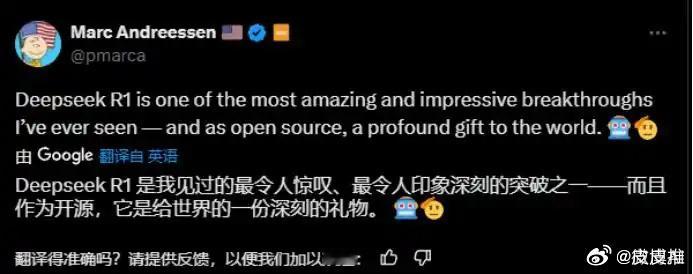
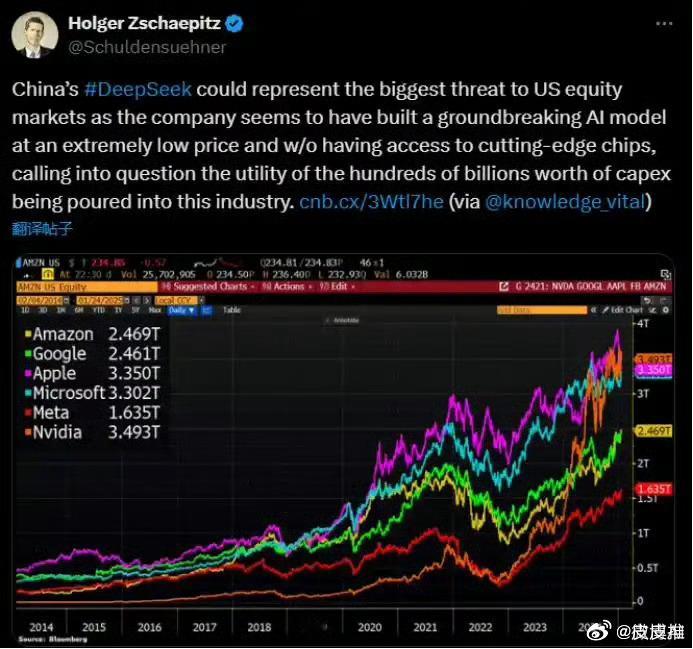
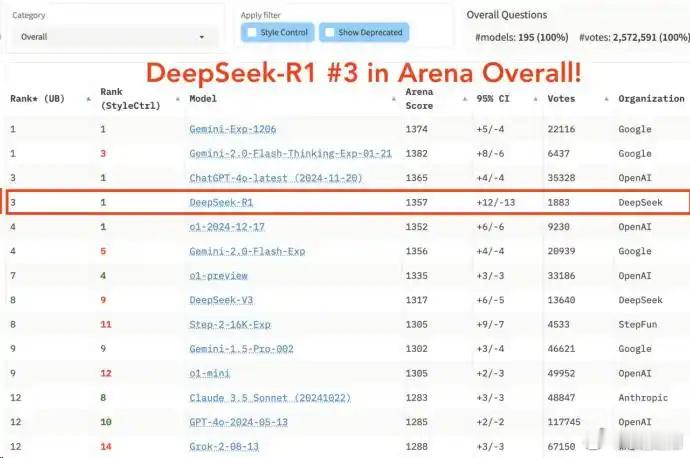
DeepSeek为何一夜爆火 说真的,这是我第一次听说DeepSeek这款大模型,它现在国外比国内知名度更高。
看了相关报道,有人说DeepSeek大模型是价格颠覆者,它与其它大模型不同点在于它是和知名量化私募幻方量化有关,而其它大模型无一例外的都是来自互联网科技公司。
曾是OpenAI创始成员之一的AI科学家Andrej Karpathy评价称:“今天,一家中国AI公司轻而易举地发布了一个前沿大语言模型,其仅使用2048块GPU训练了2个月,只花费了近600万美元。
作为参考,这种级别的能力本应该需要接近1.6万块的GPU集群,而目前正在部署的集群包含的GPU数量却接近10万块。例如,Llama 3405B模型使用了3080万GPU/小时,而DeepSeek-V3模型看起来更加强大,却仅使用了280万GPU/小时(计算量减少了约11倍)。
如果此模型还能通过各项评估,那么这将是资源受限条件下研究与工程能力的高度令人印象深刻的展示。”