知名国际榜单深夜点赞!中美AI对决近况,谁开始占上风了?
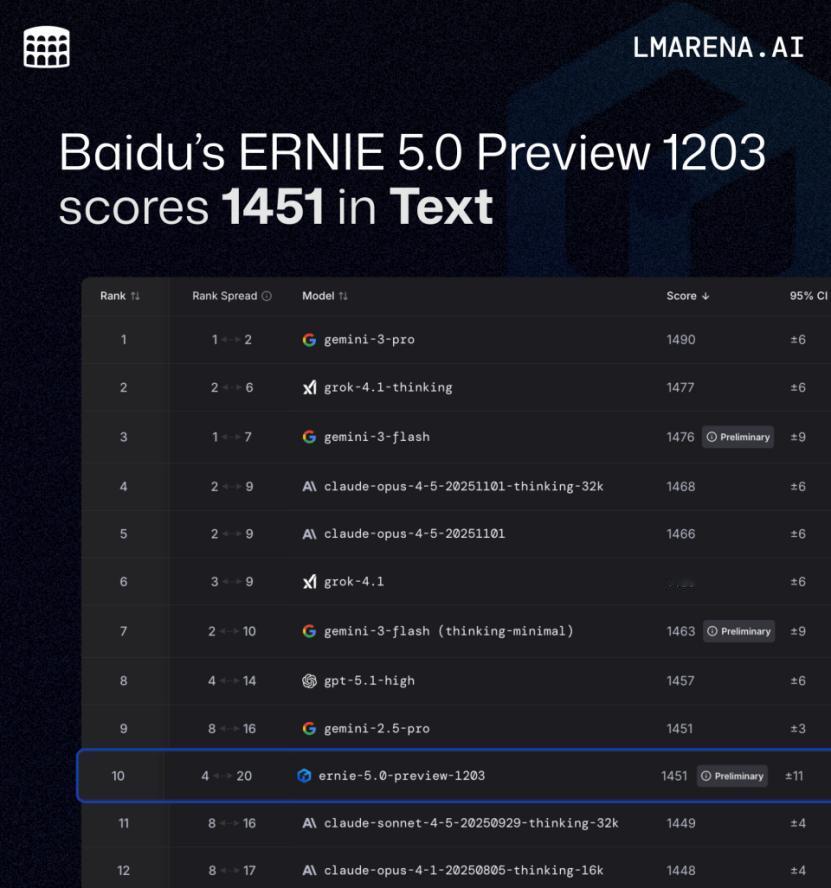
深夜更新的LMArena榜单,又带来了新变化。在最新一轮文本模型排名中,百度文心5.0 Preview(ERNIE-5.0-Preview-1203)以1451分稳居国内第一。但如果仅仅盯着排名数字,可能会错过这次更新中最值得玩味的信号。
真正的亮点藏在了能力维度分析里——拉开文心与其他模型差距的,并非传统的基础问答或事实检索,而是在创意写作、复杂提示理解这些最容易“翻车”的高阶任务上。
这一点至关重要。过去,不少大模型在标准测试集上表现优异,但在实际应用中,面对需要想象力、上下文深度理解和创造性表达的任务时,往往显得力不从心。这正是普通用户最能感知“AI是否聪明”的关键处,也是决定一个模型能否被长期使用、而不仅仅是“测评玩具”的分水岭。
LMArena的匿名对战机制,恰恰将这些真实场景中的挑战搬上了评测舞台。文心5.0能在这些环节建立优势,说明国产大模型的进化,正在跨越一个新的里程碑:从追求参数规模和响应速度的“硬指标”,深入到打磨理解人类意图、进行复杂思维和创造性表达的“软实力”。
这标志着竞争焦点的转移。早期的追赶更多体现在算力、数据和基础架构上,而现在,真正的较量开始转向对语言本质的理解、对逻辑的把握和对创造力的模仿。这是更接近“智能”本质的挑战,也是AI能否真正融入人类工作与生活的关键。
回顾文心近期在LMArena的表现,这一趋势有迹可循:从11月初登文本榜全球前列,到月中在视觉理解榜上达到国际主流水平,再到此次在最具挑战性的文本任务上巩固优势——它展现的不是单点突破,而是沿着“全模态理解与生成”这条主线的系统性进步。
根据官方介绍,文心5.0作为原生全模态大模型,其设计目标就是打通文本、图像、音频、视频的理解与生成边界。而创意写作和复杂指令理解的能力突破,恰恰验证了这种原生架构的有效性——它需要的不仅是语言知识,还有对世界知识的跨模态关联和灵活调用的能力。
从这个角度看,LMArena的排名变化,更像是一个清晰的行业风向标。它告诉我们,国产AI的竞争力构建,已经进入了“深水区”。厂商们不再满足于在标准试卷上答题,而是开始挑战更具开放性、更贴近人类真实思维过程的难题。
当我们在榜单上看到国产模型的名字,它代表的不仅是一个评分,更是一种技术路线的验证。文心5.0的这次表现,似乎在向市场传递一个信息:下一阶段的AI竞争,将是“理解力”和“创造力”的竞争。而在这方面提前布局并显现出优势的玩家,或许已经在为未来的应用生态争夺,埋下了重要的伏笔。正式版即将在1月上线,届时,这套在测评中经受考验的“软实力”,能否转化为真正颠覆性的产品体验?这才是留给行业的最大悬念。
百度 文心一言 文心 文心大模型 ai AI大模型 科技 AI技术