[LG]《Training Agents Inside of Scalable World Models》D Hafner, W Yan, T Lillicrap [Google DeepMind] (2025)
Dreamer 4:首个纯离线学习,能在Minecraft中通过想象训练获得钻石的可扩展世界模型智能体。
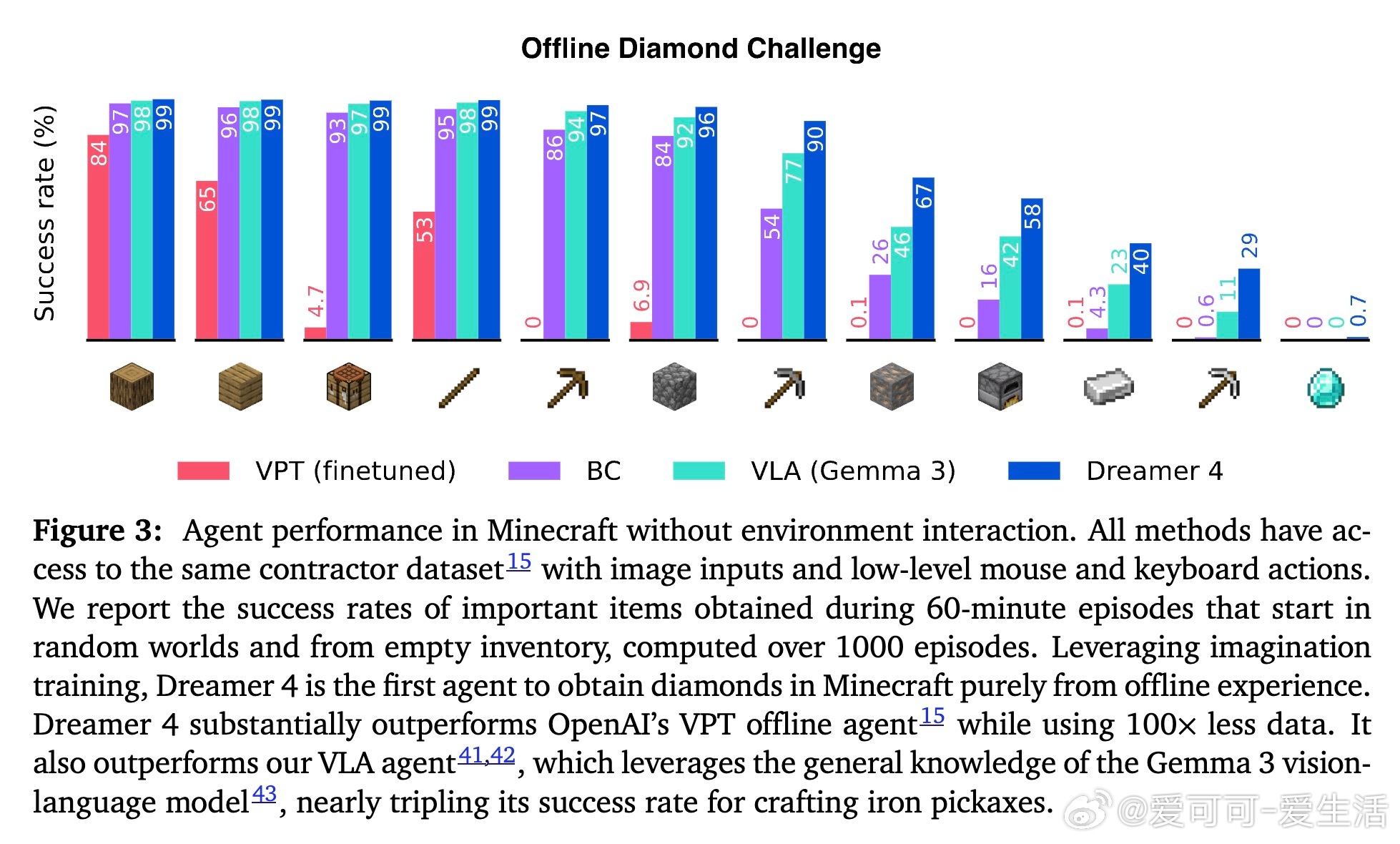
• 纯离线训练:仅用2.5K小时离线数据,无需环境交互,实现从采集木材、打造工具到采钻石的长时序控制任务。
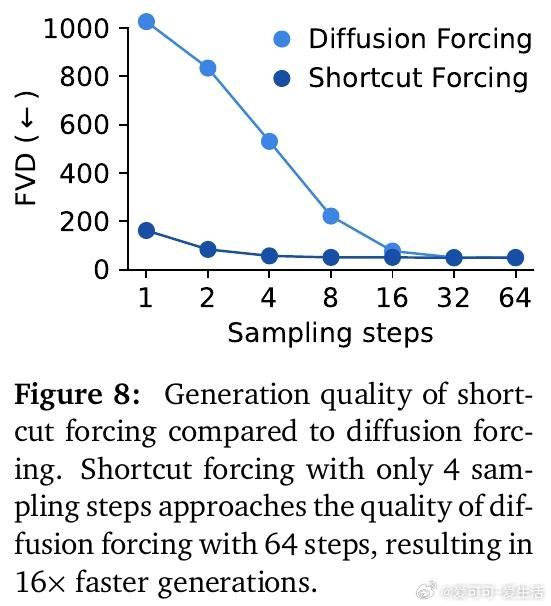
• 高效世界模型:基于快捷强制(shortcut forcing)目标和高效Transformer架构,支持单GPU实时交互推理,预测复杂的物体交互与游戏机制。
• 极少动作标注需求:仅需少量视频带动作数据即可学习动作条件,能从大量未标注视频中吸收大部分世界知识,动作理解可泛化到未见地图维度。
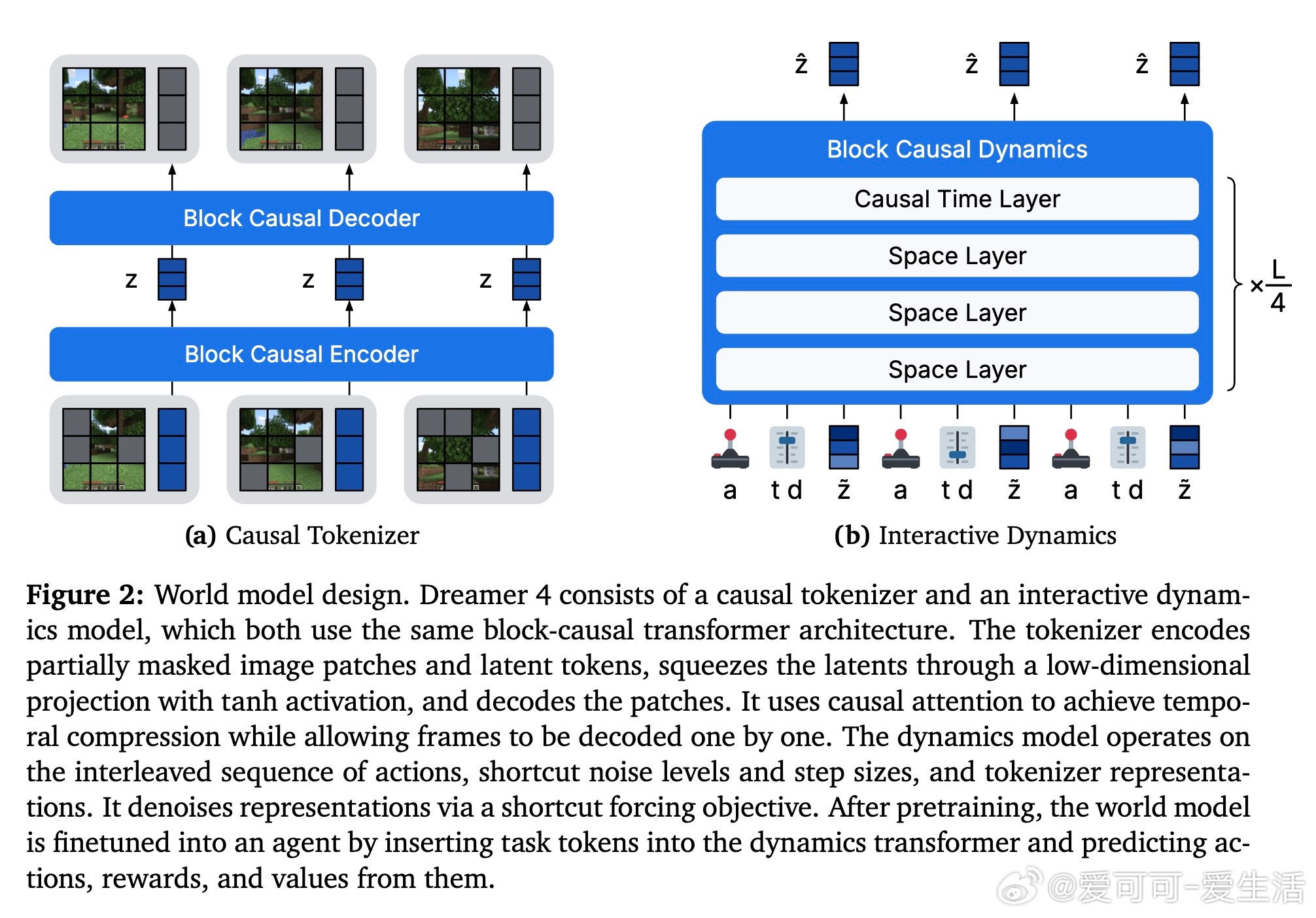
• 多模态因果编码器+动态模型:视频帧编码为连续潜变量,动作与状态交织输入,避免误用因果信息,防止推理错误累积。
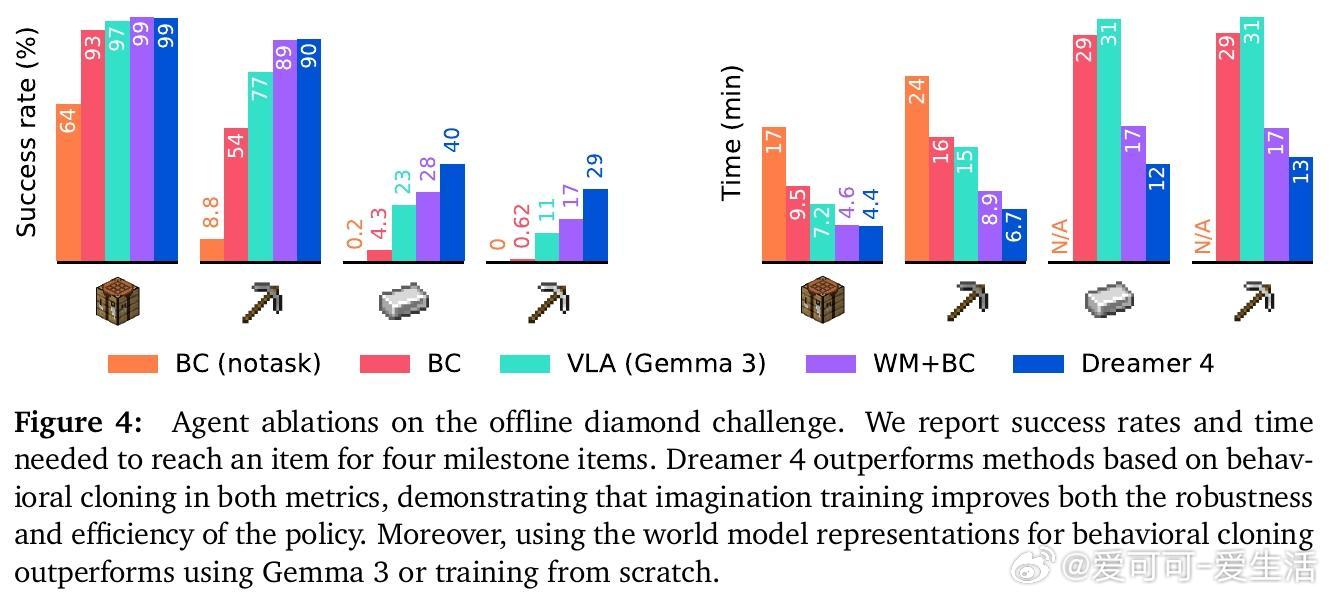
• 想象训练强化策略:先通过行为克隆和奖励建模微调策略,再基于世界模型生成的轨迹进行强化学习,实现高效且稳健的策略提升。
• 任务驱动多任务学习:策略条件于任务嵌入,支持灵活引导实现不同目标,多任务表现优异。
• 超越前代模型:成功率显著超越OpenAI VPT,数据效率提升100倍,预测上下文长度提升6倍,准确模拟大部分Minecraft核心交互。
• 支持人类实时交互:允许玩家在世界模型内操作验证,表现出色,远超现有模型,支持多样复杂操作。
• 设计创新:采用x空间预测降低长序列误差累积,时间空间分离注意力、GQA等多项技术提升训练和推理效率。
• 未来潜力:预示从多样化网络视频中学习通用知识,推动机器人安全离线学习,预备融入语言理解和长期记忆。
心得:
1. 精准且高效的世界模型是实现复杂长时序控制任务离线训练的关键,Dreamer 4用快捷强制目标和高效Transformer架构做到了这一点。
2. 从少量带动作标注到大量未标注视频的泛化能力,说明智能体可借助丰富的无监督视觉数据获得强大的环境理解。
3. 想象训练打通了行为克隆与强化学习的壁垒,实现了策略的高效稳健提升,极大提升了离线智能体的实用性。
论文地址🔗arxiv.org/abs/2509.24527
人工智能强化学习世界模型离线学习智能体MinecraftTransformer视频预测