从能不能用到好不好用,国产算力只用了三年,这速度谁顶得住
三年前提起国产AI芯片,圈内人第一反应:兼容性咋样?能跑起来吗?会不会老崩?说实话,那时候没人敢把核心业务放在国产算力上。
最近在国家超算互联网核心节点,大家看到的是:3万张国产计算加速卡,稳定跑大模型训练,网络效率追平国际一流。这三年发生了什么?不是魔法,是一点一点啃硬骨头。
答案藏在细节里:
自研RDMA,不再被博通卡脖子,通信协议自己说了算
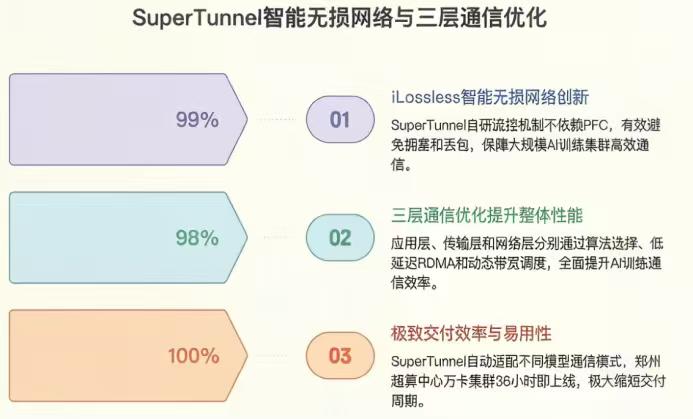
SuperTunnel核心设计,专为大模型通信优化,把延迟干到微秒级
单口397亿实测带宽,离理论极限只差1%,这1%是为了稳定留的余量
Spine-Leaf架构优化,3万卡通信不打架,集合效率拉满
11万卡最大组网能力,未来三年不用推倒重来,保护投资
有人问:国产的和NV比到底差多少?我说句实话:差距在缩小,有些指标已经持平,比如带宽、规模、稳定性。但最大的不同是——这套东西完全自主可控,想怎么优化就怎么优化,不用看别人脸色,不用怕哪天被断供。
从能用到好用,这条路很难,比单纯堆硬件难多了。但我们已经走在路上了,而且走得挺快。下次再有人说国产不行、国产是样子货,就把这篇文章甩给他!