[LG]《Next-Token Prediction and Regret Minimization》M Mohri, C Sanford, J Schneider, K Vodrahalli… [Google Research] (2026)
在预测序列建模领域,如何将下一词预测模型安全地用于对抗性决策,是一个悬而未决的难题。现有方法在随机环境中表现良好,却在面对恶意对手时无法保证后悔值次线性——本质原因是确定性最优响应会被自适应对手利用。
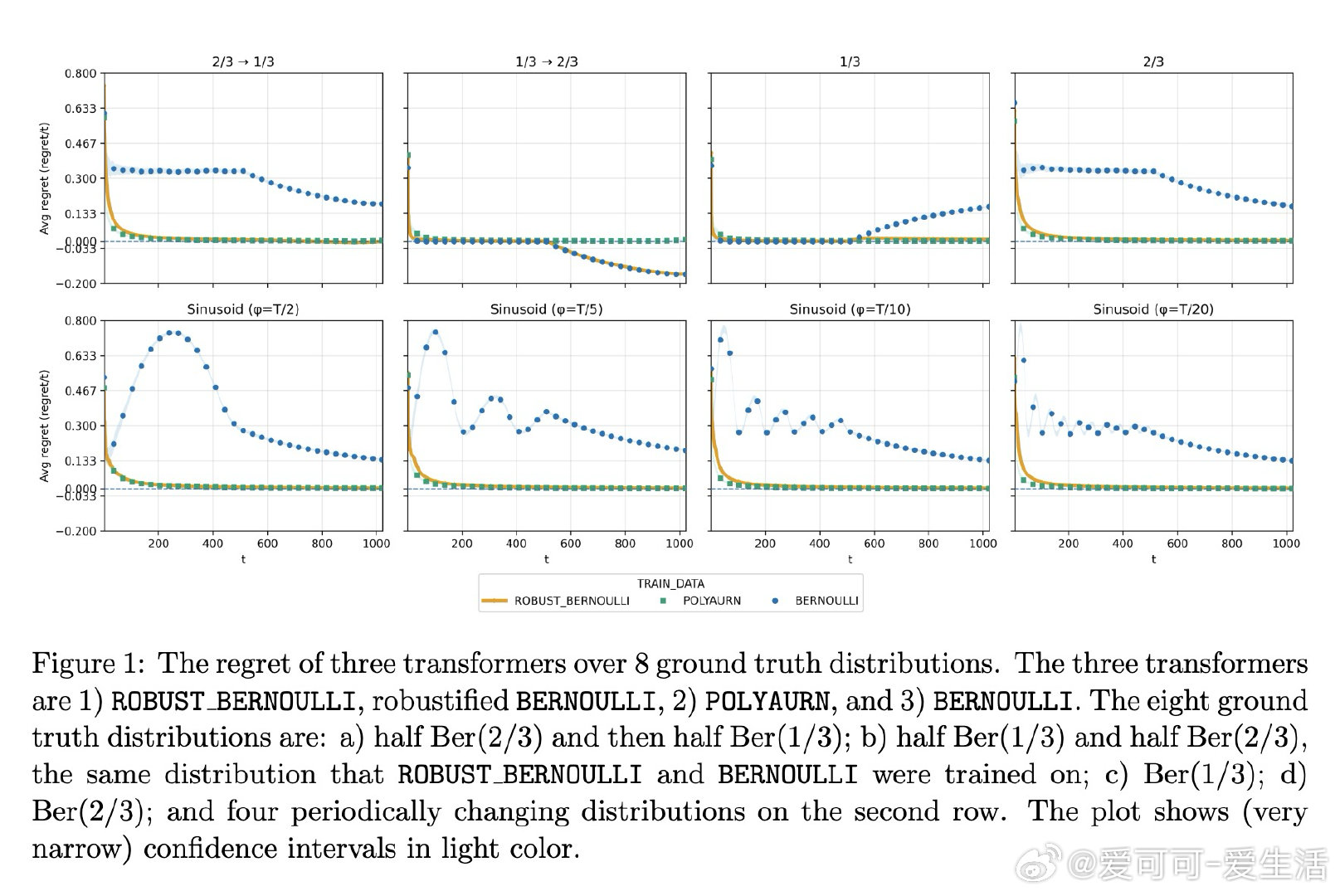
本文的核心洞见是:把"模型何时偏离真实分布"重新看作一个可在线检测的信号。由此,一种切换机制使问题得以解开:当累积后悔超过Polya瓮模型的基准后悔时,将预测权交给Polya瓮;否则沿用原模型。这使得模型在分布内保持原有预测精度,分布外自动触发低后悔策略,两者代价之积以指数量级趋近于零。
这项工作真正留下的遗产是:证明了预测精度与对抗鲁棒性在信息论层面相容,并将该机制具体落地为Transformer的四层扩展构造。它为后来者打开的新门是:如何用有限上下文窗口近似实现同等鲁棒性,以及如何推广至未知决策问题。但尚未跨过的门槛是:有界上下文的不可鲁棒化下界表明,Transformer的上下文长度约束是真实的性能瓶颈,而非可被绕过的工程细节。
arxiv.org/abs/2603.28499
机器学习 人工智能 论文 AI创造营