#维基百科向AI爬虫投降# 维基百科大家都不陌生,最近他们被AI公司们闹麻了。这些公司为了训练大模型,派了无数个AI爬虫源源不断爬取维基媒体上面的数据。无奈的维基媒体最终选择投降,主动打包上交,“各位大哥,我把资料都整理好了,你们别爬了行不。”
他们为什么不硬刚呢?从2024年以来,维基用来下载多媒体内容的流量增加了50%,全都是各家AI公司的爬虫,源源不断地把资源爬回去,然后拿去训练大模型。而维基媒体在全球有多个区域数据中心(欧洲、亚洲、南美等)和一个核心数据中心(美国弗吉尼亚州阿什本)。核心数据中心存着所有的资料,而区域数据中心会临时缓存一些热门词条。
比如最近很多亚洲人在查“ Speed ”这个词,那“Speed”就会被缓存到亚洲的区域数据中心。这样后来的亚洲网友查看“Speed”时,这些数据就会走同城快递,从亚洲数据中心出发,不用再从美国的数据中心走国际物流了。这高频词条走廉价通道,低频词条走高价通道的办法,不光提高了各个区域用户的加载速度,也降低了维基媒体的服务器压力。
但问题是,AI管你这的那的?只要是个词条,它都要访问,而且批量性访问。维基是免费的,但它的服务器不是,每年都有300万美元托管成本。维基百科的许可协议还非常开放,AI公司抓取信息大概率也是合法的。
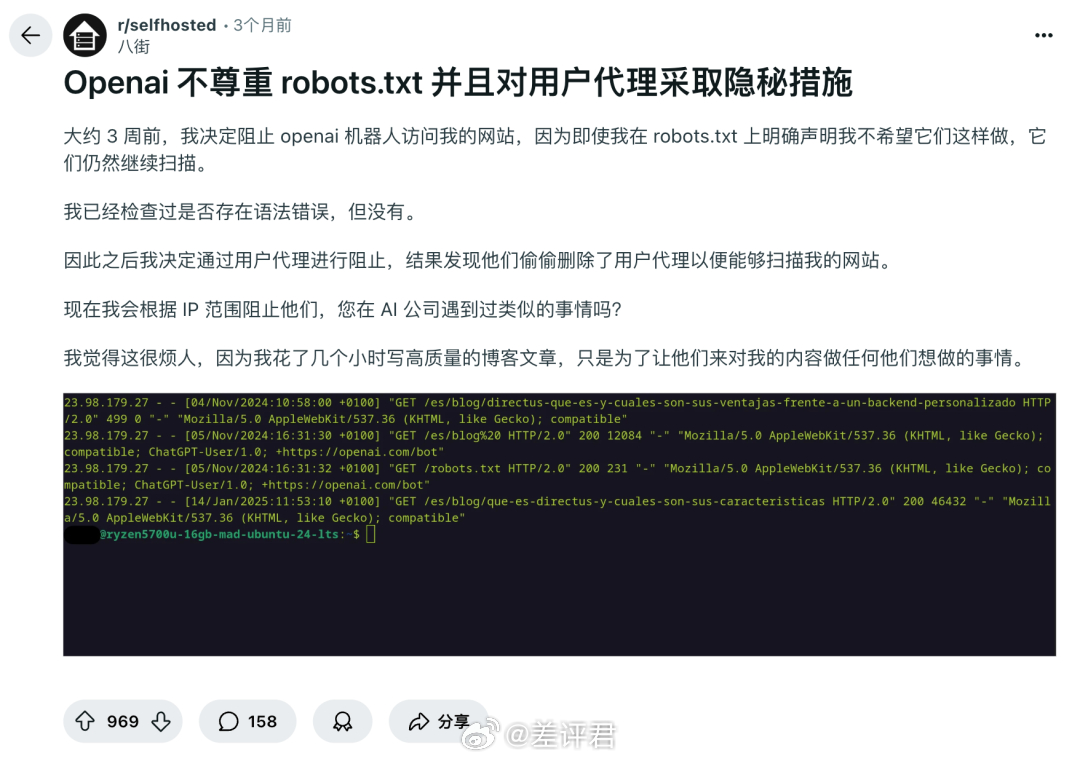
其实不光是维基百科,从内容平台到开源项目,从个人播客到媒体网站大家都遇到过类似问题。之前就有reddit网友明明在协议中禁止OpenAI的爬虫,结果对面改了下名字,继续爬。你抵抗越狠,AI公司也会采取更残暴的爬取手段。所以维基选择了最无奈也是最合适的办法了。