最近世界模型的热度非常高,周末有空了回过头认真学习了对于世界模型的解读,简单和大家聊聊:
从小鹏MONA M03发布以来,小鹏就逐步采用了轻雷达+纯视觉的方案,因为当时首搭的两款车型M03和P7+价格都很惊喜,大家第一反应一度觉得是“降低成本”。但从技术发展路线上,小鹏认为不采用激光雷达的方案反而是物理世界模型+VLA的最佳组合。
激光雷达方案有两个显著的弊端:第一个是不仅吃算力,还吃时间,激光雷达的感知算力需求比纯视觉高25%,响应时间几乎是纯视觉的2倍。第二个是感知获取的信息程度不够丰富,包括对物体的轮廓、颜色、运动状态等实时信息。
而关于摄像头在远距测算和夜间进度方面的不足,小鹏的解决方法是「Lofic技术」,全称是Lateral OverFlow Integration Capacitor,其基本原理就是在影像传感器的每个光电二极管上都放置一个高密度电容,用来收集原本有可能因为饱和而溢出的光电子。最简单直接的场景就是解决出/入隧道致盲问题。
第二个问题,为什么大家都要做VLA,之前的端到端方案不能再突破了吗?
举个很简单的例子,当车辆前方突然窜出一个行人,LLM可能需要先“理解”行人动作(文本化描述),再“生成”刹车指令,这个过程即使做到1秒内的延迟,车辆在60km/h时速下已滑行16米,就已经错过了最佳制动时机。
而VLA则能直接通过视觉模型实时捕捉行人位置,结合车辆动力学模型,在100毫秒内输出刹车+转向的组合控制,将刹车距离缩短至安全范围。
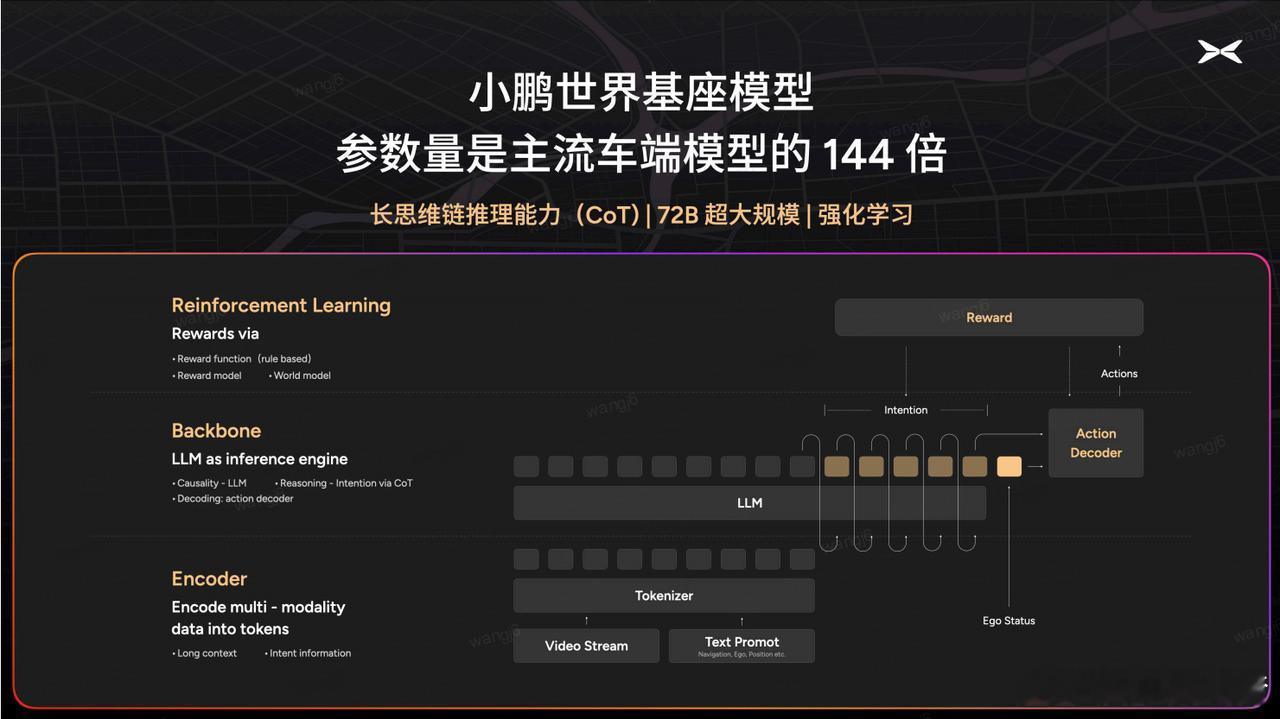
两者的核心差异就在于:VLA是为「实时控制」设计的「专用大脑」,而LLM是为「语言交互」设计的「通用大脑」。而且LLM对算力储备的要求极大,传统车端芯片往往难以支持大参数量的实时运算(这也是为什么小鹏要自研芯片的其中一个原因)。目前行业主流VLA模型参数通常在20亿级,而小鹏直接把物理世界基座模型干到720亿参数,再蒸馏出更小尺寸的小模型上,部署在车端上,让小模型有更强的“速战速决”的能力。
这就相当于将清华教授的知识浓缩成便携手册,让普通学生也能掌握解题精髓。举个例子,前几个月很火的香港右舵车场景,小鹏模型不用本地数据就能直接适配,而传统方案可能得重新训练几个月。
而且蒸馏出来的小模型必须放在车端,更准确的来说,所有跟控车相关的VLA都必须放在车端。云端就意味着需要网络响应,遇到地库没信号、高速网络差,云端反应慢0.3秒就可能导致车祸。真正的"老司机"必须随身带大脑:车端VLA就像你打游戏时电脑自带的显卡,关键时刻绝不掉链子。
诚然,VLA在国内都是属于起步阶段,远没有LLM语言模型来的更加成熟,但是VLA确实是各家都在“生长开花”的状态。包括特斯拉的FSd、理想的MindVLA、小鹏的XVLA、还是蔚来的NWM,每家都走在了全球智驾路线的前沿,技术上的整体领先会是第一前提,剩下的才是体验上的差异化。但在辅助驾驶的范围内,绝对够用了,接下来就是“更像人驾”上的优化。
而小鹏是国内几家里面唯一没有采用激光雷达方案的新势力车企,站在全球智驾技术竞争中,小鹏的坚持说不定会成为打破同质化的关键一步,这种角色的价值,远要比商业价值更加强大。
小鹏汽车小鹏汽车[超话]大v聊车