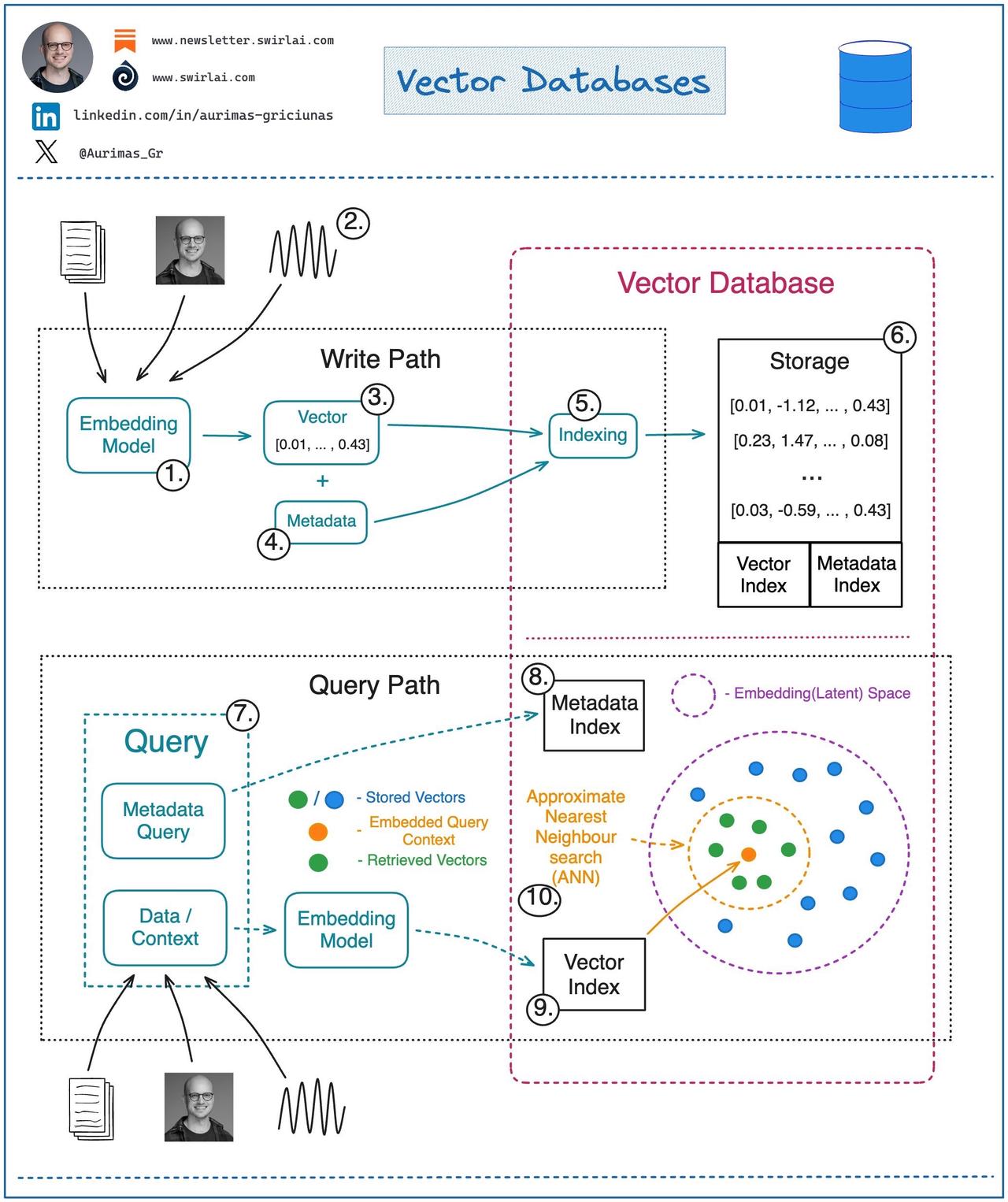
a 𝗩𝗲𝗰𝘁𝗼𝗿 𝗗𝗮𝘁𝗮𝗯𝗮𝘀𝗲的基本原理。 随着 GenAI 的兴起,向量数据库的受欢迎程度飙升。事实上,向量数据库在大型语言模型之外也很有用。 在机器学习中,我们经常处理向量嵌入。向量数据库的创建是为了在使用时表现出色: ➡️存储。 ➡️正在更新。 ➡️检索。 当我们谈论检索时,我们指的是以嵌入到相同潜在空间的向量形式检索与查询最相似的一组向量。此检索过程称为近似最近邻 (ANN) 搜索。 这里的查询可以是像图像这样的对象形式,我们想找到与之相似的图像。或者,查询也可以是一个问题,我们想检索相关的上下文,然后通过 LLM 将其转换为答案。 让我们看一下如何与矢量数据库进行交互: 𝗪𝗿𝗶𝘁𝗶𝗻𝗴 / 𝗨𝗽𝗱𝗮𝘁𝗶𝗻𝗴 𝗗𝗮𝘁𝗮 。 1. 选择一个用于生成向量嵌入的 ML 模型。 2. 嵌入任何类型的信息:文本、图像、音频、表格。用于嵌入的机器学习模型的选择取决于数据类型。 3. 通过嵌入模型运行数据,获取数据的向量表示。 4. 将附加元数据与向量嵌入一起存储。这些数据稍后将用于预过滤或后过滤 ANN 搜索结果。 5. 向量数据库将向量嵌入和元数据分开索引。创建向量索引的方法有很多,例如:随机投影、乘积量化、局部敏感哈希。 6. 矢量数据与矢量嵌入的索引和与嵌入对象相关的元数据一起存储。 𝗥𝗲𝗮𝗱𝗶𝗻𝗴 𝗗𝗮𝘁𝗮 。 7. 针对矢量数据库执行的查询通常由两部分组成: ➡️将用于 ANN 搜索的数据。例如,您想要查找相似图像的图像。 ➡️元数据查询用于排除那些预先已知特定特征的向量。例如,假设您正在寻找相似的公寓图片,则排除特定位置的公寓。 8. 根据元数据索引执行元数据查询。该操作可以在 ANN 搜索过程之前或之后进行。 9. 使用与将数据写入向量数据库相同的模型将数据嵌入到潜在空间中。 10. 应用ANN搜索程序,检索一组向量嵌入。ANN搜索的常用相似度度量包括:余弦相似度、欧氏距离、点积。 你如何使用 Vector DB?请在评论区留言告诉我! LLM AI MachineLearning编程严选网