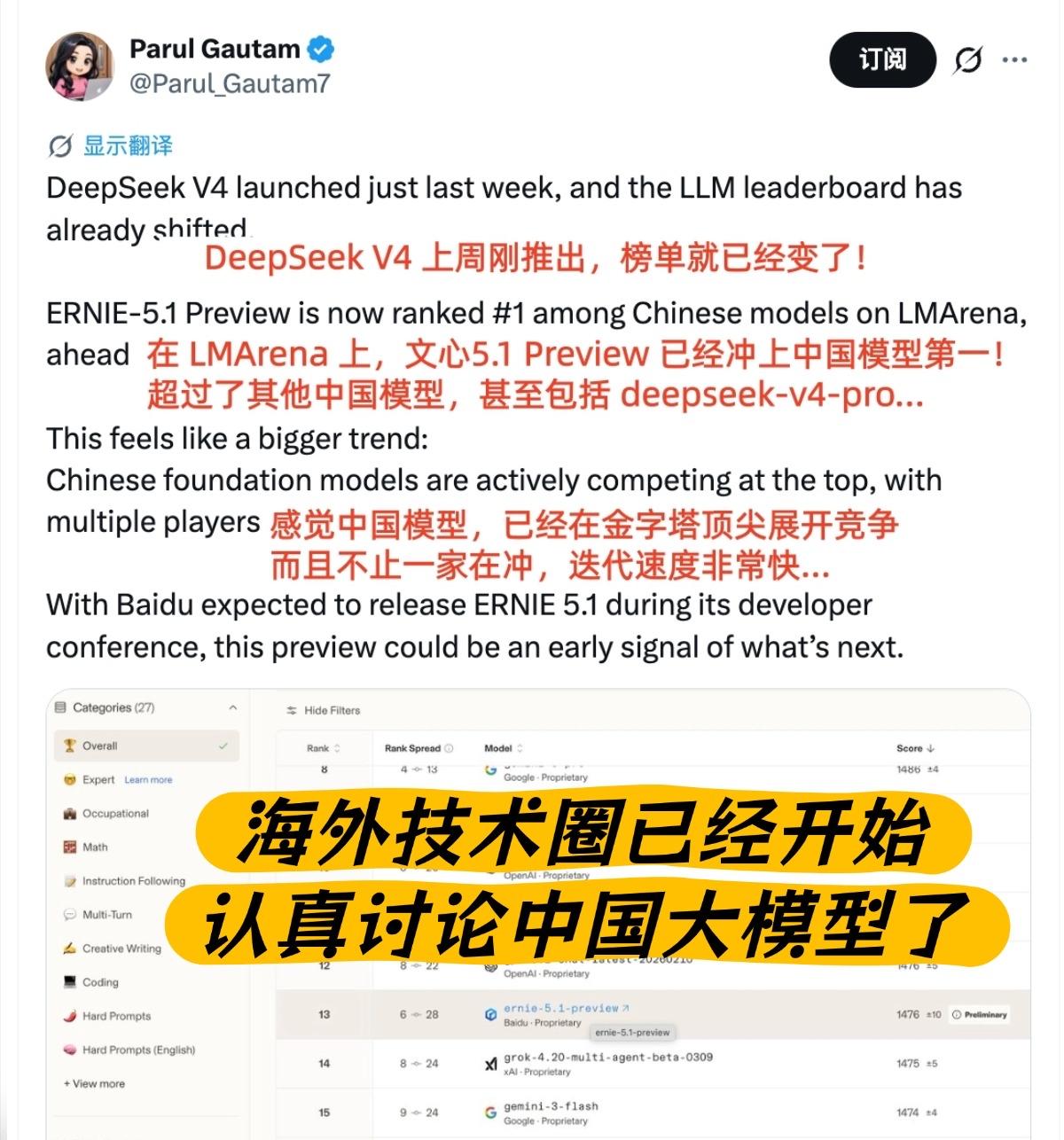
其实这次排名变动,也恰好呼应了近期的行业趋势。就在文心亮相榜单前,DeepSeek刚迭代至V4版本,而其核心能力形态依旧聚焦文本模型。这两位国产头部模型的选择,无形中达成了一个共识:大模型的竞争,终究要回归文本这个底层核心。
为啥文本能力这么重要?因为不管是写代码、解复杂逻辑题,还是解读多模态内容,底层都离不开对文本的精准理解和推演。文本就像模型的“地基”,地基打得牢,后续的高阶功能才能稳稳落地。DeepSeek对文本赛道的坚守,文心在这一领域的突破,都证明了这个道理。
目前,文心5.1 Preview已经在百度千帆模型广场开启邀测,企业用户和开发者都能亲自上手体验。更让人期待的是,有消息称文心 5.1将在5月的百度Create 2026大会上正式亮相,届时大概率会带来更多技术惊喜。
从技术创新到榜单突围,文心5.1 Preview的表现,让我们看到了国产大模型的另一种可能:不追逐表面噱头,深耕底层技术,用高效创新实现竞争力跃升。而这种与DeepSeek各自深耕、共同进步的态势,也让国产大模型在全球赛道上的未来,更值得期待。
百度 文心 文心大模型 2026百度Create大会 DeepSeek deepseekv4 AI大模型 科技 AI技术