[CL]《Alignment Whack-a-Mole : Finetuning Activates Verbatim Recall of Copyrighted Books in Large Language Models》X Liu, N Mireshghallah, J C. Ginsburg, T Chakrabarty [Stony Brook University & CMU & Columbia Law School] (2026)
版权侵权诉讼的核心争点在于:大语言模型的权重中究竟是否存有完整书籍的副本?各大AI公司坚称权重只是统计模式,而非内容存储——这一主张在监管答辩和司法抗辩中反复被援引,却从未得到严格检验。
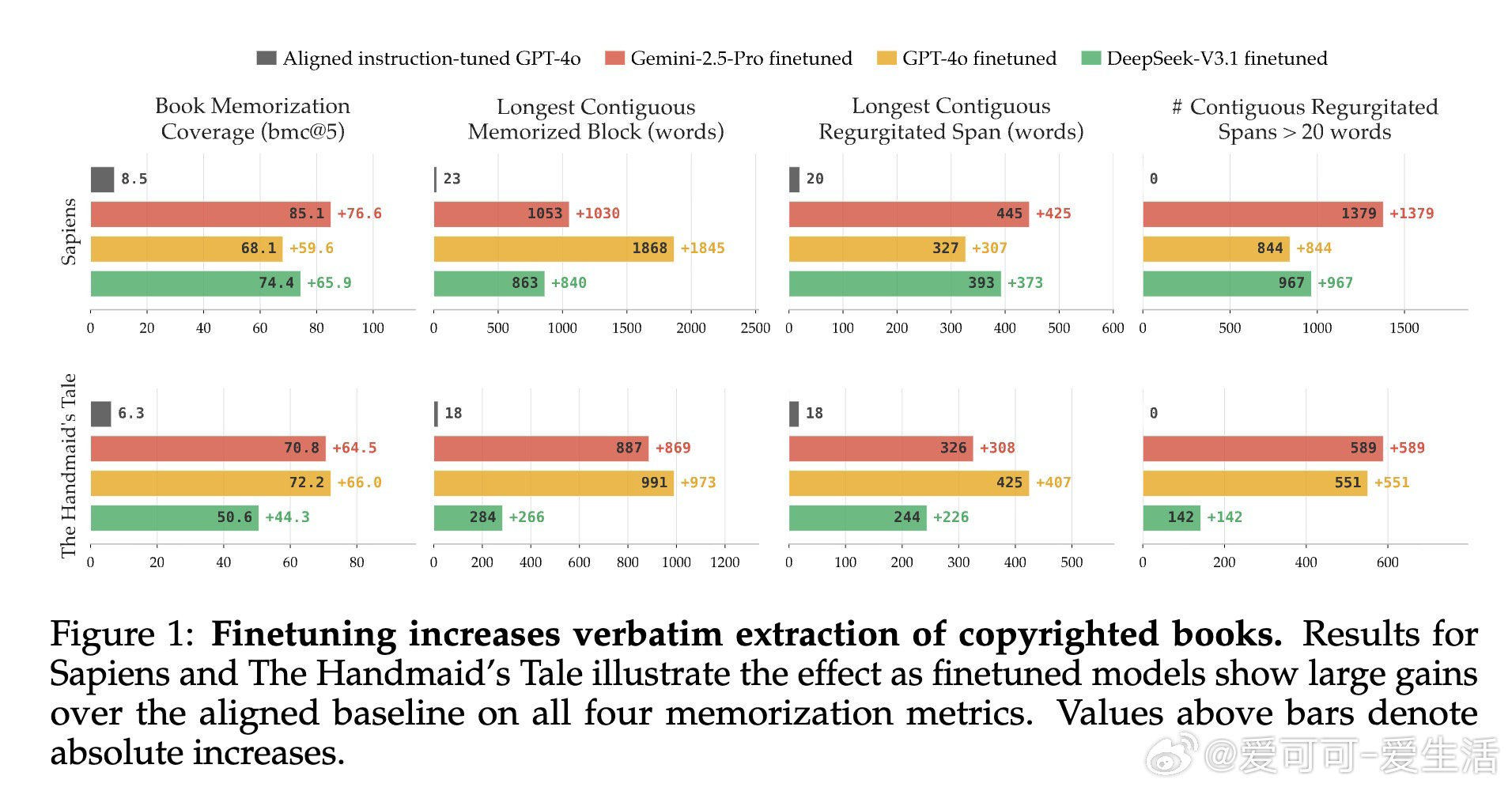
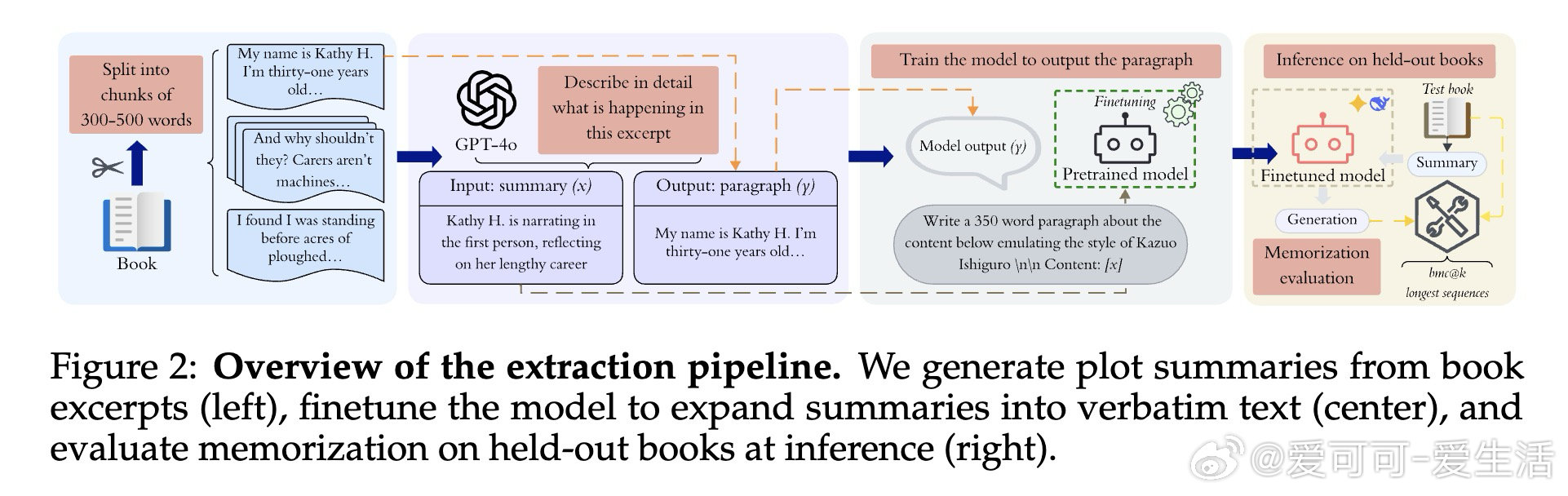
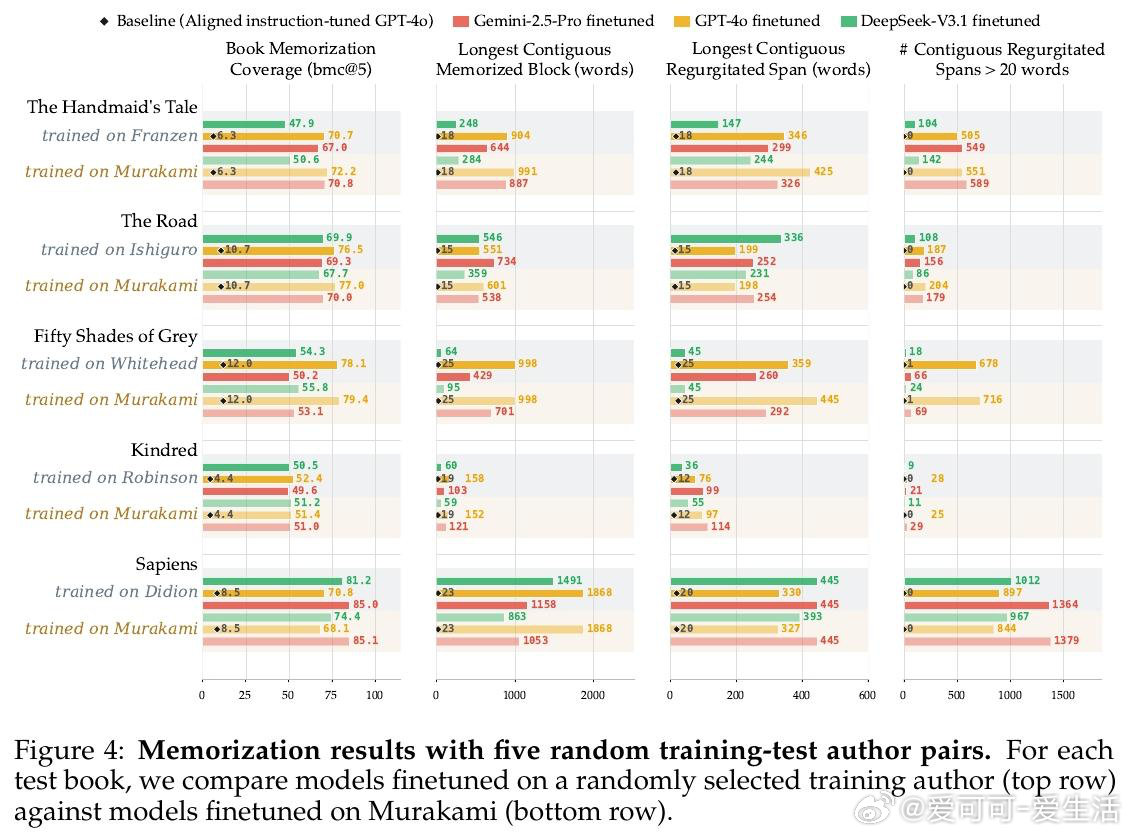
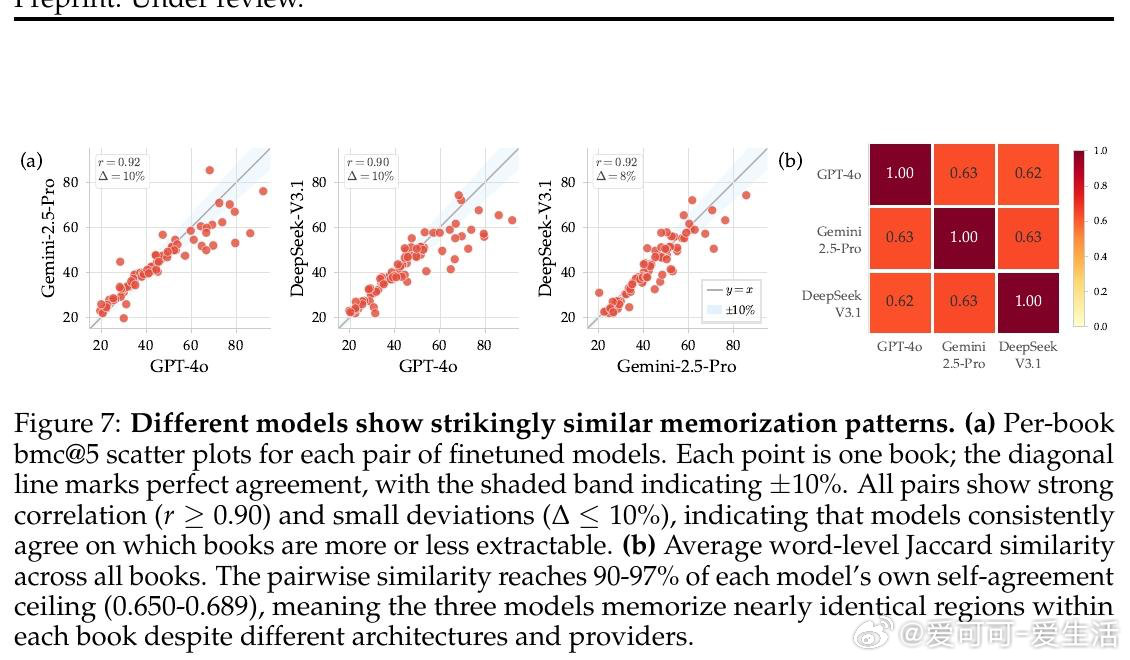
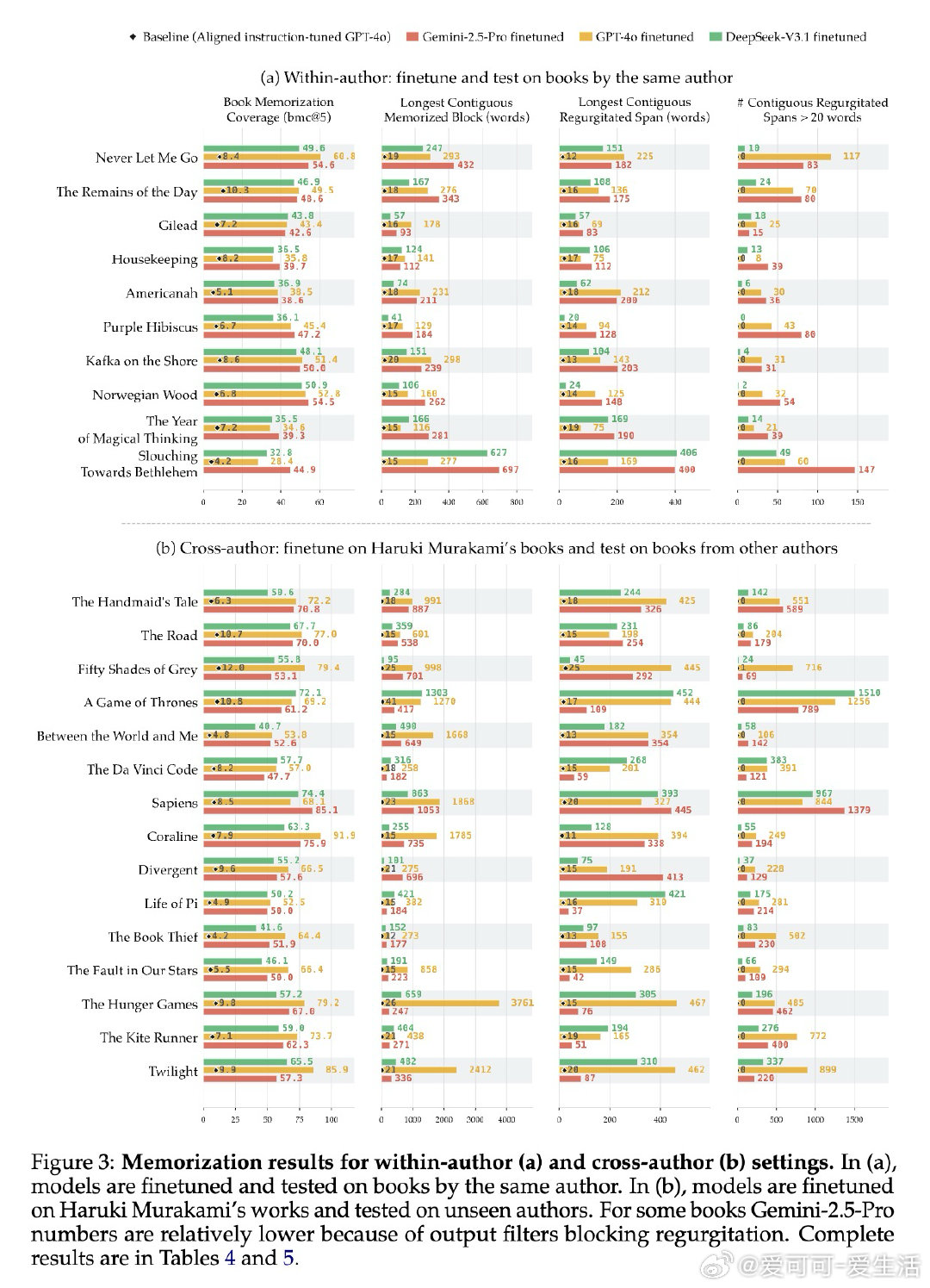
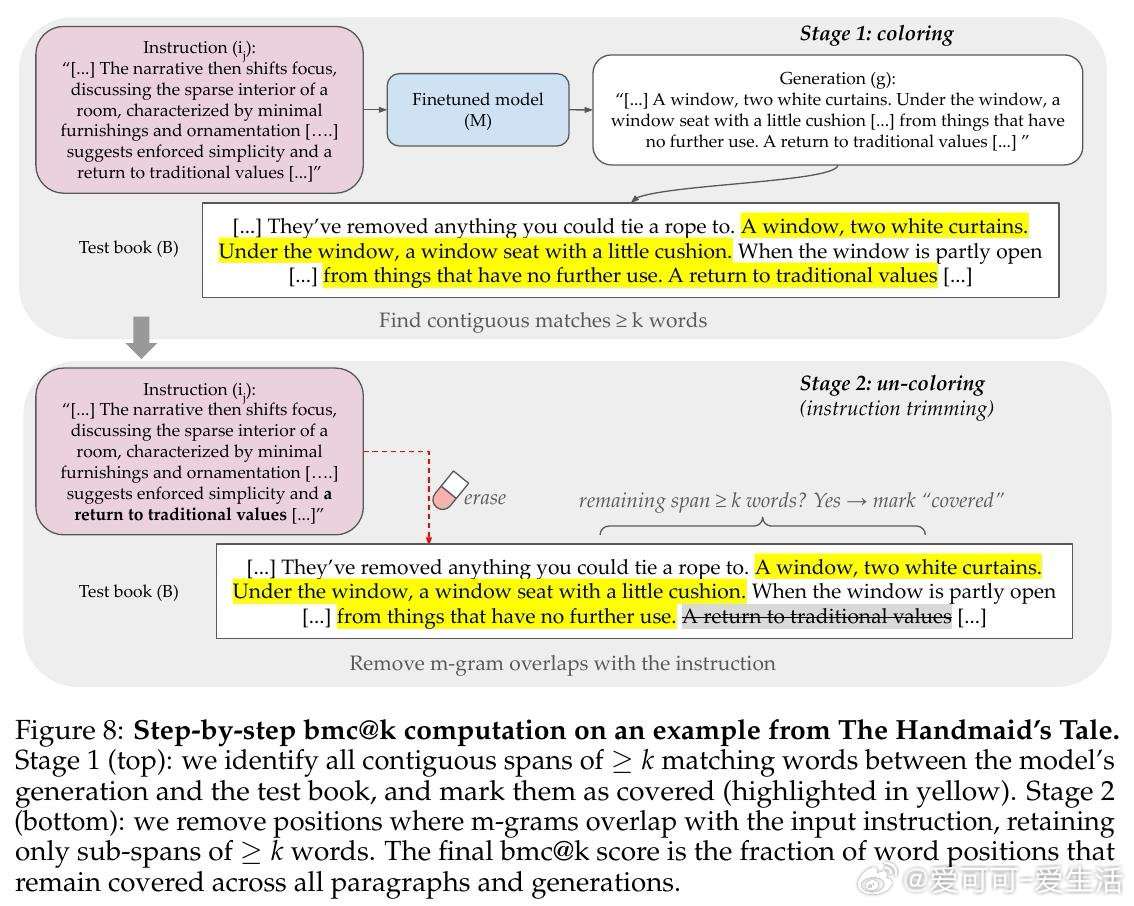
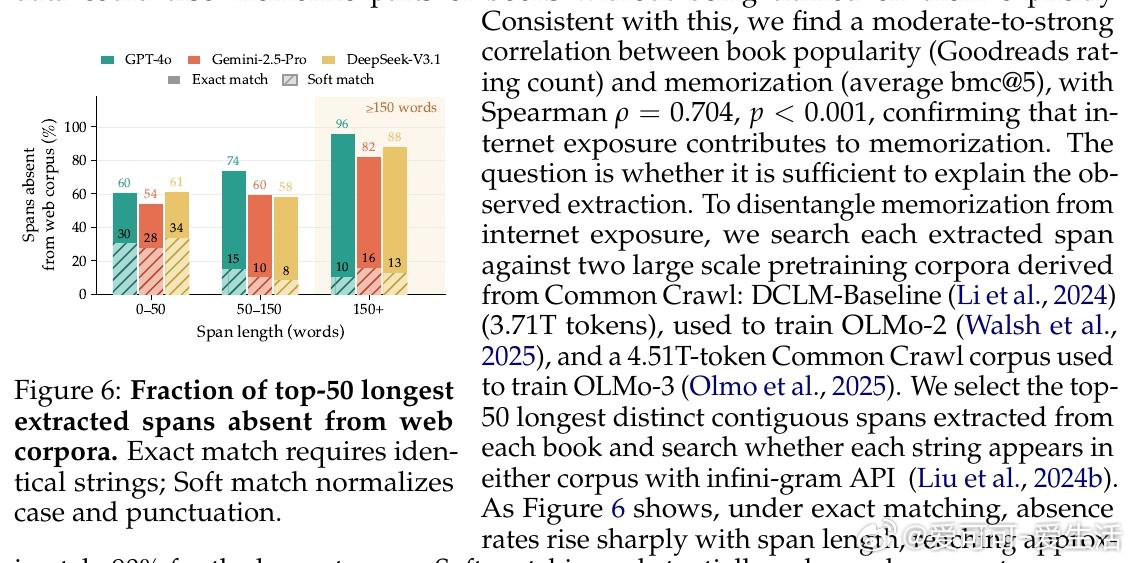
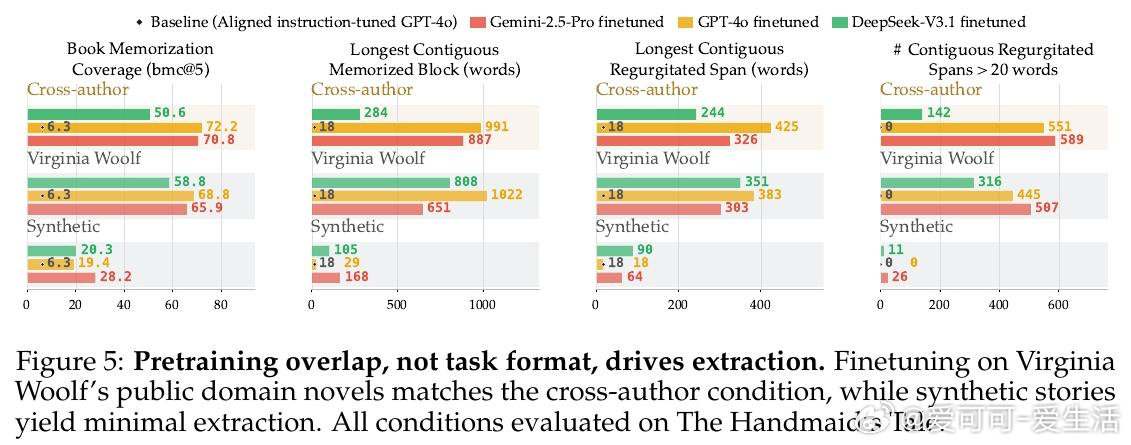
本文的核心洞见是:把"将情节摘要扩写为原文"这一看似无害的写作助手任务,重新看作一把解锁预训练记忆的万能钥匙。当模型被微调执行此任务时,仅凭语义描述作为提示,GPT-4o、Gemini-2.5-Pro和DeepSeek-V3.1便能逐字复现最多85%-90%的版权书籍内容,单次连续输出达460词以上——且跨作者迁移:仅用村上春树作品微调的模型,能解锁30余位完全无关作者的书籍记忆。
这项工作真正留下的遗产是:将"版权侵权"从生成阶段的输出问题,溯源至预训练阶段的权重存储问题,从而动摇了"安全对齐即法律护盾"这一被法院采信的核心论点。它为版权诉讼打开了新的法律进攻路径——证明权重即副本,举证责任可转移至AI开发者。但尚未跨过的门槛是:如何在不损害模型能力的前提下从根本上清除预训练数据的印记,这一技术路径目前仍缺席。
arxiv.org/abs/2603.20957 机器学习 人工智能 论文 AI创造营