只因GitHub上一个坚守数十年的排名被悄悄改写:
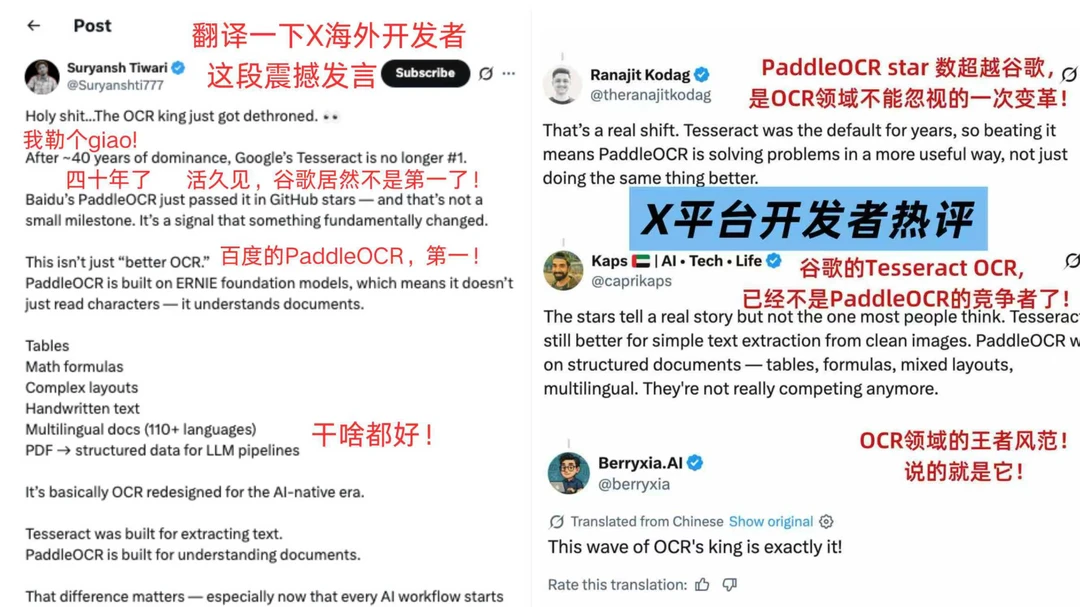
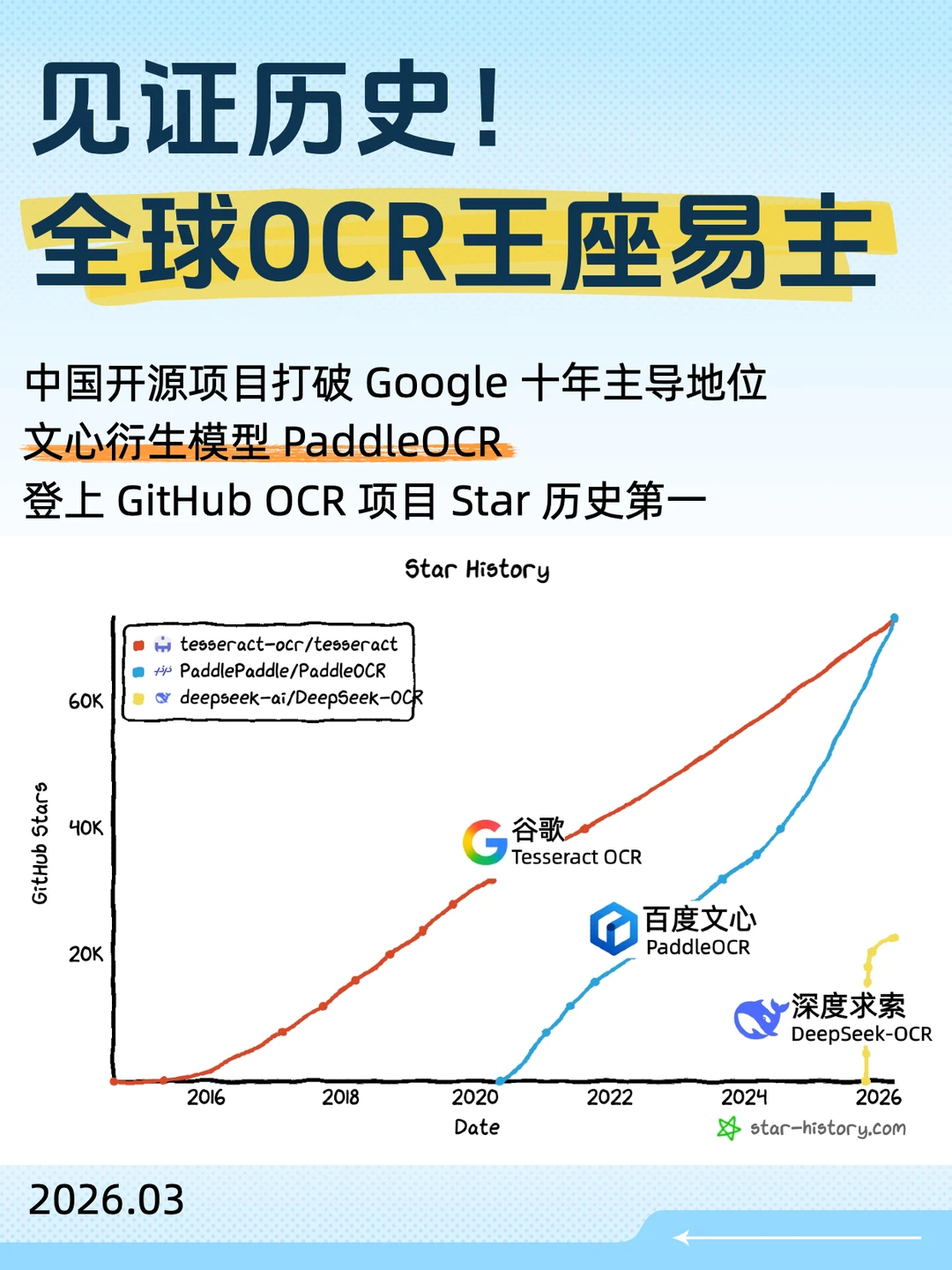
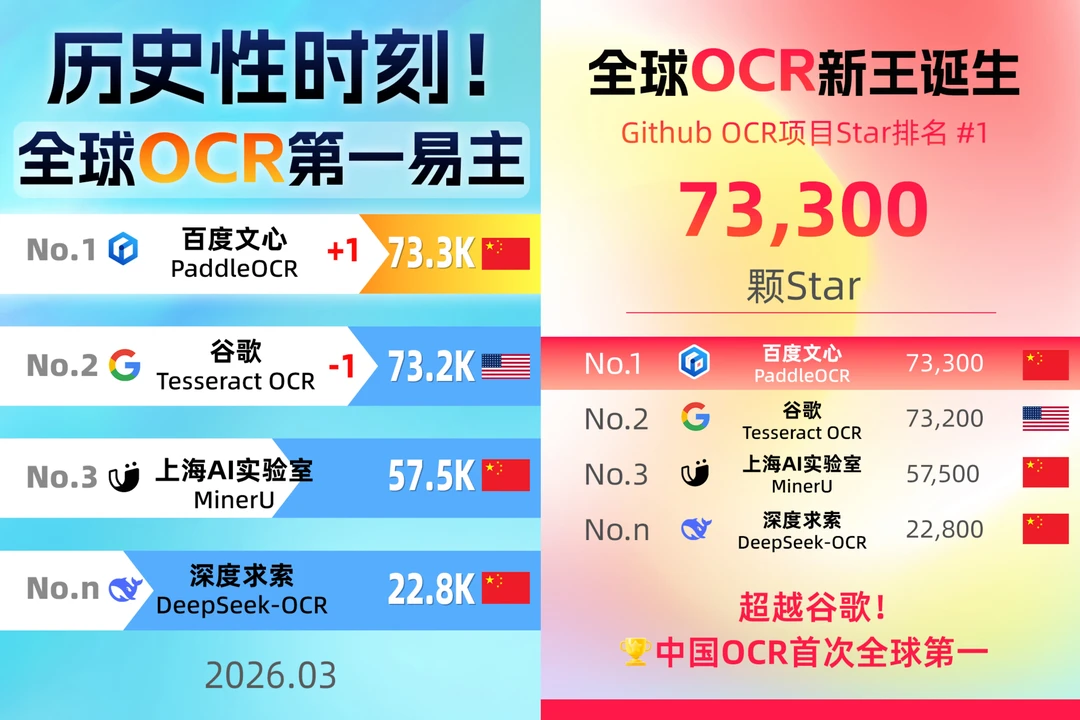
百度文心衍生模型PaddleOCR的Star数(73.3k)稳稳超过谷歌Tesseract OCR(73.2k),正式登顶全球第一。📈
看似微小的差距,背后却藏着中国技术崛起的十足底气。
很多人不清楚Tesseract OCR的分量,它1985年诞生于惠普实验室,后被谷歌接手,在OCR赛道称霸整整40年,是全球开发者的“标准答案”和默认首选,更像是美国科技巨头筑起的开源技术壁垒,无人敢轻易奢望超越。
如今,这个被谷歌攥在手里几十年的标杆位置,被中国企业稳稳拿下。这绝非简单的排名反超,更是全球OCR领域“技术默认权”的交接——从前核心技术赛道,我们跟着美国标准跑,如今终于凭硬实力站上世界顶端,从“跟跑”到“领跑”的转变,格外提气。🤨
翻了翻GitHub评论区,满是振奋:老外纷纷打出“Amazing”,留言称赞其好用,无质疑、无酸评,全是纯粹的认可。不同于以往中国技术出海时老外“便宜但不够顶尖”的观望态度,这次他们主动安利中国OCR,这份转变比排名第一更有分量,也让国人的自豪感油然而生。🥳
PaddleOCR的爆发绝非偶然,它背靠文心大模型,自2024年起Star数爆发式增长,一路稳步追赶。它不仅技术能打,还懂开发者需求:免费解析页数翻倍、接入OpenClaw便捷调用、成立生态联盟,产品力与运营双轮驱动,这份踏实正是中国技术的底气。
不可否认,谷歌仍是科技巨头,但在开源OCR这个核心赛道,“默认选它”的位置已属于中国。看着老外接连点赞安利,作为中国科技从业者,心中的自豪感按耐不住😭。这不仅是PaddleOCR的胜利,更是中国AI崛起的缩影,是我们在中美科技竞争中,凭硬实力赢得的又一份荣光。