[LG]《Scaling Atomistic Protein Binder Design with Generative Pretraining and Test-Time Compute》K Didi, Z Zhang, G Zhou, D Reidenbach… [NVIDIA] (2026)
在蛋白质结合物设计领域,如何从头生成能与特定靶蛋白精准结合的候选分子,是一个长期未解的难题。现有方法陷入两种对立:生成式模型依赖训练数据生成候选结构,但推理阶段固定;幻觉优化法(如BindCraft)通过结构预测模型的梯度反馈直接搜索序列,却缺乏生成先验的约束。这一割裂使两类方法各有明显短板。
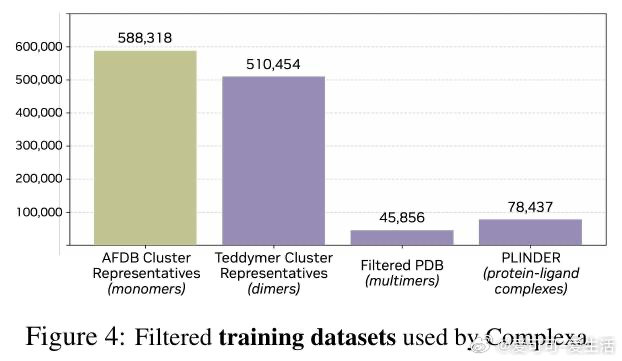
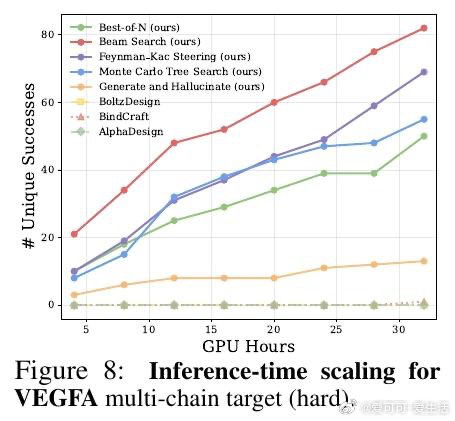
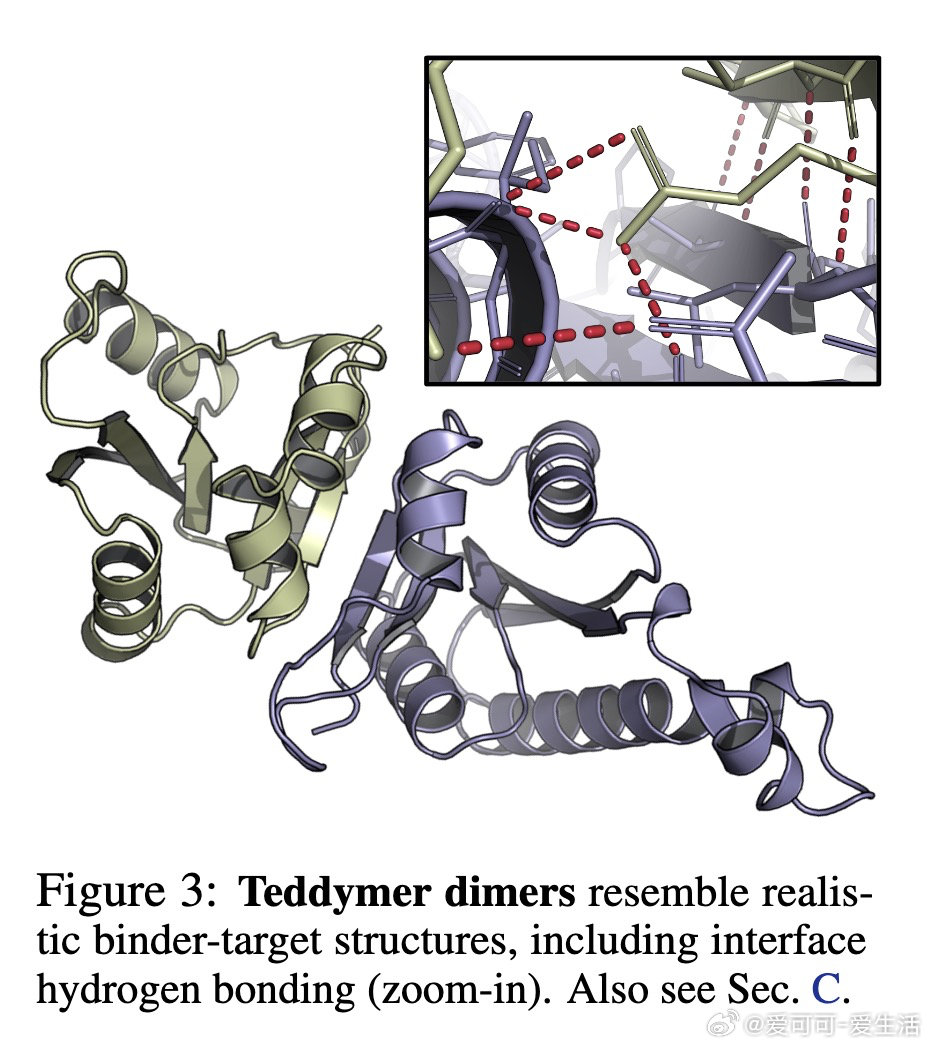
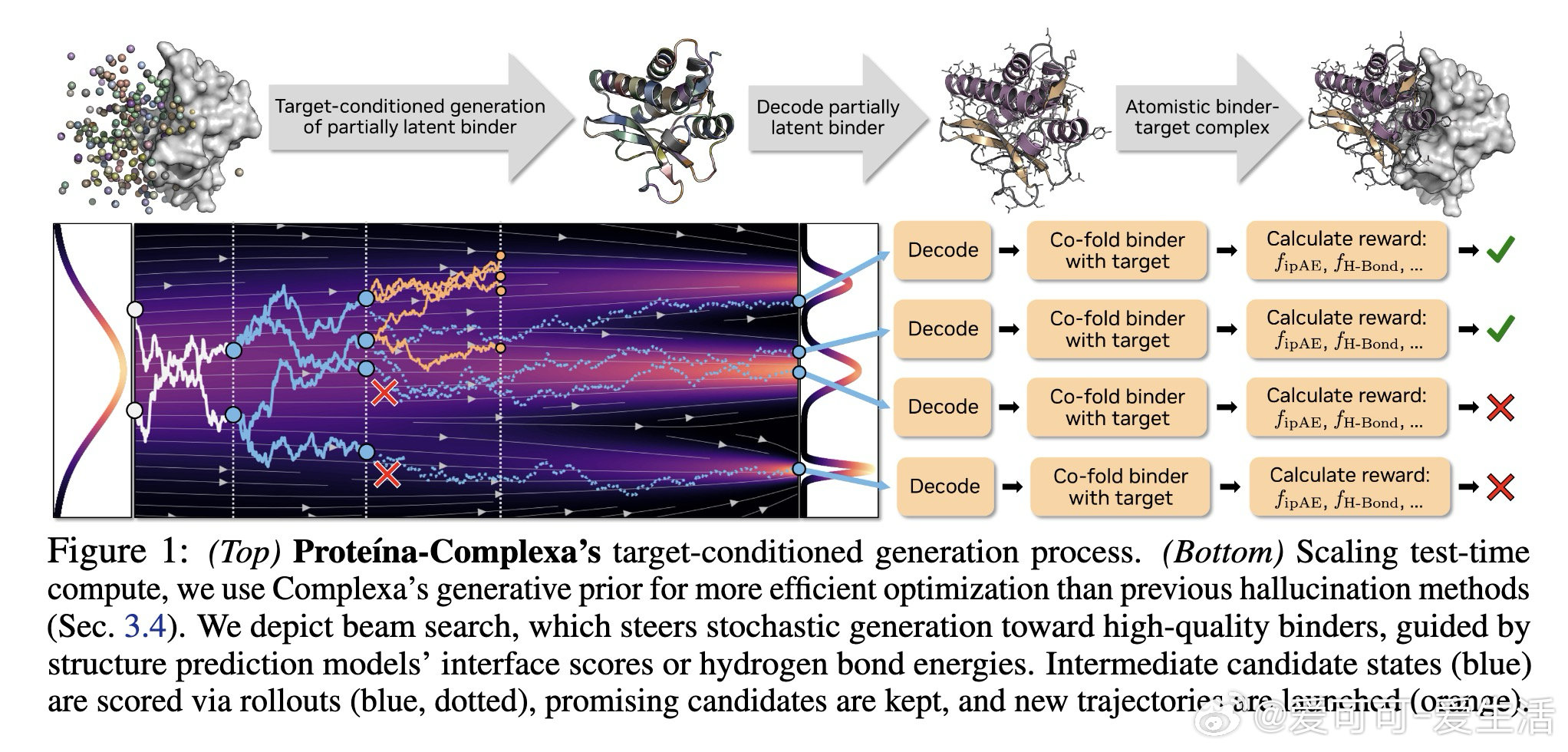
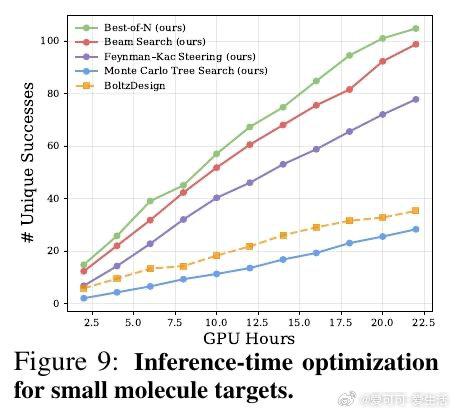
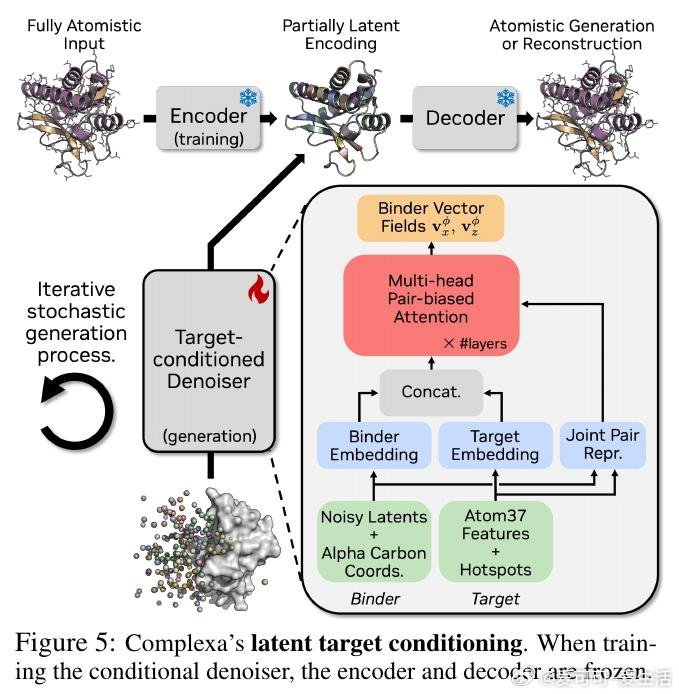
本文的核心洞见是:把生成先验与推理时搜索重新看作一个统一框架的两端,而非互斥范式。由此,Complexa将流匹配生成模型与束搜索、Feynman-Kac引导粒子采样、蒙特卡洛树搜索等推理时优化算法直接耦合,以结构预测置信分作为实时奖励信号驱动轨迹剪枝。同时,通过将AlphaFold数据库中多域蛋白的域间相互作用重构为合成二聚体数据集Teddymer(350万个簇),破解了实验级配对复合物数据稀缺的瓶颈。
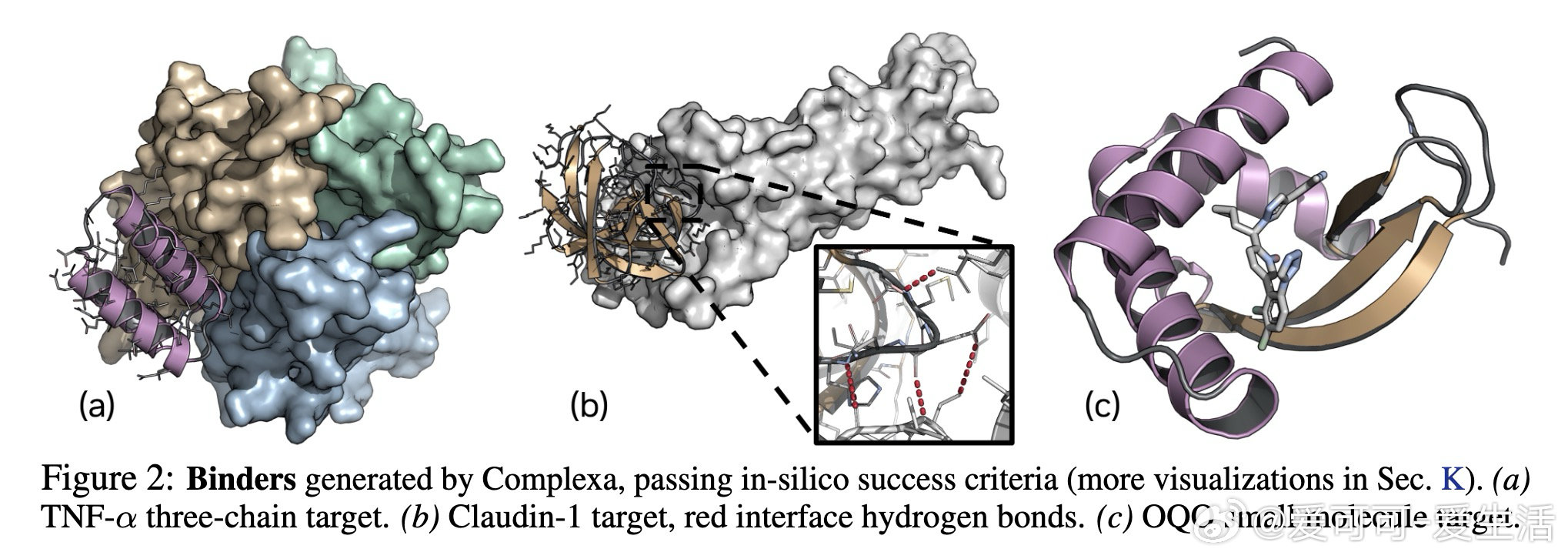
这项工作真正留下的遗产是:首次将大规模生成预训练与测试时计算缩放统一到蛋白质设计流程,在多个蛋白与小分子靶标基准上超越现有生成和幻觉方法,且无需额外序列重设计步骤。它为后来者打开的新门是:将物理能量项(如氢键)直接纳入搜索奖励,实现生成多样性与界面质量的协同优化。但尚未跨过的门槛是:所有成功指标仍基于计算预测,缺乏实验湿实验验证,且框架目前仅覆盖蛋白质与小分子靶标,对核酸等其他模态的泛化性尚未建立。
arxiv.org/abs/2603.27950
机器学习 人工智能 论文 AI创造营