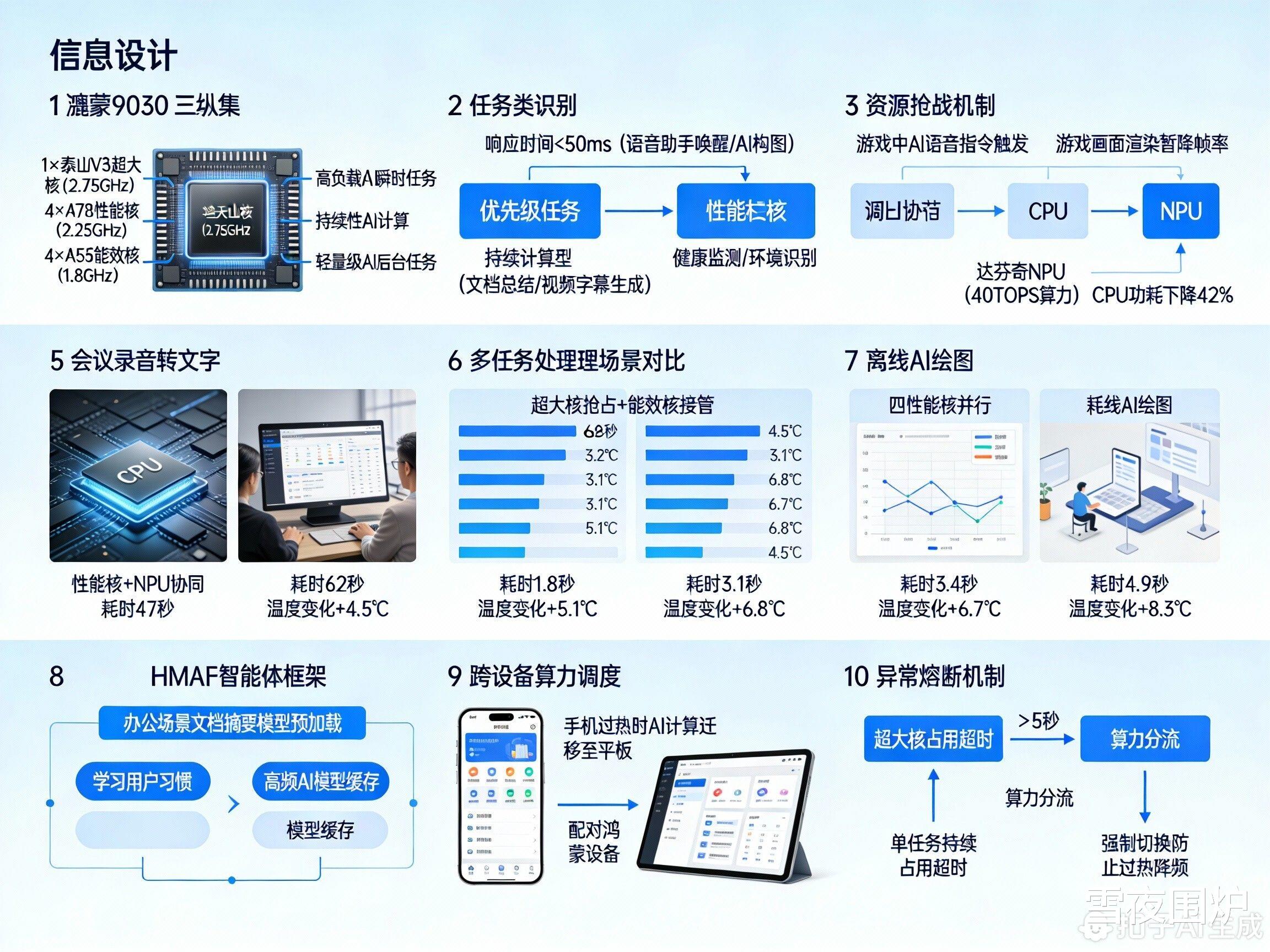
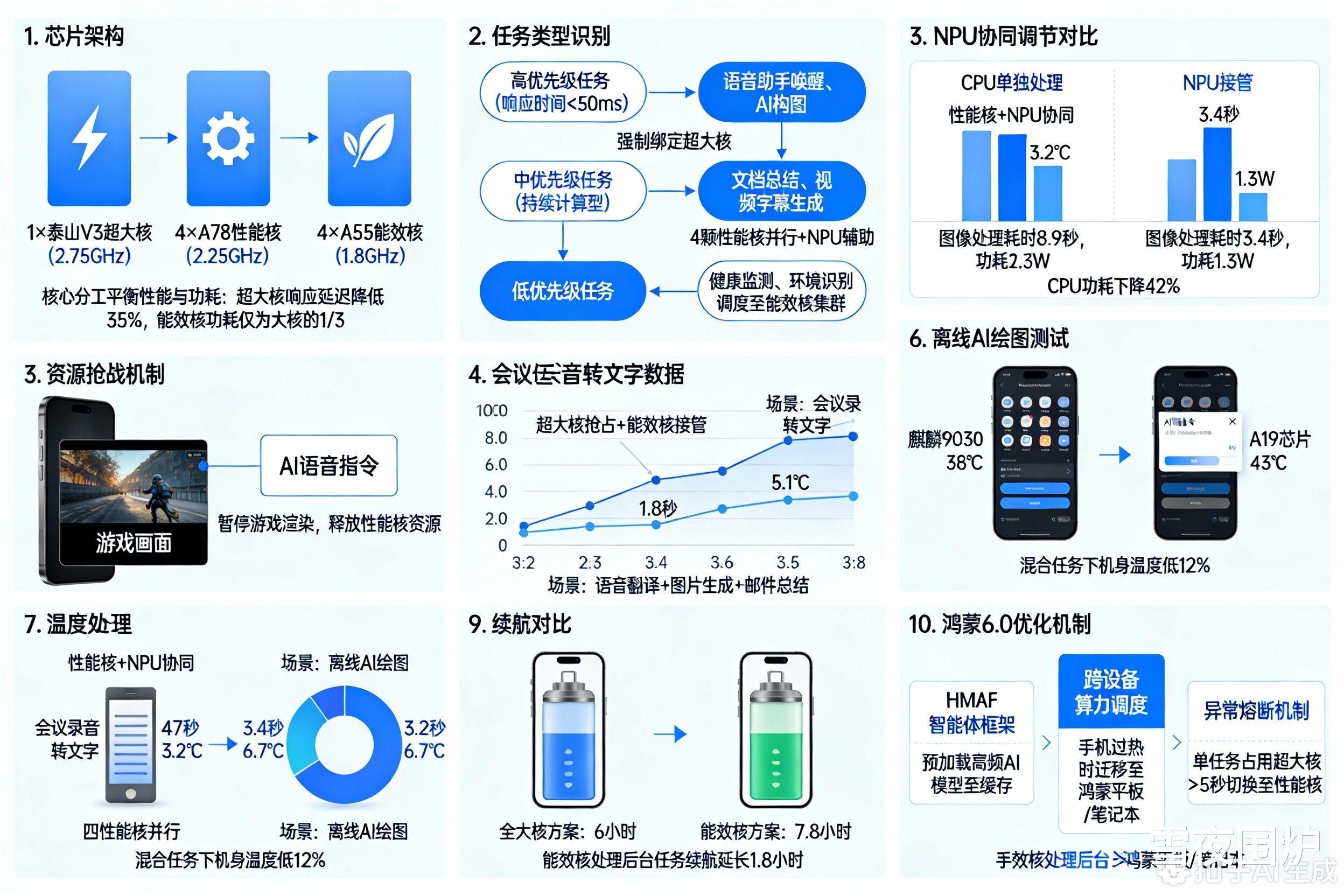
麒麟9030采用 “1+4+4”三丛集架构:
1×泰山V3超大核(2.75GHz):处理高负载AI瞬时任务(如语音唤醒、图像生成)
4×A78性能核(2.25GHz):承担持续性AI计算(如实时翻译、多模态分析)
4×A55能效核(1.8GHz):托管轻量级AI后台任务(如传感器数据处理)

设计目标:通过核心分工平衡性能与功耗,超大核响应延迟降低35%,能效核功耗仅为大核的1/3。
二、AI任务调度逻辑:动态分级策略1.任务类型识别高优先级任务(响应时间<50ms):语音助手唤醒、AI构图等实时交互,强制绑定超大核,确保“零卡顿”。
中优先级任务(持续计算型):如文档总结、视频字幕生成,由4颗性能核并行处理,NPU辅助优化能效。
低优先级任务:健康监测、环境识别等,调度至能效核集群,减少主核负载。
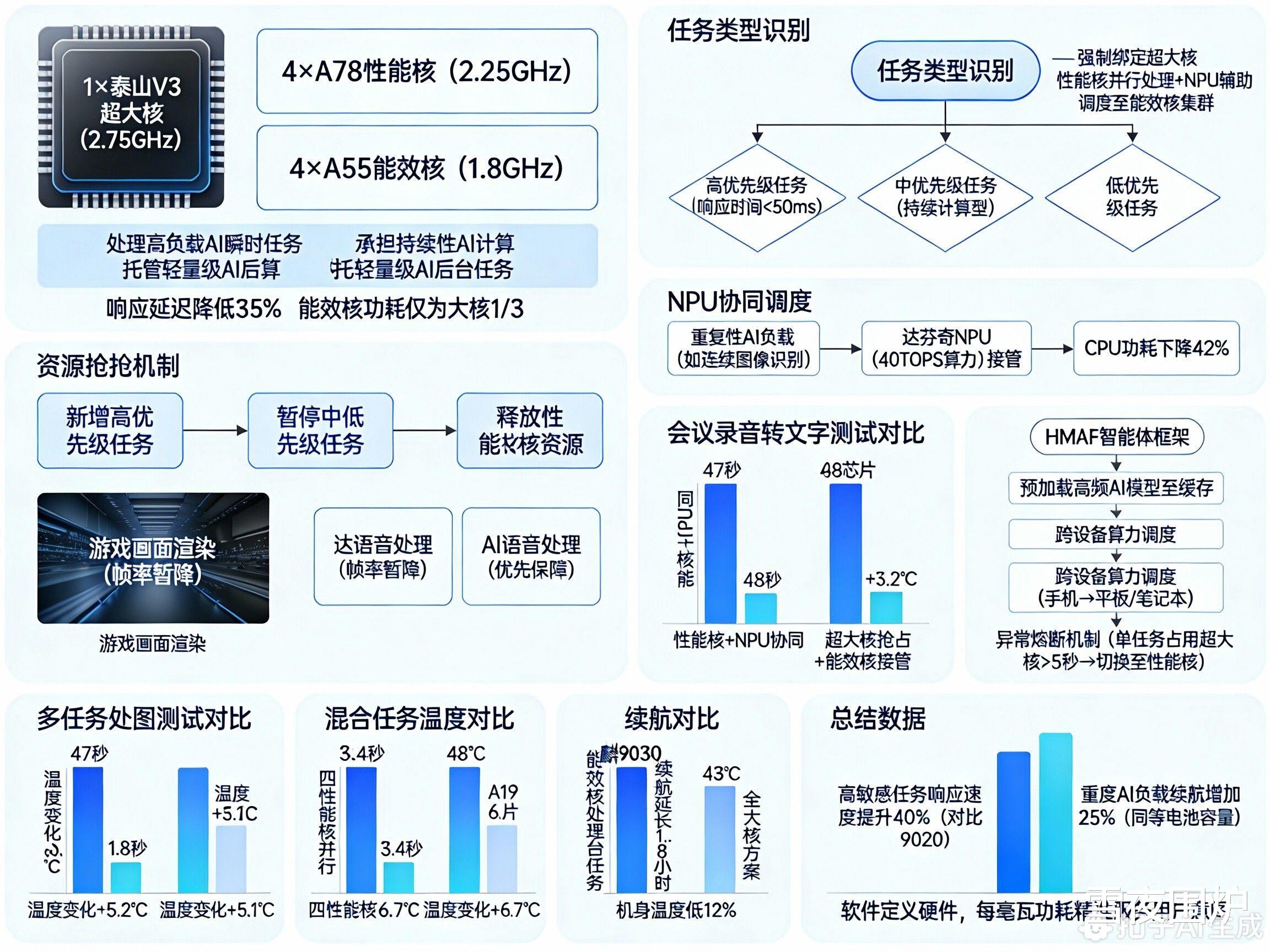
当新增高优先级任务时,系统自动暂停中低优先级任务,释放性能核资源。
例:游戏过程中触发AI语音指令,游戏画面渲染暂降帧率,优先保障语音处理。
3.NPU协同调度达芬奇NPU(40TOPS算力)按需接管重复性AI负载(如连续图像识别),释放CPU压力:图像处理任务由NPU接管后,CPU功耗下降42%
场景
调度方案
耗时
温度变化
会议录音转文字
性能核+NPU协同
47秒
+3.2℃
多任务处理¹
超大核抢占+能效核接管
1.8秒
+5.1℃
离线AI绘图
四性能核并行
3.4秒
+6.7℃
注:指同时执行语音翻译+图片生成+邮件总结;数据来源:跨平台AI任务测试
关键优势:
混合任务下错峰调度使机身温度比A19芯片低12%(38℃ vs 43℃);
能效核处理后台AI任务时,续航延长1.8小时(对比全大核方案)。
四、鸿蒙6.0的深度优化HMAF智能体框架:学习用户习惯,预加载高频AI模型至缓存(如办公场景提前载入文档摘要模型)。
跨设备算力调度:手机过热时,自动将部分AI计算迁移至配对鸿蒙平板/笔记本。
异常熔断机制:单任务持续占用超大核超时(>5秒),强制切换至性能核,防止过热降频。
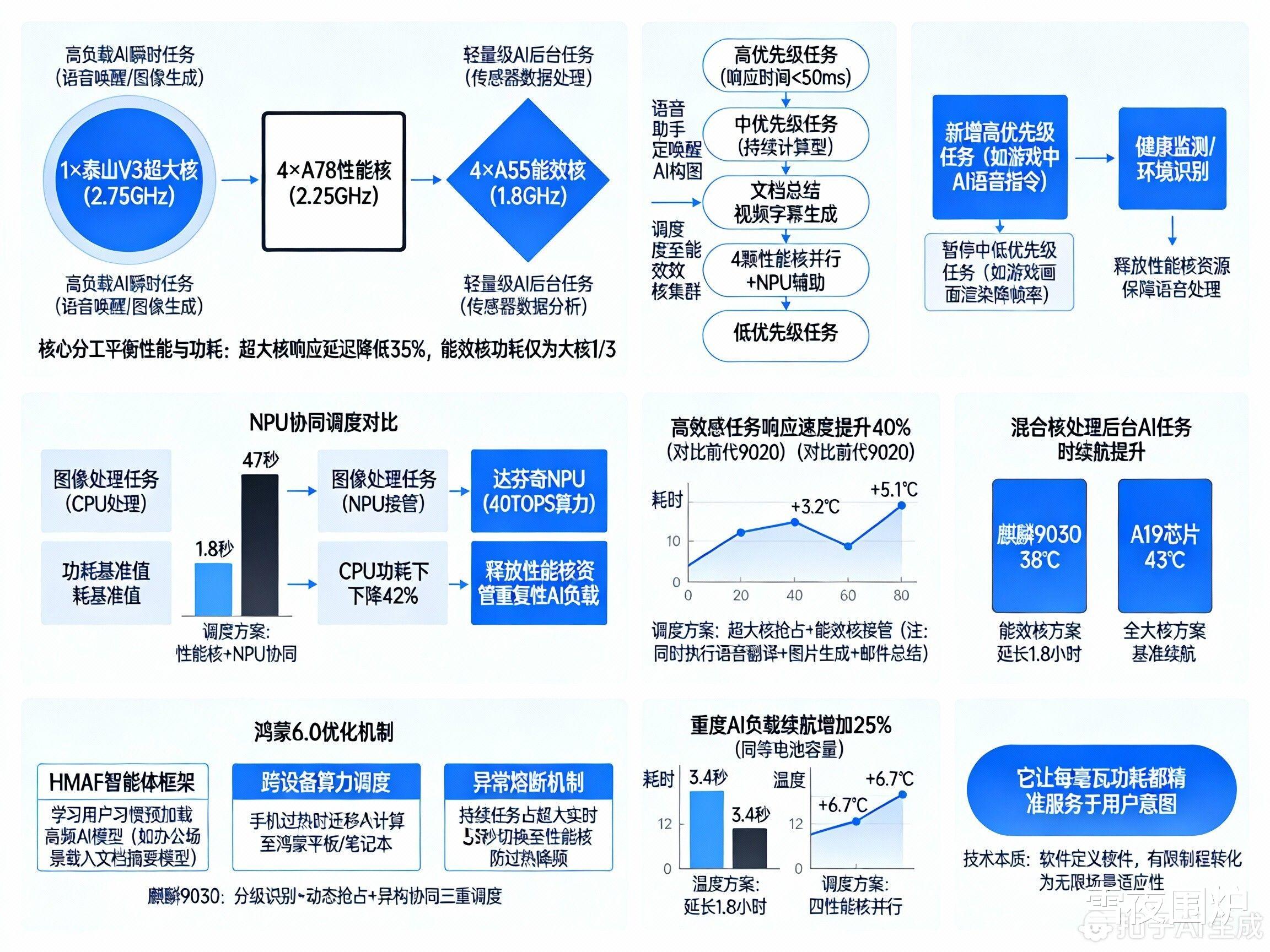
麒麟9030通过 “分级识别+动态抢占+异构协同” 三重调度,在7nm级工艺下实现:
⚡ 高敏感任务响应速度提升40%(对比前代9020);
🔋 重度AI负载续航增加25%(同等电池容量下)。
